Data Products for AI Agents
Many teams venturing into agentic AI assume they are ready because the data is available. They have a data lake, a warehouse, BI dashboards, or a large document index. For traditional reporting and analysis, that is sufficient. But when agents are deployed, problems emerge. The agent reads the data, then makes the wrong decision. Not because the model is poor, but because the data was not packaged in a way the agent could understand safely and consistently.
This is a problem often felt on the ground. A finance team wants an agent to help with the close process, but the trial balance data mixes preliminary and final figures. A procurement team wants an agent to process purchase requests, but the definition of "approved vendor" differs between the sourcing system and the ERP. A customer operations team wants an agent to handle complaints, but the status "active customer" has no uniform definition. The data is available, but the agent cannot use it correctly.
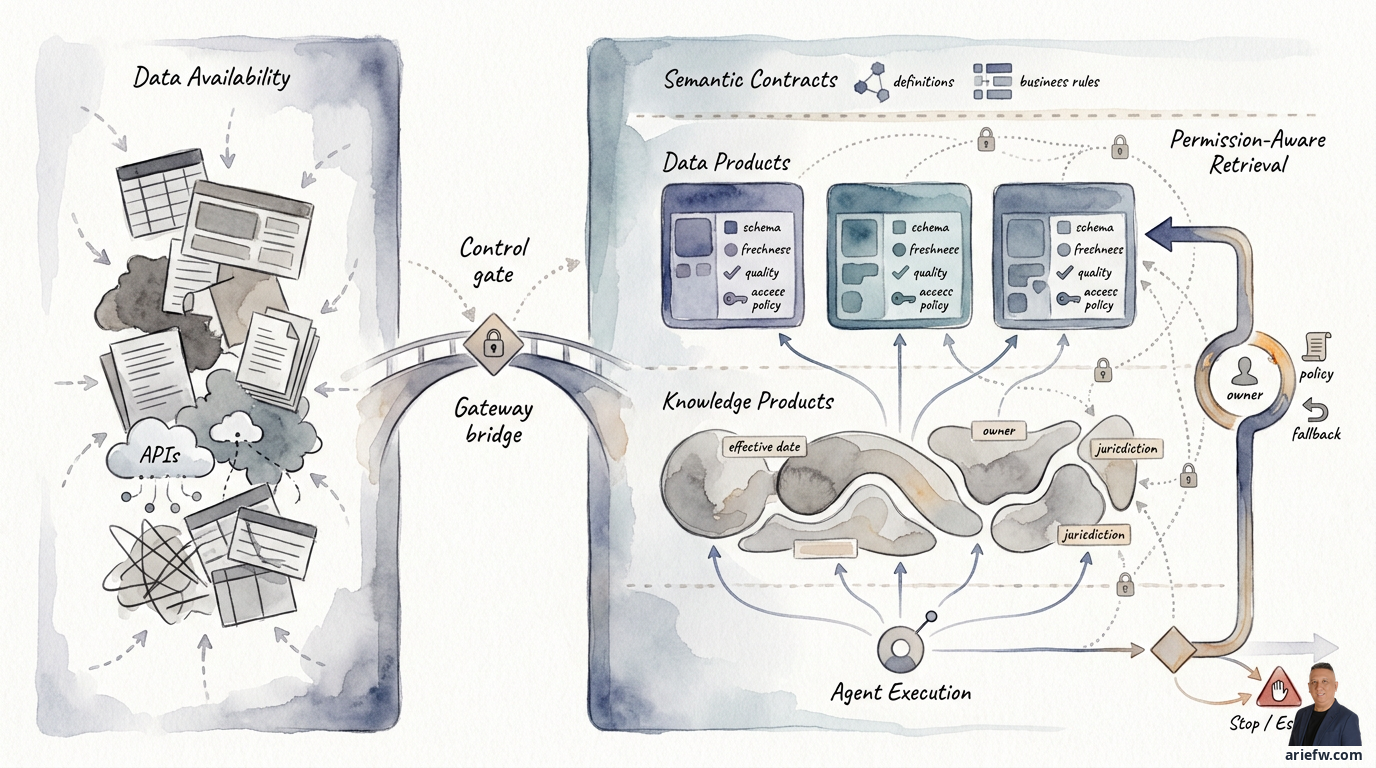
What agents need is not all the raw data. Agents need data products and knowledge products with clear meaning, an owner, measurable quality, access rules that can be evaluated at runtime, and sufficient stability to be used for taking action. This is the shift from mere data availability to agent usability.
