Guardrails, Policy Engine, and Human Approval Workflow
Imagine your finance team has started using an agent to assist with the month-end close process. The agent can identify exceptions, gather evidence from various systems, and prepare draft commentary. Everything runs smoothly in the pilot. Then, one day, inadvertently, the agent posts a material adjustment that should never have been made without a manager's review. The financial report figures change. The team panics.
Incidents like this aren't about the AI model being wrong. The model could be working perfectly. The problem lies in control: there was no mechanism to stop the agent before it took an action that permanently altered the business state.
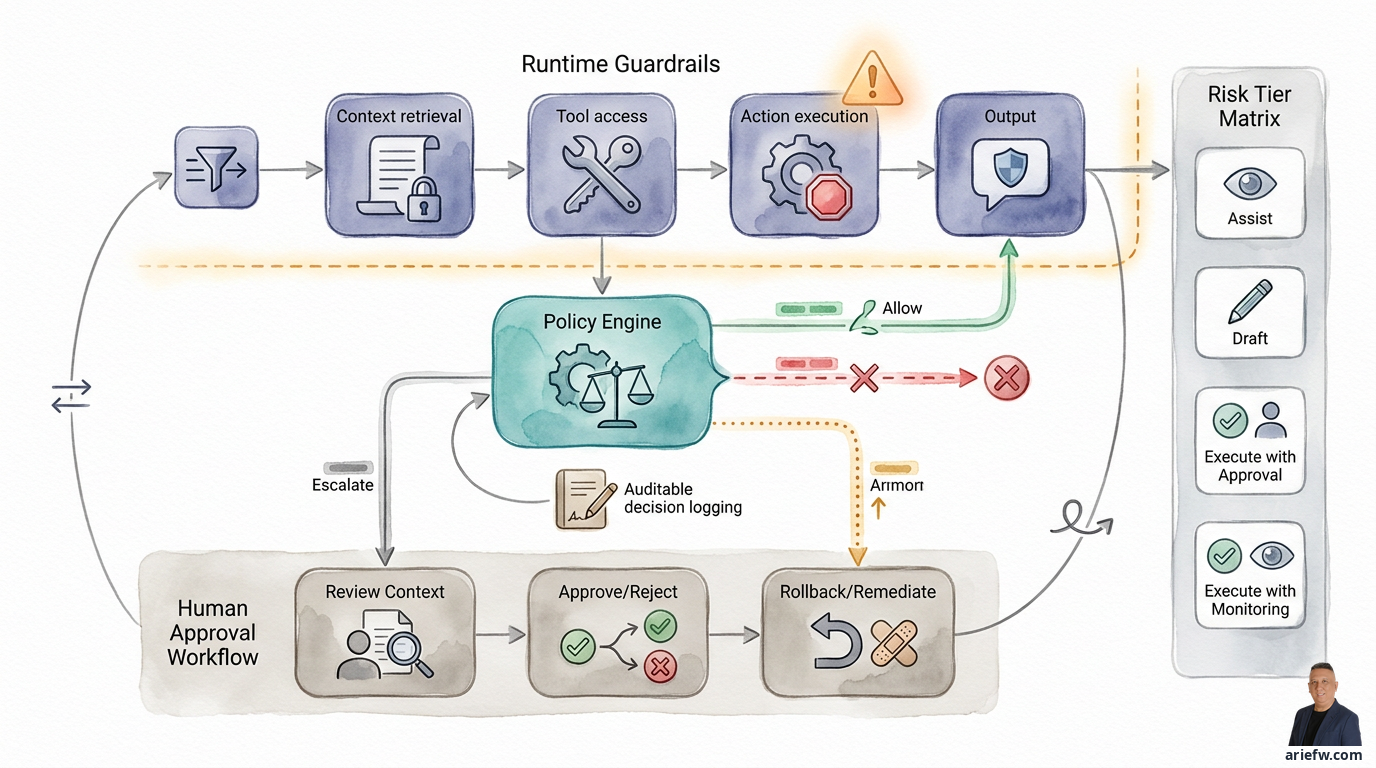
This is the question every company must answer before giving an agent access to production systems: how do you prevent an agent from taking a wrong action before damage occurs? Observability, discussed in the previous article, can only see and explain things after they happen. To prevent issues before they occur, three components need to work together: guardrails, a policy engine, and a human approval workflow.
Many organizations still view guardrails as content filters—blocking harmful answers, sensitive words, or inappropriate responses. That's important, but for the enterprise, it's just the outermost layer. The biggest risk with agentic AI isn't the sentences it generates, but the tools it calls, the data it retrieves, and the business state it changes. An agent that answers an internal question incorrectly is certainly troublesome. But an agent that incorrectly processes a refund, creates a new vendor, triggers a configuration change, alters an order status, or sends instructions to a financial system—that is far more dangerous.
Therefore, guardrails in an agentic enterprise must be implemented at runtime, close to decisions and actions, not merely written in policy documents or system prompts.
