Performance Metrics for Human-Agent Teams
Imagine your finance team starts using an agent to help with the monthly close process. The agent pulls data from the ERP, drafts commentary, and prepares evidence for each account. Suddenly, the controllership team has more time. The questions that arise are no longer "how many hours were saved?" but rather "did the quality of the close actually improve?" or "did the agent help the team find anomalies that were previously missed?"
These kinds of questions are emerging in many companies. After piloting agentic AI across several functions—whether finance close, procurement intake, customer operations, or IT incident triage—management begins to realize that old metrics are no longer sufficient. Productivity per FTE, utilization, transaction volume, and basic SLAs are still useful, but they don't capture what's really happening when humans and agents work together.
The problem is, without the right metrics, companies easily fall into two illusions. The first is the demo effect: the system looks sophisticated, responds quickly, and has a convincing interface, but its operational impact is small. The second is automation vanity: the company takes pride in the number of tasks "automated," while costs, risks, or the burden of human review actually increase.
Why Old Metrics Are No Longer Enough
Traditional metrics were born from a relatively clear operating model: humans perform tasks, systems support them, and output is measured by volume, time, and cost. In that model, FTE utilization, throughput, backlog, and SLAs were fairly representative. But when agents start taking over parts of the work—reading context, calling tools, preparing drafts, routing cases, executing limited actions, and escalating to humans only when necessary—the structure of work changes fundamentally.
A single business outcome is no longer produced by one type of labor. It is produced by a combination of digital labor, human oversight, workflow orchestration, data quality, and operational guardrails. If a company continues to use old metrics in isolation, several distortions will emerge.
Take finance close as an example. Controllership team utilization might drop because the agent takes over evidence gathering and draft commentary. Viewed through the old lens, this looks like "idle human capacity." But what's actually happening is that human capacity is shifting to material review, root-cause analysis, and business partnering. A decrease in manual activity doesn't always mean a decrease in value. Sometimes it's a sign that the operating model is improving.
In customer operations, an agent might increase the number of tickets processed per day. But if many cases require supervisor correction, or if customers have to follow up because the issue wasn't truly resolved, high throughput is misleading. In shared services, an agent can respond quickly to almost any request. But if that response is just an acknowledgment or a generic answer, SLAs look green while resolution quality is poor. In procurement or IT operations, an agent might reduce level-1 workload. But if unauthorized tool calls, policy deviations, or routing errors increase, the costs "saved" could be paid back many times over down the line.
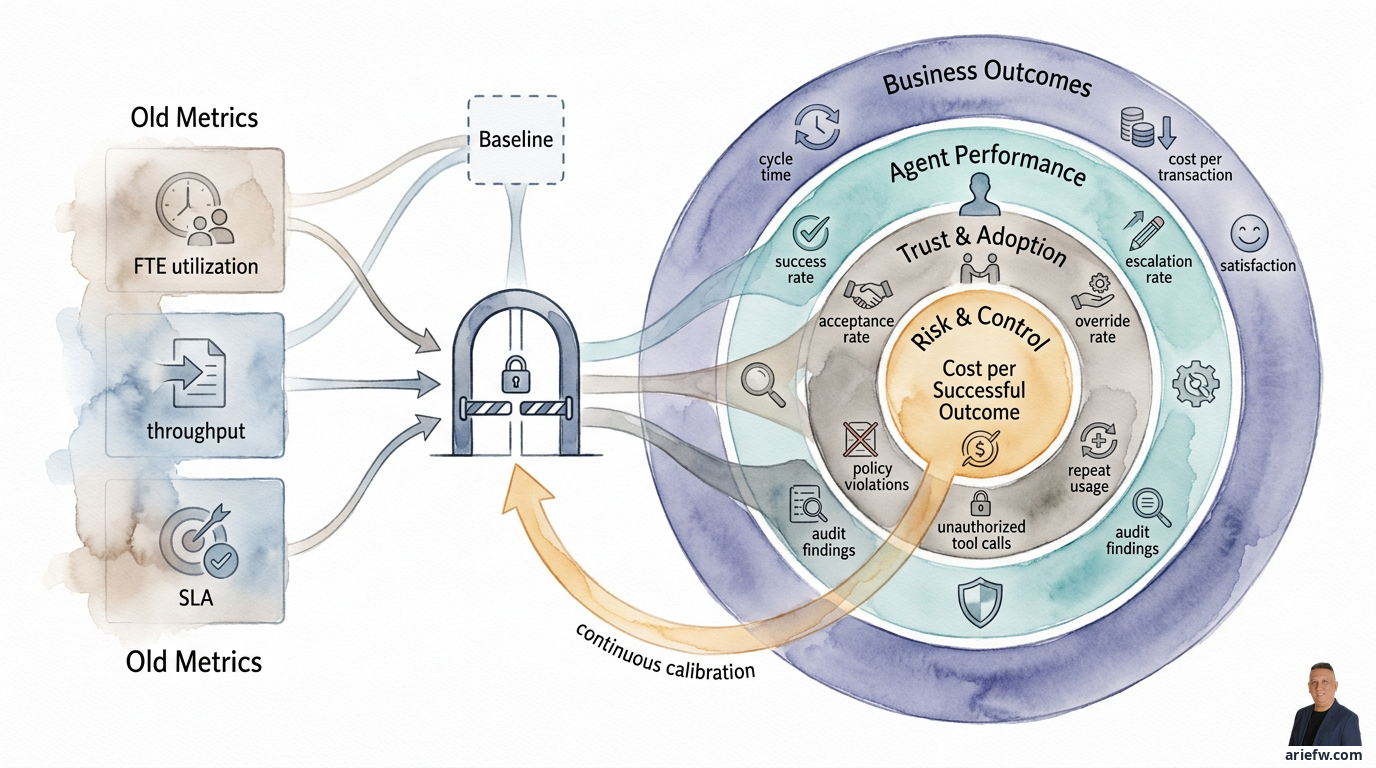
Therefore, companies need to add new measurement dimensions. At a minimum, five should be included in the scorecard: business outcomes, autonomy level, exceptions and escalations, trust and adoption, and control effectiveness. Without these, it's difficult to distinguish an agentic AI pilot from an interesting experiment versus a capability truly worth scaling.