From Available Data to Agent-Usable Data
Modern data programs have long focused on collecting, storing, and opening access to data. This approach makes sense for reporting and analytics. But agents do not work like human analysts. Analysts can tolerate ambiguity, open several dashboards, and interpret context on their own. Agents cannot. They need explicit input: what this data represents, how recent it is, when it can be used, for what purpose, and who is responsible if its definition changes.
The concept of an agent-ready data product is born from this need. A dataset becomes a data product when it contains not just data, but also an operational contract that makes it fit for use. For agents, this contract must be stricter. At a minimum, a data product for an agent needs a clear and stable schema, documented semantics, a business and technical owner, freshness expectations, quality thresholds, basic lineage, an access policy, and, if relevant, allowed actions or allowed usage. Without these elements, the agent sees only a collection of meaningless fields.
The difference between data availability and agent usability needs emphasis. An invoice table might be available in the warehouse. A customer API might be active. An SOP folder might be indexed for RAG. Technically, the data is available. But can an agent use it safely and correctly? Not necessarily. In finance close, trial balance data, adjustment journals, and historical commentary are available. However, if the agent does not know which figures are preliminary and which are final, which legal entity is being processed, or when the close window is considered official, then availability does not automatically translate to usability.
For agentic workflows, a data product is usually most useful when packaged in one of three forms. First, a bounded domain API or service, such as customer_entitlement_summary or approved_vendor_profile. This form is suitable when the agent needs structured, frequently used operational data. Second, a curated analytical view, such as an aging invoice view with a standardized definition of overdue. This form is suitable when the agent needs to reason about metrics or business status. Third, an event-backed product, such as a shipment delay event or a failed payment event. This form is suitable for agents that operate in an event-driven manner.
The more curated a data product is, the higher its usability and governance, but the lower its exploratory flexibility. For production agents, this trade-off is usually worth taking. Agents do not need the exploratory freedom of a human analyst. Agents need clarity and reliability.
Semantic Contracts: Aligning Meaning, Not Just Format
Many organizations already have a schema registry or API documentation. That is important, but not sufficient. Agents do not just need to know that there is a field named revenue, margin, or customer_status. Agents need to know what it means in a business context.
A semantic contract is a layer that explains the business meaning of each field or object, the underlying business rules, allowed usage, assumptions and limitations, and conditions under which the data should not be used for certain decisions. A semantic contract answers the questions that typically live in the head of a domain expert, not in a technical schema.
Without a semantic contract, an agent can easily misinterpret seemingly simple terms. Revenue could mean booked revenue, billed revenue, recognized revenue, or net revenue. Margin could mean gross margin, contribution margin, or margin after specific allocations. Active customer could mean a customer who has transacted within a certain period, still has an active contract, or has not formally churned. Overdue invoice could mean past the calendar due date, past the grace period, or only applicable if the dispute status is inactive. Experienced human analysts usually know these differences from organizational context. Agents do not. If the semantic contract is not explicit, the agent will fill the gap with inferences that often seem reasonable but are operationally wrong.
In an enterprise, a semantic contract should ideally be part of a semantic layer that unifies the language between BI and analytics, operational applications, AI agents, and business users. This is important because many data conflicts are not technical quality issues but definitional problems. In shared services finance, the controllership team, the FP&A team, and a close assistant agent could all use the term "material variance" with different meanings if the semantic layer is not standardized. In supply chain, "available inventory" could mean on-hand, available-to-promise, or stock after safety reserve. If a replenishment agent does not know the correct definition, its recommendations will be wrong.