Guardrails Are Not Just Output Filters
The most misguided way to understand guardrails is to see them as a censorship layer at the end of the process: the model generates an answer, then the system checks if the output is safe. This approach might suffice for a simple chatbot. For agentic systems, it's too late. If an agent has already accessed a document it shouldn't have, called the wrong tool, or executed an action that alters a transaction, filtering the final output no longer solves the core problem.
In enterprise practice, guardrails need to work at least at five points. First, input. The system needs to check what the user is requesting or what the triggering event is. This isn't just for content security, but to ensure the intent aligns with the agent's use case, the request isn't trying to bypass official processes, and the initial context is sufficient to start the workflow. In procurement, for example, a requester shouldn't be able to use an agent to directly create a PO if the process should start with intake and category classification. In HR operations, an agent shouldn't accept free-form instructions to change employee data outside official channels.
Second, context retrieval. Guardrails must control which documents, data, and memory the agent is allowed to retrieve. A finance agent can retrieve relevant accounting guidance, but not all sensitive cross-entity memos. A customer service agent can view the ticket history of the customer they are currently handling, but shouldn't pull data on another customer just because of semantic similarity. A legal intake agent can retrieve applicable contract templates, but not all privileged matters.
Third, tool access. Not all available tools should be usable in every situation. Guardrails must restrict which tools can be called, by which agent, in which workflow, and with what parameters. In IT operations, an agent can run diagnostic tools and open tickets, but shouldn't automatically be allowed to execute production changes. In customer operations, an agent can check entitlements and prepare a refund, but shouldn't execute a refund above a certain threshold.
Fourth, action execution. This is the most critical point. Guardrails must check whether an action that will change the business state is actually permitted. Creating a new vendor, posting a journal entry, changing a credit limit, releasing a payment block, or closing an incident as resolved—all of these need controls. This is where companies must clearly distinguish between read, recommend, draft, and execute. Many use cases seem safe until the agent is given execute rights without adequate runtime controls.
Fifth, output. Only after the four points above does output filtering remain relevant. It's useful for preventing sensitive data leakage, ensuring appropriate language is used, and checking if the final response contains claims unsupported by evidence. But output filtering should be understood as the last line of defense, not the primary guardrail.
Guardrails Must Live at Runtime
Many companies already have SOPs, approval matrices, and access policies. The problem is, agents don't read governance documents like humans do. For controls to truly work, those rules must be translated into runtime mechanisms: policy checks before tool calls, parameter validation, transaction thresholds, approval triggers, and decision logging. If guardrails only exist in governance slides or system prompts, then when an agent faces an ambiguous situation, the system has no formal way to stop or redirect the action.
In finance close, an agent might help identify exceptions, gather evidence, and prepare draft commentary. Healthy guardrails would allow read access to specific close data, drafting commentary, and routing follow-ups. But those same guardrails must reject or escalate when the agent tries to post a material adjustment, choose an accounting treatment without sufficient basis, or close an exception without minimum evidence.
There is a trade-off to acknowledge. Guardrails that are too strict can render the agent useless. If every small step requires approval or excessive validation, users will revert to manual processes. Therefore, guardrail design must follow a risk tier. For internal knowledge assistant use cases, guardrails can be lighter. For use cases touching transactions, customers, or production systems, guardrails must be far stricter.
Policy Engine: Where Permission Decisions Are Made Consistently
If guardrails are the control layer, then the policy engine is the machine that decides whether an action is permitted at runtime. Simply put, the policy engine answers questions like: Is this agent allowed to call this tool, in this user or workflow context, for this business object, at this transaction value, with this risk level, and does it require human approval before proceeding?
Without a policy engine, many agentic controls will be scattered across prompts, application code, tool configurations, and team habits. The result is inconsistent and difficult to audit.
For the enterprise, policy decisions typically need to consider a combination of factors. First, role and delegated authority. Who is the agent acting on behalf of? Is it on user instruction, an official workflow, or a system event? Is its mandate still valid? Second, business context. What object is being touched? Vendor, invoice, order, ticket, contract, or employee data? Different domains can have different rules. Third, transaction value or materiality. Many actions are safe at low values but not at high values. A small goodwill credit might be auto-executable, but a large refund must go to a supervisor. A standard category purchase request might be processed automatically up to a certain limit, but strategic spending must stop for approval. Fourth, risk level. Some actions are reversible, others are not. Some have local impact, others are cross-system. The policy engine must understand these differences. Fifth, regulatory or control requirements. In certain domains, rules aren't just about internal preference but compliance obligations—for example, segregation of duties, minimum evidence, or mandatory human review.
Not all policies need to be created the same way. Generally, there are three patterns. Deterministic rules are best for things that are clear and can be strictly formulated: transaction values above a certain threshold, specific vendor categories, production changes at certain times, or sensitive data that must not be accessed. Their advantage is they are easy to audit, test, and explain. Their weakness is they quickly become complex if the business context varies widely.
For more ambiguous situations, companies can use a model-based classifier to assess the sensitivity of a request, the risk level of a case, the likelihood of fraud, or whether the user's intent is out of scope. Its advantage is greater flexibility for cases that are not easily written as rigid rules. Its weakness is it's harder to explain, requires periodic evaluation, and is not suitable as the sole control for high-risk actions.