Business Metrics: Start with Outcomes, Not Activities
The first layer must still be business. The agent is not the goal. The agent is a new way to produce outcomes. Therefore, the primary metrics must still answer: did the business process improve after the agent was implemented?
Some of the most relevant metrics typically include cycle time, cost per transaction or cost per case, throughput, SLA achievement, customer satisfaction or internal user satisfaction, and revenue leakage or loss avoidance for specific use cases. Each domain has a slightly different focus.
In finance close, measure close time, exception resolution time, number of accounts reviewed late, draft commentary quality, and the backlog of issues carried into the next period. If the close agent only speeds up drafting but doesn't reduce the review bottleneck, its business value is still limited.
In procurement operations, measure cycle time from intake to PO, the percentage of requests entering the correct path from the start, rework rate, compliance with sourcing policy, and internal requester satisfaction. An agent that is fast but frequently misclassifies will increase the buyer's workload, not reduce it.
In customer operations, measure first-contact resolution, average resolution time, repeat contact rate, customer satisfaction, and the value of unnecessary refunds or concessions. In IT operations, measure mean time to triage, mean time to resolve, incident backlog, change failure impact, and the quality of handoffs from agent to engineer. In supply chain, measure exception resolution time, service level, inventory availability, expedite cost, and impact on order fulfillment.
One discipline that is often overlooked is establishing a baseline before implementation. Many teams launch an agent and then compare results to perception, not to an actual baseline. Without a baseline, a company cannot answer whether cycle time truly improved, whether cost per outcome decreased, or whether improvements actually came from other factors like policy changes, data improvements, or manual process redesign. At a minimum, before an agent goes live, a company needs to document current case volume, resolution time, error or rework rate, operational cost, and outcome quality.
Companies also need to be careful with value attribution. Not all improvements after agent implementation come from the agent. Procurement cycle time might drop because the approval matrix was simplified, not solely because of the agent intake. Close quality might improve because data mapping was fixed. Customer satisfaction might rise because the knowledge base was cleaned up. This isn't a problem—in fact, value often comes from a combination of process redesign, data cleanup, and the agent. But companies must be honest about value attribution. If all improvements are claimed as AI results, the business case will be fragile and governance will lose credibility.
Agent Performance Metrics: Measuring the Quality of Digital Labor
After business outcomes, the second layer is the agent's own performance. This is important because a good business metric doesn't necessarily mean the agent is healthy. Business results could improve while compute costs skyrocket, correction rates are high, or supervisors silently bear a heavy burden.
Several core metrics need to be monitored: success rate, escalation rate, tool failure rate, correction rate, hallucination rate, and confidence calibration.
Success rate is not just "the agent gave an answer." Define success as an outcome completed according to its goal without needing material correction. In a service desk, success means the request was completed correctly, not just that the ticket was closed. In finance, success means the draft or recommendation can be used by the reviewer with minimal correction. In procurement, success means the request was routed correctly and didn't trigger rework.
Escalation rate shows how many cases must be handed up to a human. This is an important metric, but it must be read in context. Too high means the agent is too conservative or not yet mature enough. Too low means the agent might be too aggressive and risks bypassing cases that should be escalated. The target isn't always "as low as possible," but rather aligned with the risk tier and workflow design.
Many agent failures are not due to reasoning, but to integration: API failures, unavailable data, incorrect permissions, or tool timeouts. If tool failure is high, the problem lies in the architecture and platform, not solely the model.
The correction rate is one of the most honest metrics. How often must a human correct the agent's output? This metric is very useful for finance draft commentary, customer response recommendations, procurement intake classification, incident triage, or supply chain exception summaries. If the correction rate is high, phantom productivity is occurring: the agent appears active, but humans are still redoing the work.
For workflows involving reasoning based on documents, knowledge, or enterprise data, companies need to track how often the agent cites non-existent policies, infers facts unsupported by evidence, or gives confident but incorrect answers. Not all organizations can measure hallucination rate perfectly, but sampling reviews and case audits can provide early indicators.
