ヒューマン・エージェント・チームのためのパフォーマンス指標
貴社の財務チームが、月次決算プロセスを支援するエージェントの導入を開始したと想像してください。エージェントはERPからデータを取得し、ドラフトコメンタリーを作成し、各勘定科目の証憑を準備します。経理統括チームには突如として多くの時間が生まれます。そこで浮上する疑問は、「どれだけの工数を削減できたか?」ではなく、「決算の品質は本当に向上したのか?」、あるいは「エージェントはチームがこれまで見逃していた異常値を発見するのに役立っているのか?」といったものです。
この種の問いは、多くの企業で現れ始めています。エージェンティックAIのパイロットが、財務決算、購買受付、カスタマーオペレーションズ、ITインシデントトリアージなど、複数の機能で稼働し始めると、経営陣は従来の指標ではもはや十分ではないことに気づき始めます。FTEあたりの生産性、稼働率、取引量、基本的なSLAは依然として有用ですが、人間とエージェントが協働する際に実際に何が起きているのかを捉えきれていません。
問題は、適切な指標がなければ、企業が二つの幻想に陥りやすいことです。第一の幻想はデモ効果です。システムは洗練されて見え、応答は速く、インターフェースは説得力がありますが、業務への影響は小さいものです。第二の幻想は自動化の虚栄です。企業は「自動化された」タスクの数に誇りを持ちますが、実際にはコスト、リスク、あるいは人間によるレビューの負荷が増加している場合があります。
従来の指標がもはや十分でない理由
従来の指標は、比較的明確な運用モデルから生まれました。すなわち、人間がタスクを実行し、システムがそれを支援し、アウトプットは量、時間、コストで測定されるというモデルです。このモデルでは、FTE稼働率、スループット、バックログ、SLAで十分に代表されていました。しかし、エージェントが業務の一部(コンテキストの読み取り、ツールの呼び出し、ドラフトの準備、ケースのルーティング、制限付きアクションの実行、必要な場合のみ人間へのエスカレーション)を引き継ぎ始めると、作業構造は根本的に変化します。
単一のビジネス成果は、もはや単一の労働力によって生み出されるわけではありません。それは、デジタル労働力、人間による監視、ワークフローオーケストレーション、データ品質、そして運用上のガードレールの組み合わせによって生み出されます。企業が従来の指標を単独で使い続けると、いくつかの歪みが生じます。
財務決算を例に考えてみましょう。エージェントが証憑収集とドラフトコメンタリー作成を引き継ぐため、経理統括チームの稼働率は低下する可能性があります。従来の見方では、これは「人間のキャパシティが遊休状態にある」ように見えます。しかし実際には、人間のキャパシティが、レビュー資料、根本原因分析、ビジネスパートナーリングへと移行しているのです。手作業の減少は、必ずしも価値の減少を意味するわけではありません。むしろ、それはオペレーティングモデルが改善されている兆候である場合もあります。
カスタマーオペレーションズでは、エージェントが1日あたりに処理するチケット数を増やすかもしれません。しかし、多くのケースでスーパーバイザーによる修正が必要だったり、問題が完全に解決されていないために顧客が再度問い合わせる必要があったりする場合、高いスループットは誤解を招きます。シェアードサービスでは、エージェントはほとんどすべてのリクエストに迅速に対応できます。しかし、その応答が単なる受領確認や一般的な回答である場合、SLAは良好に見えても、解決品質は低いままです。購買やITオペレーションズでは、エージェントがレベル1の作業負荷を軽減するかもしれません。しかし、許可されていないツール呼び出し、ポリシー違反、ルーティングミスが増加すれば、「節約された」コストは後で高くつく可能性があります。