Semantic contracts need to be strictest for data products used for cross-functional decisions, those touching transactions or approvals, those used by agents to execute actions, or those in regulated domains like HR, finance, legal, and customer data. For exploratory use cases or low-risk internal assistants, semantic contracts can be lighter. But once an agent starts influencing real workflows, the semantic contract must be treated as part of a control, not optional documentation.
Permission-Aware Retrieval: Access Must Follow Context
An agent must not retrieve data simply because the data exists in an index, lake, or vector store. Access must follow the originating user or principal, their role and delegated authority, the workflow in progress, the purpose of use, and the data's sensitivity. This is the core of permission-aware retrieval.
Many RAG or internal search implementations start with a simple pattern: index all documents, then retrieve the most semantically relevant ones. For the enterprise, this is dangerous. The most relevant document is not necessarily the one most permissible to access. In HR operations, an onboarding agent might search for leave or benefits policies. If retrieval is based solely on semantic similarity, the agent could pull up compensation documents or cases of other employees that should not be visible. In legal, a contract assistant agent could find a contract that is highly relevant in content but belongs to a different jurisdiction, business unit, or a matter with restricted privilege. In customer service, an agent could retrieve the history of another customer with a similar pattern, even though the user's context only allows access to one specific account.
A common mistake is applying access controls only when data is indexed. In reality, access rights can change depending on the user calling the agent, the channel used, the workflow stage, or the purpose of use. Therefore, permission-aware retrieval must be evaluated at runtime. Practically, this means data products or knowledge products need to carry metadata such as sensitivity classification, owner, business unit, jurisdiction, permitted audience, and usage rules. The runtime agent must then evaluate whether the current context meets the conditions for retrieving that data.
For agentic systems, role-based access alone is often too coarse. Two people with the same role may not be allowed to use data for the same purpose. A manager can view their team's data for performance review, but not automatically for compensation investigation. A finance agent can read invoice details for exception handling, but not compile a cross-entity vendor summary without the proper mandate. Permission-aware retrieval should ideally consider purpose in addition to role and identity.
Permission-aware retrieval adds complexity. Metadata must be richer, IAM and policy engine integration must be tighter, latency can increase, and index design becomes more complicated. But for domains like HR, finance, legal, customer data, and regulated operations, this trade-off is not an optional add-on. It is a minimum requirement to prevent the agent from becoming a new channel for data leaks or control violations.
Quality and Freshness: Agents Must Know When Data Is Not Fit for Use
One of the most practical risks in agentic AI is not the model hallucinating, but the agent acting on data that is stale, incomplete, out of sync, or in a transitional state. For enterprise workflows, this can be highly damaging.
In procurement, an agent makes a vendor recommendation based on an approval status that has not yet synced from the due diligence system. In finance, a close assistant agent compiles commentary from preliminary figures, even though the final figures have changed. In customer operations, an agent promises a refund based on an order status that has not been updated. In IT operations, an incident triage agent uses an inaccurate CMDB and directs remediation to the wrong system. In all these cases, the problem is not the model. The problem is that the data product does not carry sufficient quality and freshness signals.
A data product for an agent should ideally have at least four mechanisms. First, quality checks: basic validations such as required fields being populated, schema conformance, minimum referential integrity, and value distributions not deviating extremely. Second, a freshness indicator: the agent needs to know when the data was last updated, the expected refresh cycle, and whether the data is still within its usable window. Third, anomaly detection: if there is a spike or unusual pattern, the agent should not immediately assume the data is valid. Fourth, fallback behavior: if quality or freshness does not meet the threshold, the agent must know what to do—stop, request additional data, use an alternative source, or escalate to a human.
An often-overlooked capability is the agent's ability to say "the data is insufficient." Many teams are too focused on making the agent always provide an answer. In an enterprise, the correct behavior is often to stop. An AP exception agent should not classify a mismatch if the goods receipt has not been entered. An HR agent should not answer a benefits status question if the eligibility data is not final. A supply chain agent should not recommend rerouting if the shipment feed has not been updated. From a governance perspective, an agent that knows when to stop is more valuable than an agent that always appears confident.