Confidence calibration is also important. A good agent is not only often correct, but also knows when it is uncertain. If high confidence appears precisely in cases that are frequently wrong, calibration is poor. This is dangerous because users will be more easily fooled by output that sounds definitive.
If a company uses an orchestrator and multiple task agents, add two important metrics: handoff quality—whether context is transferred correctly between agents or to a human—and orchestration failure—how often the workflow fails due to incorrect step sequences, dependencies, or routing. In IT delivery, for example, a requirements agent, coding agent, QA agent, and reviewer agent might each perform well individually, but the overall workflow can still fail if handoffs are poor.
Finally, don't forget cost per successful outcome. Tokens, compute, retrieval, and tool invocations can quietly increase as scale grows. Therefore, don't just measure cost per run or cost per prompt. Measure cost per successful outcome. This helps answer more strategic questions: is the agent truly more economical than the old operating model, is the additional autonomy worth the cost, and are there use cases that are technically successful but economically unhealthy?
Trust and Risk Metrics: Because Adoption Without Trust Won't Last
Human-agent teams will not be stable if users don't trust the system, or if the risk function feels its controls are unclear. Therefore, companies need to measure two things simultaneously: trust and risk.
For trust, some of the most useful indicators are user acceptance rate, override rate, explanation usefulness, and repeat usage. User acceptance rate shows how often users accept the agent's recommendations or output without needing a complete replacement. Override rate shows how often humans reject or change the agent's decision. A high override rate could mean low quality, low trust, or misaligned policy. But a zero override rate is not automatically good—it could mean users are passive or not sufficiently critical.
Explanation usefulness measures whether the agent's explanation helps users understand the reasoning behind a recommendation. In domains like finance, procurement, and IT operations, a useful explanation is often more important than a quick answer. Without it, trust is hard to build. Repeat usage is a simple but powerful indicator: do users come back to use the agent when not required? If people only use the agent because they are told to, adoption is still shallow.
For risk, this layer must be read together with risk, compliance, security, and internal audit. Some core metrics include policy violations, data exposure incidents, unauthorized tool calls, and audit findings. Policy violations could be the agent giving recommendations outside its delegated authority, violating approval thresholds, or routing cases to paths not aligned with policy. Data exposure incidents measure whether the agent displayed data that a particular user or tool should not have accessed—this is critical for workflows touching ERP, HRIS, CRM, or customer data.
Unauthorized tool calls measure whether the agent attempted or succeeded in calling tools it was not permitted to use. This metric is especially important for agents connected to transaction systems or workflow execution. Audit findings are the results of internal audits or compliance reviews of agent operations. If the audit trail is weak, evidence is incomplete, or approval paths are unclear, scaling must be paused even if business metrics look good.
Combined Scorecard: Value, Quality, Risk, Adoption
Ultimately, a company needs a single scorecard that is not one-sided. A simple structure could include five dimensions. Value is measured by cycle time, cost per transaction, throughput, SLA, and customer or internal satisfaction. Quality is measured by success rate, correction rate, hallucination rate, and handoff quality. Adoption and Trust are measured by acceptance rate, override rate, repeat usage, and explanation usefulness. Risk and Control are measured by policy violations, unauthorized tool calls, data exposure incidents, and audit findings. Efficiency of Digital Labor is measured by cost per successful outcome, tool failure rate, and escalation rate.
A scorecard like this helps executives avoid two mistakes: only looking at value without seeing risk, or being so focused on risk that they never measure actual outcomes.
Practical Implications
After understanding this framework, there are several decisions that need to be made now. First, determine the primary unit of measurement. Will you measure per task, per case, per transaction, or per successful outcome? For human-agent teams, the last measure is usually the most useful. Second, agree on a baseline before scaling. Do not launch an agent without comparative data on cycle time, cost, quality, and exception rate.
Third, build a cross-functional scorecard. The CIO, COO, risk, and process owners must agree on a combination of value, quality, adoption, and risk metrics—not each use their own dashboard. Fourth, define who owns each metric. The business owner holds the business outcomes, the platform team holds reliability and cost, the supervisor holds correction and escalation patterns, and the risk owner holds control metrics. Fifth, determine thresholds for scaling, pausing, or rolling back. For example, when is the correction rate too high, when does a policy violation require a use case to be put on hold, or when is the cost per successful outcome no longer reasonable?
Several danger signals need to be watched for. If success is still measured primarily by the amount of automation or reduction in working hours, if there is no credible baseline before implementation, if the business, IT, and risk teams use different definitions of "success," if override and correction rates are high but not on the improvement backlog, if token and compute costs rise but are not linked to outcomes, if the audit trail is insufficient to explain why the agent took a certain action, if users use the agent because they are required to rather than because it helps their work, or if policy violations are dismissed as "small noise" as long as business metrics look good—then this topic is not yet ready to scale.
A reflective question for CIOs, COOs, CHROs, and transformation leaders: If tomorrow you were asked to prove that your company's human-agent team is truly creating value, could you only show a demo and usage rates—or could you already present a balanced scorecard of outcomes, quality, adoption, cost, and control? That is the difference between an interesting AI experiment and an agentic operating model ready to scale.