Performance Metrics untuk Human-Agent Teams
Bayangkan tim finance Anda mulai menggunakan agent untuk membantu proses close bulanan. Agent mengambil data dari ERP, menyusun draft commentary, dan menyiapkan evidence untuk setiap akun. Tim controllership tiba-tiba memiliki lebih banyak waktu. Pertanyaan yang muncul bukan lagi "berapa jam kerja yang dihemat?", tetapi "apakah kualitas close benar-benar membaik?" atau "apakah agent membantu tim menemukan anomaly yang sebelumnya terlewat?"
Pertanyaan semacam ini mulai muncul di banyak perusahaan. Setelah pilot agentic AI berjalan di beberapa fungsi—entah itu finance close, procurement intake, customer operations, atau IT incident triage—manajemen mulai sadar bahwa metrik lama tidak lagi cukup. Produktivitas per FTE, utilization, volume transaksi, dan SLA dasar masih berguna, tetapi tidak menangkap apa yang sebenarnya terjadi ketika manusia dan agent bekerja bersama.
Masalahnya, tanpa metrik yang tepat, perusahaan mudah terjebak dalam dua ilusi. Ilusi pertama adalah demo effect: sistem terlihat canggih, respons cepat, dan antarmuka meyakinkan, tetapi dampak operasionalnya kecil. Ilusi kedua adalah automation vanity: perusahaan bangga pada jumlah task yang "diotomasi", padahal biaya, risiko, atau beban review manusia justru naik.
Mengapa Metrik Lama Tidak Lagi Cukup
Metrik tradisional lahir dari model operasi yang relatif jelas: manusia mengerjakan tugas, sistem mendukung, dan output diukur dari volume, waktu, dan biaya. Dalam model itu, FTE utilization, throughput, backlog, dan SLA cukup representatif. Namun ketika agent mulai mengambil alih sebagian pekerjaan—membaca konteks, memanggil tool, menyiapkan draft, merutekan kasus, menjalankan tindakan terbatas, dan mengeskalasi ke manusia hanya saat perlu—struktur kerja berubah secara mendasar.
Satu outcome bisnis tidak lagi dihasilkan oleh satu jenis tenaga kerja. Ia dihasilkan oleh kombinasi digital labor, human oversight, workflow orchestration, data quality, dan guardrail operasional. Jika perusahaan tetap memakai metrik lama secara tunggal, beberapa distorsi akan muncul.
Ambil contoh di finance close. Utilization tim controllership bisa turun karena agent mengambil alih evidence gathering dan draft commentary. Jika dilihat dengan kacamata lama, ini tampak seperti "kapasitas manusia menganggur". Padahal yang sebenarnya terjadi adalah kapasitas manusia berpindah ke review material, root-cause analysis, dan business partnering. Penurunan aktivitas manual tidak selalu berarti penurunan nilai. Kadang justru itu tanda bahwa operating model membaik.
Di customer operations, agent mungkin meningkatkan jumlah tiket yang diproses per hari. Tetapi jika banyak kasus harus dikoreksi supervisor, atau pelanggan harus menghubungi ulang karena masalah belum benar-benar selesai, throughput tinggi justru menyesatkan. Di shared services, agent dapat merespons cepat hampir semua request. Namun jika respons itu hanya acknowledgment atau jawaban generik, SLA tampak hijau sementara resolution quality buruk. Di procurement atau IT operations, agent mungkin mengurangi beban kerja level-1. Tetapi jika unauthorized tool call, policy deviation, atau kesalahan routing meningkat, biaya yang "dihemat" bisa dibayar mahal di belakang.