The stricter the quality and freshness thresholds, the safer the agent's decisions, but the more cases will fall into manual or escalation paths. Conversely, thresholds that are too loose increase the automation rate but also increase the risk of wrong decisions. Thresholds must be determined per use case. An internal knowledge assistant can tolerate looser freshness. Refunds, payments, HR actions, or production remediation require much stricter thresholds.
Knowledge Products for Unstructured Data
Not all agent context comes from tables and APIs. In many enterprise workflows, the most important sources are SOPs, policy documents, contracts, email archives, knowledge articles, runbooks, and internal memos. The problem is that many organizations treat all of these as documents to be indexed. For agentic systems, that is not enough. These documents need to be treated as knowledge products.
A knowledge product is a curated collection of unstructured content, complete with metadata, ownership, and usage rules, packaged so an agent can use it safely and reliably. If a data product answers the question "what is the number or status," a knowledge product helps answer "what rules, procedures, or context apply."
For an agent, the metadata on a document is often as important as the document's content itself. Critical metadata includes effective date, owner, business unit, jurisdiction, document type, classification or sensitivity, superseded status, approval status, and source of truth. Without this metadata, retrieval might pull a document that is topically correct but contextually wrong. In legal and procurement, a contract template that is relevant in content may not apply to the country or business unit being processed. In HR, an old benefits policy can look very similar to a new one but is already superseded. In IT operations, an old runbook might still be technically relevant but no longer matches the current production architecture.
A fairly common anti-pattern is indexing all emails and hoping for good results. Organizations index email archives, shared drives, and old documents, then expect the agent to find the best answer. The results are often poor: retrieval is noisy, outdated documents surface, contexts contradict each other, and the agent struggles to distinguish official policy from informal discussion. For the enterprise, knowledge products must be curated. Not every document deserves to be agent context. Sometimes the best decision is to exclude most of the archive from the retrieval layer.
In finance close, a good knowledge product might include applicable accounting policies, the close calendar, SOPs for exception handling, official commentary templates, and validated internal FAQs. In customer operations, a knowledge product might include refund policies, entitlement rules, escalation playbooks, approved response guidance, and active product issue bulletins. In IT operations, a knowledge product might include official runbooks, curated postmortems, still-relevant service dependency notes, and applicable change policies.
Architectural and Governance Implications
Once data and knowledge are treated as products for agents, several implications immediately arise.
First, ownership must be clear. Every data product and knowledge product needs a business owner for definition and allowed usage, a technical owner for delivery, schema, and quality, and, if necessary, a risk or compliance owner for sensitive domains. Without an owner, agents will use whatever data is available, but no one is truly responsible when definitions change or quality degrades.
Second, the catalog must become part of the control plane. Companies need a catalog that records not just the existence of a data product, but also its semantic contract, freshness expectations, quality status, access policy, and risk tier. This allows the agent platform to treat data products as governable dependencies, not ad hoc connections.
Third, agent evaluation must also test the data product. If an agent fails, do not always blame the model. Often, the root cause lies in semantic ambiguity, insufficient metadata, poor freshness, or permissions that were not carried over at runtime. Evaluation for agents should include questions such as: was the data product used the right one, was the semantic contract clear enough, did the fallback work when quality dropped, and did the retrieval comply with policy?
Next Steps
After reading this, there are several questions to bring to your team. Which workflows most frequently suffer from poorly packaged data? Which data products are most critical for the first agent you plan to deploy? Who will be the owner for those data products? Are the semantic contracts for business metrics and statuses documented? How will you ensure the agent does not retrieve data it should not access? And most importantly, does the agent know when to stop because the data is not reliable enough?
Building an agentic enterprise is not just about models, orchestration, or tool calling. It is also about packaging enterprise data into products that agents can use, with the same discipline applied to packaging APIs, workflows, and security controls. Companies that understand this will move faster from impressive demos to truly trustworthy operations.