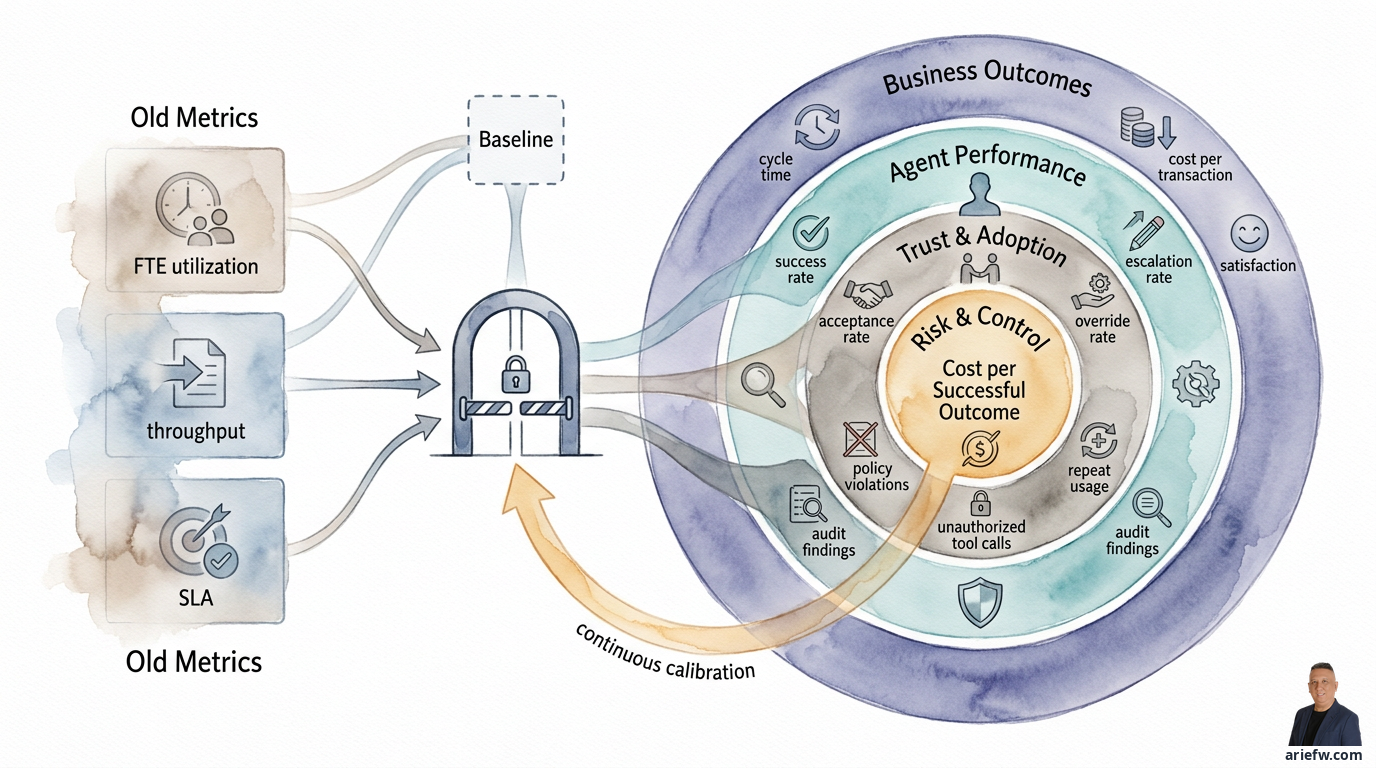
したがって、企業は新たな測定の次元を追加する必要があります。スコアカードには最低でも5つの要素、すなわちビジネス成果、自律性の度合い、例外とエスカレーション、信頼と採用、そしてコントロールの有効性を含める必要があります。これらがなければ、エージェンティックAIのパイロットが、興味深い実験なのか、本当にスケールする価値のある機能なのかを区別することは困難です。
ビジネス指標:活動ではなく成果から始める
最初の層は、やはりビジネスであるべきです。エージェントは目的ではありません。エージェントは成果を生み出すための新しい手段です。したがって、主要な指標は常に「エージェント導入後、ビジネスプロセスは改善されたか?」という問いに答えるものでなければなりません。
最も関連性の高い指標としては、通常、サイクルタイム、取引あたりまたはケースあたりのコスト、スループット、SLA達成率、顧客満足度または社内ユーザー満足度、そして特定のユースケースにおける収益漏洩または損失回避などが挙げられます。各領域によって重点は多少異なります。
財務決算では、決算完了までの時間、例外処理時間、レビューが遅れている勘定科目数、ドラフトコメンタリーの品質、次期に持ち越されたバックログ課題を測定します。決算エージェントがドラフト作成を迅速化するだけで、レビューのボトルネックを解消しないのであれば、ビジネス上の価値は限定的です。
購買オペレーションズでは、受付から発注までのサイクルタイム、リクエストが最初から正しいルートに乗った割合、手戻り率、調達ポリシーの遵守状況、社内要求元の満足度を測定します。分類を誤ることが多い高速なエージェントは、バイヤーの負荷を軽減するどころか、むしろ増加させます。
カスタマーオペレーションズでは、初回問い合わせ解決率、平均解決時間、再問い合わせ率、顧客満足度、不要な返金や譲歩の金額を測定します。ITオペレーションズでは、トリアージまでの平均時間、解決までの平均時間、インシデントバックログ、変更による障害の影響度、エージェントからエンジニアへのハンドオフの質を測定します。サプライチェーンでは、例外解決時間、サービスレベル、在庫可用性、緊急配送コスト、受注履行への影響を測定します。
しばしば見落とされる規律は、導入前のベースライン計測です。多くのチームが、実際のベースラインではなく、認識と結果を比較しながら、すぐにエージェントをローンチします。ベースラインがなければ、企業はサイクルタイムが本当に改善されたのか、成果あたりのコストが下がったのか、あるいは改善が実際にはポリシー変更、データ改善、手動プロセスの再設計など、他の要因に起因するものなのかを判断できません。最低限、エージェントを稼働させる前に、企業は現在のケースボリューム、解決時間、エラー率または手戻り率、運用コスト、そして成果の品質を文書化する必要があります。
また、企業は価値の帰属(value attribution)にも注意を払う必要があります。エージェント導入後のすべての改善がエージェントに起因するわけではありません。購買のサイクルタイムは、エージェントの受付機能だけでなく、承認マトリックスが簡素化されたために短縮された可能性があります。決算の品質は、データマッピングが改善されたために向上した可能性があります。顧客満足度は、ナレッジベースが整理されたために向上した可能性があります。これ自体は問題ではありません。むしろ、価値はプロセスの再設計、データクレンジング、エージェントの組み合わせから生まれることがよくあります。しかし、企業は価値の帰属について正直でなければなりません。すべての改善をAIの成果と主張すれば、ビジネスケースは脆弱になり、ガバナンスの信頼性は失われます。