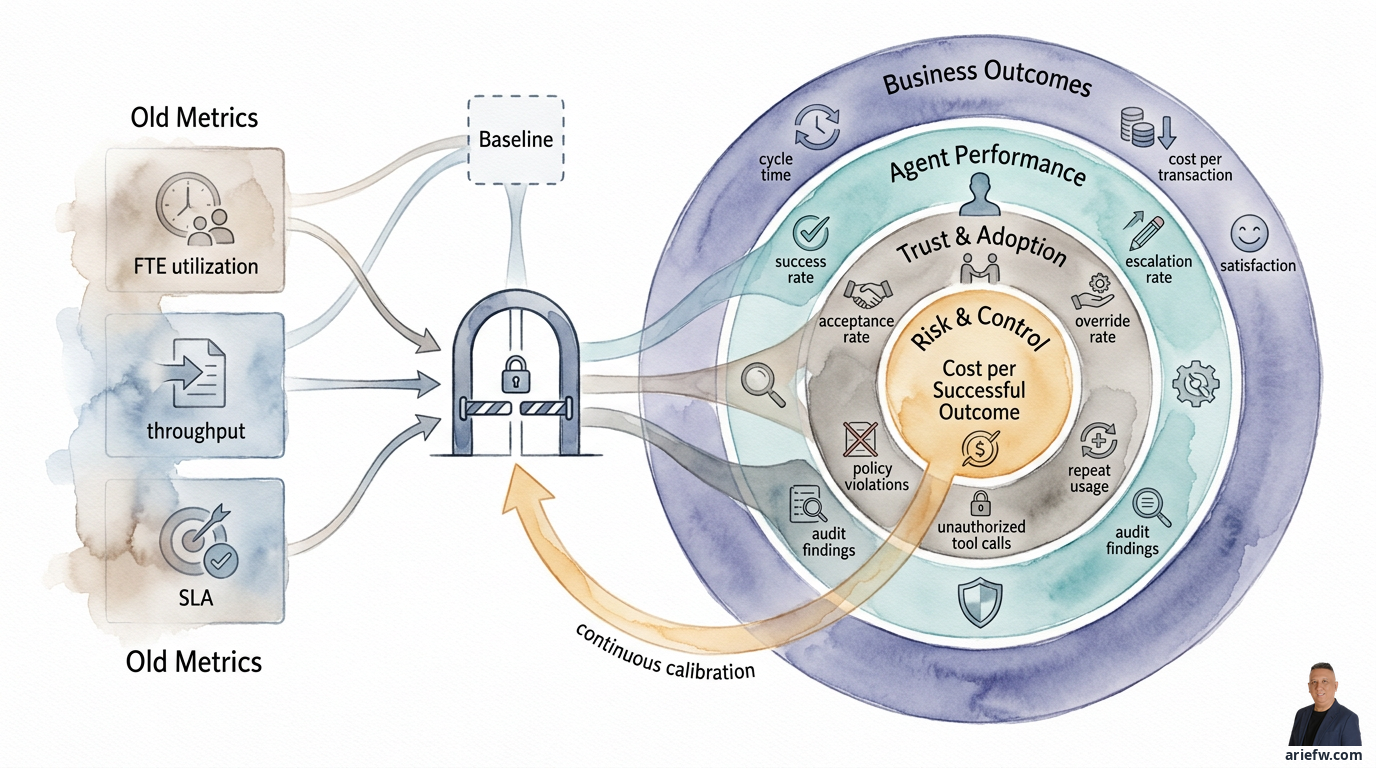
Karena itu, perusahaan perlu menambah dimensi pengukuran baru. Minimal ada lima yang harus masuk ke scorecard: outcome bisnis, tingkat otonomi, exception dan escalation, trust dan adopsi, serta efektivitas kontrol. Tanpa itu, pilot agentic AI sulit dibedakan antara eksperimen menarik dan kapabilitas yang benar-benar layak di-scale.
Business Metrics: Mulai dari Outcome, Bukan Aktivitas
Lapisan pertama tetap harus bisnis. Agent bukan tujuan. Agent adalah cara baru untuk menghasilkan outcome. Karena itu, metrik utama harus tetap menjawab: apakah proses bisnis membaik setelah agent diterapkan?
Beberapa metrik yang paling relevan biasanya meliputi cycle time, cost per transaction atau cost per case, throughput, SLA achievement, customer satisfaction atau internal user satisfaction, serta revenue leakage atau loss avoidance untuk use case tertentu. Masing-masing domain memiliki fokus yang sedikit berbeda.
Di finance close, ukur waktu close, waktu penyelesaian exception, jumlah akun yang terlambat direview, kualitas draft commentary, dan backlog issue yang terbawa ke periode berikutnya. Jika close agent hanya mempercepat drafting tetapi tidak mengurangi bottleneck review, maka nilai bisnisnya masih terbatas.
Di procurement operations, ukur cycle time dari intake ke PO, persentase request yang masuk jalur yang benar sejak awal, rework rate, kepatuhan terhadap policy sourcing, dan kepuasan requester internal. Agent yang cepat tetapi sering salah klasifikasi akan menambah beban buyer, bukan mengurangi.
Di customer operations, ukur first-contact resolution, average resolution time, repeat contact rate, customer satisfaction, dan nilai refund atau concession yang tidak perlu. Di IT operations, ukur mean time to triage, mean time to resolve, incident backlog, change failure impact, dan kualitas handoff dari agent ke engineer. Di supply chain, ukur exception resolution time, service level, inventory availability, expedite cost, dan dampak terhadap order fulfillment.
Satu disiplin yang sering diabaikan adalah baseline sebelum implementasi. Banyak tim langsung meluncurkan agent lalu membandingkan hasilnya dengan persepsi, bukan baseline nyata. Padahal tanpa baseline, perusahaan tidak bisa menjawab apakah cycle time benar-benar membaik, apakah biaya per outcome turun, atau apakah perbaikan sebenarnya berasal dari faktor lain seperti perubahan policy, perbaikan data, atau redesign proses manual. Minimal, sebelum agent live, perusahaan perlu mendokumentasikan volume kasus, waktu penyelesaian, error atau rework rate, biaya operasional, dan kualitas outcome saat ini.
Perusahaan juga perlu hati-hati dengan value attribution. Tidak semua perbaikan setelah implementasi agent berasal dari agent. Cycle time procurement bisa turun karena approval matrix disederhanakan, bukan semata karena agent intake. Kualitas close bisa membaik karena data mapping diperbaiki. Customer satisfaction bisa naik karena knowledge base dibersihkan. Ini bukan masalah—justru sering kali nilai datang dari kombinasi redesign proses, data cleanup, dan agent. Tetapi perusahaan harus jujur dalam value attribution. Jika semua perbaikan diklaim sebagai hasil AI, business case akan rapuh dan governance kehilangan kredibilitas.
Agent Performance Metrics: Mengukur Kualitas Digital Labor
Setelah outcome bisnis, lapisan kedua adalah kinerja agent itu sendiri. Ini penting karena business metric yang baik belum tentu berarti agent sehat. Bisa saja hasil bisnis membaik sementara biaya komputasi melonjak, correction rate tinggi, atau supervisor diam-diam menanggung beban besar.
Beberapa metrik inti yang perlu dipantau adalah success rate, escalation rate, tool failure rate, correction rate, hallucination rate, dan confidence calibration.
Success rate bukan sekadar "agent memberi jawaban". Definisikan success sebagai outcome yang selesai sesuai tujuan dan tidak perlu koreksi material. Di service desk, success berarti request selesai benar, bukan hanya tiket ditutup. Di finance, success berarti draft atau rekomendasi dapat dipakai reviewer dengan koreksi minimal. Di procurement, success berarti request dirutekan benar dan tidak memicu rework.
Escalation rate menunjukkan berapa banyak kasus yang harus naik ke manusia. Ini metrik penting, tetapi harus dibaca dengan konteks. Terlalu tinggi berarti agent terlalu konservatif atau belum cukup matang. Terlalu rendah berarti agent mungkin terlalu agresif dan berisiko melewati kasus yang seharusnya dieskalasi. Targetnya bukan selalu "serendah mungkin", melainkan sesuai risk tier dan desain workflow.
Banyak kegagalan agent bukan karena reasoning, tetapi karena integrasi: API gagal, data tidak tersedia, permission salah, atau tool timeout. Jika tool failure tinggi, masalahnya ada pada arsitektur dan platform, bukan semata model.