エージェントパフォーマンス指標:デジタル労働力の品質を測定する
ビジネス成果に続く第二の層は、エージェント自身のパフォーマンスです。これは、ビジネス指標が良好だからといって、必ずしもエージェントが健全であるとは限らないため重要です。ビジネス結果が改善しても、計算コストが高騰したり、修正率が高かったり、スーパーバイザーが密かに大きな負担を負っていたりする可能性があります。
監視すべき主要な指標としては、成功率、エスカレーション率、ツール障害率、修正率、ハルシネーション率、信頼度キャリブレーションなどがあります。
成功率とは、単に「エージェントが回答を返した」という意味ではありません。成功を、目的に沿って完了し、実質的な修正を必要としない成果と定義します。サービスデスクでは、成功とはチケットがクローズされたことではなく、リクエストが正しく完了したことを意味します。財務では、成功とはドラフトや推奨事項が、最小限の修正でレビュー担当者に利用できることを意味します。購買では、成功とはリクエストが正しくルーティングされ、手戻りが発生しないことを意味します。
エスカレーション率は、人間に上げなければならなかったケースの割合を示します。これは重要な指標ですが、文脈を考慮して解釈する必要があります。高すぎる場合は、エージェントが保守的すぎるか、まだ十分に成熟していないことを意味します。低すぎる場合は、エージェントが攻撃的すぎて、エスカレーションすべきケースを見逃しているリスクがあります。目標は常に「可能な限り低く」することではなく、リスク階層とワークフローの設計に応じた適切な水準にすることです。
エージェントの障害の多くは、推論能力ではなく、統合に起因します。すなわち、APIの失敗、データの欠如、権限の誤り、ツールのタイムアウトなどです。ツール障害率が高い場合、問題はモデル自体ではなく、アーキテクチャとプラットフォームにあります。
修正率は、最も正直な指標の一つです。人間がエージェントのアウトプットをどの程度の頻度で修正しなければならないかを示します。この指標は、財務のドラフトコメンタリー、カスタマー対応の推奨文、購買受付の分類、インシデントトリアージ、サプライチェーンの例外サマリーなどで非常に有用です。修正率が高い場合、疑似生産性が発生しています。すなわち、エージェントは活発に見えますが、人間は同じ作業を繰り返し行っていることになります。
文書、ナレッジ、エンタープライズデータに基づく推論を含むワークフローの場合、企業はエージェントが存在しないポリシーを引用したり、証拠によって裏付けられていない事実を推論したり、もっともらしいが誤った回答を返したりする頻度を追跡する必要があります。すべての組織がハルシネーション率を完全に測定できるわけではありませんが、サンプリングレビューとケース監査によって初期の指標を得ることができます。
信頼度キャリブレーションも重要です。優れたエージェントとは、単に正解率が高いだけでなく、自身が確信を持てない場合を認識できるエージェントです。高い信頼度が、誤ったケースで頻繁に示される場合、キャリブレーションは不良です。これは、ユーザーが確信に満ちたアウトプットに騙されやすくなるため危険です。
企業がオーケストレーターと複数のタスクエージェントを使用する場合は、さらに2つの重要な指標を追加する必要があります。すなわち、ハンドオフの質(コンテキストがエージェント間、または人間へ正しく引き継がれるかどうか)と、オーケストレーションの失敗(ステップの順序、依存関係、ルーティングの誤りによりワークフローが失敗する頻度)です。例えば、ITデリバリーにおいて、要件エージェント、コーディングエージェント、QAエージェント、レビューアエージェントがそれぞれ良好に見えても、ハンドオフが不良であれば、ワークフロー全体は失敗します。
最後に、成功した成果あたりのコストを忘れてはなりません。トークン、計算、検索、ツール呼び出しのコストは、規模が拡大するにつれて静かに増加する可能性があります。したがって、実行あたりのコストやプロンプトあたりのコストだけでなく、成功した成果あたりのコストを測定してください。これは、より戦略的な問いに答えるのに役立ちます。すなわち、エージェントは従来の作業モデルよりも本当に経済的なのか、追加の自律性はコストに見合うのか、技術的には成功しているが経済的には健全でないユースケースはないか、といった問いです。
信頼とリスクの指標:信頼なしに採用は持続しない
ユーザーがシステムを信頼していなかったり、リスク管理部門がコントロールを不明確に感じていたりする場合、ヒューマン・エージェント・チームは安定しません。したがって、企業は信頼とリスクの両方を測定する必要があります。
信頼については、最も有用な指標として、ユーザー受入率、オーバーライド率、説明の有用性、再利用率が挙げられます。ユーザー受入率は、ユーザーがエージェントの推奨やアウトプットを全面的に置き換えることなく受け入れる頻度を示します。オーバーライド率は、人間がエージェントの決定を拒否または置き換える頻度を示します。オーバーライド率が高い場合は、品質の低さ、信頼の低さ、またはポリシーの不一致を示している可能性があります。しかし、オーバーライド率がゼロであることも自動的に良いとは限りません。ユーザーが受動的であるか、十分に批判的でない可能性があります。
説明の有用性は、エージェントの説明が、ユーザーが推奨の背後にある理由を理解するのに役立つかどうかを測定します。財務、購買、ITオペレーションズなどの領域では、役立つ説明は、迅速な回答よりも重要であることがよくあります。それがなければ、信頼は育ちにくいものです。再利用率はシンプルですが強力な指標です。ユーザーは、義務付けられていない場合でも、エージェントを再び利用するでしょうか?人々が求められてエージェントを使っているだけなら、採用はまだ浅いと言えます。
リスクについては、この層はリスク、コンプライアンス、セキュリティ、内部監査の各部門と連携して評価する必要があります。主要な指標としては、ポリシー違反、データ漏洩インシデント、許可されていないツール呼び出し、監査指摘事項などがあります。ポリシー違反には、エージェントが委任された権限の範囲外で推奨を行う、承認閾値を超える、ポリシーに適合しないルートにケースをルーティングするなどが含まれます。データ漏洩インシデントは、エージェントがユーザーや特定のツールがアクセスすべきでないデータを表示したかどうかを測定します。これは、ERP、HRIS、CRM、顧客データに触れるワークフローにとって非常に重要です。
許可されていないツール呼び出しは、エージェントが許可されていないツールを呼び出そうとした、または呼び出しに成功したかどうかを測定します。この指標は、特にトランザクションシステムやワークフロー実行に接続されたエージェントにとって重要です。監査指摘事項は、エージェントの運用に対する内部監査またはコンプライアンスレビューの結果です。監査証跡が弱く、証拠が不完全で、承認経路が不明確な場合、ビジネス指標が良好に見えても、スケールは抑制されるべきです。