Correction rate adalah salah satu metrik paling jujur. Berapa sering manusia harus memperbaiki output agent? Metrik ini sangat berguna di draft commentary finance, rekomendasi respons customer, klasifikasi procurement intake, incident triage, atau ringkasan exception supply chain. Jika correction rate tinggi, produktivitas semu sedang terjadi: agent tampak aktif, tetapi manusia tetap mengulang pekerjaan.
Untuk workflow yang melibatkan reasoning berbasis dokumen, knowledge, atau data enterprise, perusahaan perlu melacak seberapa sering agent mengutip policy yang tidak ada, menyimpulkan fakta yang tidak didukung evidence, atau memberi jawaban meyakinkan tetapi salah. Tidak semua organisasi bisa mengukur hallucination rate secara sempurna, tetapi sampling review dan audit kasus bisa memberi indikator awal.
Confidence calibration juga penting. Agent yang baik bukan hanya sering benar, tetapi juga tahu kapan ia tidak yakin. Jika confidence tinggi justru muncul pada kasus yang sering salah, calibration buruk. Ini berbahaya karena pengguna akan lebih mudah tertipu oleh output yang terdengar pasti.
Jika perusahaan memakai orchestrator dan beberapa task agent, tambahkan dua metrik penting: handoff quality—apakah konteks berpindah dengan benar antar-agent atau ke manusia—dan orchestration failure—berapa sering workflow gagal karena urutan langkah, dependency, atau routing yang salah. Dalam IT delivery, misalnya, requirement agent, coding agent, QA agent, dan reviewer agent bisa masing-masing tampak baik, tetapi keseluruhan workflow tetap gagal jika handoff buruk.
Terakhir, jangan lupakan cost per successful outcome. Token, compute, retrieval, dan tool invocation bisa naik diam-diam seiring skala naik. Karena itu, jangan hanya ukur cost per run atau cost per prompt. Ukur cost per successful outcome. Ini membantu menjawab pertanyaan yang lebih strategis: apakah agent benar-benar lebih ekonomis daripada model kerja lama, apakah otonomi tambahan sepadan dengan biaya, dan apakah ada use case yang secara teknis berhasil tetapi secara ekonomi tidak sehat.
Trust dan Risk Metrics: Karena Adopsi Tanpa Kepercayaan Tidak Akan Bertahan
Human-agent teams tidak akan stabil jika pengguna tidak percaya pada sistem, atau jika risk function merasa kontrolnya kabur. Karena itu, perusahaan perlu mengukur dua hal sekaligus: trust dan risk.
Untuk trust, beberapa indikator yang paling berguna adalah user acceptance rate, override rate, explanation usefulness, dan repeat usage. User acceptance rate menunjukkan berapa sering pengguna menerima rekomendasi atau output agent tanpa perlu mengganti total. Override rate menunjukkan berapa sering manusia menolak atau mengganti keputusan agent. Override rate tinggi bisa berarti kualitas rendah, trust rendah, atau policy yang belum selaras. Tetapi override rate nol juga tidak otomatis baik—bisa jadi pengguna pasif atau tidak cukup kritis.
Explanation usefulness mengukur apakah penjelasan agent membantu pengguna memahami alasan di balik rekomendasi. Di domain seperti finance, procurement, dan IT operations, explanation yang berguna sering lebih penting daripada jawaban cepat. Tanpa itu, trust sulit tumbuh. Repeat usage adalah indikator sederhana tetapi kuat: apakah pengguna kembali memakai agent ketika tidak diwajibkan? Jika orang hanya memakai agent karena diminta, adopsi masih dangkal.
Untuk risk, lapisan ini harus dibaca bersama risk, compliance, security, dan audit internal. Beberapa metrik inti meliputi policy violations, data exposure incidents, unauthorized tool calls, dan audit findings. Policy violations bisa berupa agent memberi rekomendasi di luar delegated authority, melanggar threshold approval, atau merutekan kasus ke jalur yang tidak sesuai policy. Data exposure incidents mengukur apakah agent menampilkan data yang tidak seharusnya diakses pengguna atau tool tertentu—ini sangat penting untuk workflow yang menyentuh ERP, HRIS, CRM, atau data pelanggan.