統合スコアカード:価値、品質、リスク、採用
最終的に、企業は偏りのない単一のスコアカードを必要とします。シンプルな構造としては、5つの次元を含めることができます。価値は、サイクルタイム、取引あたりのコスト、スループット、SLA、顧客満足度または社内満足度で測定します。品質は、成功率、修正率、ハルシネーション率、ハンドオフの質で測定します。採用と信頼は、受入率、オーバーライド率、再利用率、説明の有用性で測定します。リスクとコントロールは、ポリシー違反、許可されていないツール呼び出し、データ漏洩インシデント、監査指摘事項で測定します。デジタル労働力の効率性は、成功した成果あたりのコスト、ツール障害率、エスカレーション率で測定します。
このようなスコアカードは、経営幹部が2つの誤り、すなわちリスクを見ずに価値だけを見ること、あるいはリスクに集中しすぎて実際の成果を測定しないことを避けるのに役立ちます。
実践的な示唆
このフレームワークを理解した上で、今すぐ取るべきいくつかの決定があります。第一に、主要な測定単位を決定します。タスク単位、ケース単位、取引単位、それとも成功した成果単位で測定しますか?ヒューマン・エージェント・チームにとっては、最後の単位が最も有用であることが多いです。第二に、スケールする前にベースラインを合意します。サイクルタイム、コスト、品質、例外率の比較データなしにエージェントをローンチしてはいけません。
第三に、部門横断的なスコアカードを構築します。CIO、COO、リスク管理部門、プロセスオーナーは、価値、品質、採用、リスクの指標の組み合わせについて合意する必要があり、それぞれが独自のダッシュボードを使用するべきではありません。第四に、各指標の所有者を定義します。ビジネスオーナーはビジネス成果を、プラットフォームチームは信頼性とコストを、スーパーバイザーは修正とエスカレーションパターンを、リスクオーナーはコントロール指標を担当します。第五に、スケール、一時停止、ロールバックの閾値を決定します。例えば、修正率がどの程度高ければ、ポリシー違反がどの程度であればユースケースを保留すべきか、成功した成果あたりのコストがどの程度であればもはや合理的でないか、といった基準です。
いくつかの危険信号に注意する必要があります。成功が主に自動化の量や工数削減で測定されている場合、導入前に信頼できるベースラインがない場合、ビジネス部門、IT部門、リスク部門で「成功」の定義が異なる場合、オーバーライドと修正率が高いにもかかわらず改善バックログに入っていない場合、トークンと計算コストが増加しているが成果と結びつけられていない場合、監査証跡がエージェントが特定のアクションを取った理由を説明するのに十分でない場合、ユーザーが業務の助けになるからではなく義務付けられているからエージェントを使っている場合、ビジネス指標が良好に見えるという理由でポリシー違反が「小さなノイズ」と見なされている場合、これらはこのテーマがスケールする準備ができていないことを示しています。
CIO、COO、CHRO、そして変革リーダーへの内省的な問いかけです。もし明日、貴社のヒューマン・エージェント・チームが真に価値を創造していることを証明するよう求められたら、デモと使用率だけを示すことができるでしょうか?それとも、成果、品質、採用、コスト、コントロールのバランスが取れたスコアカードを既に示すことができるでしょうか?それが、興味深いAI実験と、スケール可能なエージェンティック・オペレーティングモデルとの違いです。