Unauthorized tool calls mengukur apakah agent mencoba atau berhasil memanggil tool yang tidak diizinkan. Metrik ini penting terutama pada agent yang terhubung ke sistem transaksi atau workflow execution. Audit findings adalah temuan audit internal atau compliance review terhadap operasi agent. Jika audit trail lemah, evidence tidak lengkap, atau approval path tidak jelas, skala harus ditahan meski business metric tampak bagus.
Scorecard Gabungan: Value, Quality, Risk, Adoption
Pada akhirnya, perusahaan perlu satu scorecard yang tidak berat sebelah. Struktur sederhananya bisa mencakup lima dimensi. Value diukur dengan cycle time, cost per transaction, throughput, SLA, dan customer atau internal satisfaction. Quality diukur dengan success rate, correction rate, hallucination rate, dan handoff quality. Adoption dan Trust diukur dengan acceptance rate, override rate, repeat usage, dan explanation usefulness. Risk dan Control diukur dengan policy violations, unauthorized tool calls, data exposure incidents, dan audit findings. Efficiency of Digital Labor diukur dengan cost per successful outcome, tool failure rate, dan escalation rate.
Scorecard seperti ini membantu eksekutif menghindari dua kesalahan: hanya melihat value tanpa melihat risiko, atau terlalu fokus pada risiko sampai tidak pernah mengukur outcome nyata.
Implikasi Praktis
Setelah memahami kerangka ini, ada beberapa keputusan yang perlu diambil sekarang. Pertama, tentukan unit of measurement utama. Apakah Anda akan mengukur per task, per case, per transaction, atau per successful outcome? Untuk human-agent teams, ukuran terakhir biasanya paling berguna. Kedua, sepakati baseline sebelum scale. Jangan meluncurkan agent tanpa data pembanding untuk cycle time, cost, quality, dan exception rate.
Ketiga, bangun scorecard lintas fungsi. CIO, COO, risk, dan pemilik proses harus menyepakati kombinasi metrik value, quality, adoption, dan risk—bukan masing-masing memakai dashboard sendiri. Keempat, definisikan siapa pemilik tiap metrik. Business owner memegang outcome bisnis, platform team memegang reliability dan cost, supervisor memegang correction dan escalation pattern, risk owner memegang control metrics. Kelima, tentukan ambang untuk scale, pause, atau rollback. Misalnya, kapan correction rate terlalu tinggi, kapan policy violation membuat use case harus ditahan, atau kapan cost per successful outcome tidak lagi masuk akal.
Beberapa sinyal bahaya perlu diwaspadai. Jika keberhasilan masih diukur terutama dari jumlah automasi atau pengurangan jam kerja, jika tidak ada baseline yang kredibel sebelum implementasi, jika tim bisnis, IT, dan risk memakai definisi "success" yang berbeda-beda, jika override dan correction tinggi tetapi tidak masuk backlog perbaikan, jika token dan compute cost naik tetapi tidak dikaitkan dengan outcome, jika audit trail belum cukup untuk menjelaskan mengapa agent mengambil tindakan tertentu, jika pengguna memakai agent karena diwajibkan bukan karena membantu pekerjaan, atau jika policy violation dianggap "noise kecil" selama business metric tampak membaik—maka topik ini belum siap di-scale.
Pertanyaan reflektif untuk CIO, COO, CHRO, dan transformation leader: Jika besok Anda diminta membuktikan bahwa human-agent team di perusahaan benar-benar menciptakan nilai, apakah Anda hanya bisa menunjukkan demo dan tingkat penggunaan—atau sudah bisa menunjukkan scorecard yang seimbang antara outcome, kualitas, adopsi, biaya, dan kontrol? Itulah perbedaan antara eksperimen AI yang menarik dan operating model agentic yang siap di-scale.