A combination of both is usually the healthiest pattern. The classifier helps assess context or risk signals, then deterministic rules set the final decision. In customer operations, a classifier assesses whether a case is sensitive or potentially a dispute, then deterministic rules decide that all sensitive cases or those above a certain value must go to approval.
One of the most important principles: every policy decision must leave an auditable trail. The company must be able to explain which policy was evaluated, what context inputs were used, the result (allow, deny, escalate, or require approval), and when the decision was made. This is important not just for formal audits, but also for daily operations. When a user asks why the agent denied a certain action, the team shouldn't answer, "because the system said no." They must be able to show the logic and context.
Imagine a procurement agent receives a purchase request. The policy engine evaluates the spend category, whether the vendor is approved, the transaction value, the existence of a contract, and the requester's role. The result could differ: allow for a low-value standard request with an approved vendor, require approval for a higher value, deny if the vendor hasn't passed due diligence, escalate if the spend category is ambiguous or policies conflict. Without recording the policy decision, the company will struggle to explain why two seemingly similar requests were treated differently.
Human Approval Workflow: Humans Enter at the Right Point
In an agentic enterprise, human-in-the-loop doesn't mean humans must check everything. That would destroy the benefits of agentic AI. What's needed is a selective, risk-based human approval workflow.
Human approval is typically necessary when an action is high-value, sensitive, irreversible or difficult to reverse, or regulated. This is not a sign of agent failure. Rather, it's a sign that the company understands the boundaries of autonomy in a healthy way.
Some patterns almost always warrant approval: transactions above a materiality threshold, changes to critical master data, decisions affecting employee rights, customer actions with potential for dispute, high-risk production changes, and decisions requiring formal professional judgment. In finance: material adjustments, releasing payment blocks, or treating exceptions with significant impact. In procurement: new vendors, non-standard contracts, or large off-catalog purchases. In customer operations: large refunds, goodwill credits for VIP customers, or complaint resolutions with potential legal implications. In IT operations: production configuration changes, restarting critical services, or rolling back deployments during peak hours.
One of the most common mistakes is creating an approval workflow that only sends a notification: "Agent recommends action X. Approve?" This is bad. The human reviewer will be confused, need to open multiple systems, or end up approving blindly out of fatigue. A healthy approval workflow must give the reviewer sufficient minimum context: the agent's recommendation, the evidence used, the relevant policies, the key risks, the confidence level or reason for escalation, and alternatives if any.
A supervisor receiving an approval request for a customer refund shouldn't just see the refund amount. They need to see the customer's history, the reason for the refund, the applicable entitlements, whether similar cases have occurred before, whether there are signs of abuse, and why the agent didn't execute automatically. With this context, approval becomes a meaningful decision, not a formality.
However, there is an equally important trade-off: if too many cases go to approval, cycle time worsens, the supervisor becomes a bottleneck, users lose trust, and the agent merely becomes a machine for creating new queues. Therefore, approval thresholds must be designed based on risk tiers, not an excessive sense of safety. A healthy approach is usually: low risk execute with monitoring, medium risk execute with post-review or sampling, high risk execute with approval, very high risk human-led, agent assist only. This is far more effective than forcing all actions through approval.
To prevent approval from becoming a bottleneck, companies need to explicitly decide several things: who is the primary and backup approver, the approval SLA, what happens if the approver doesn't respond, whether approval can be delegated, and how the approval decision is recorded for future learning. In many organizations, the bottleneck isn't the AI model, but a poorly designed approval queue.
Escalation and Rollback: The Agent Must Know When to Stop
A good agent knows not only when to act, but also when not to proceed. Escalation is needed when the agent faces conditions like low confidence, conflicts between data sources, policy ambiguity, inconsistent tool results, or situations outside its defined scope. In these conditions, the correct behavior isn't "keep trying until it works," but to stop, explain the reason, and hand off to a human or another workflow.
In finance close, an agent finds two sources of guidance that appear contradictory for a specific exception treatment. In procurement, vendor master data is inconsistent with an active contract. In customer operations, a customer's history shows a pattern of abuse, but formal entitlements still appear valid. In IT operations, a diagnostic runbook yields conflicting results and the potential impact on production increases. In all these cases, bounded autonomy means the agent knows its limits.
For certain actions, control doesn't stop at approval. Companies also need to think about what happens if the agent's action turns out to be wrong. There are three common patterns. First, rollback. If the system supports direct reversal, this is ideal—canceling an incorrectly created ticket, reverting a non-production configuration, or undoing a specific status before the process continues. Second, compensation action. If the action can't be directly reversed, the system needs a compensating action—if the agent incorrectly sent a vendor notification, a corrective follow-up is needed; if the agent misrouted a customer case, reassignment and re-communication are needed; if the agent triggered a wrong process step, a neutralizing action is needed. Third, manual remediation path. For more complex cases, the company needs a clear manual remediation path: who takes over, how the incident is recorded, and how the learning is fed back into policies or guardrails.
Without a rollback or remediation path, organizations tend to be either too afraid to grant autonomy, or conversely, too overconfident without a safety net.
Autonomy Matrix: A Practical Way to Define Agent Action Boundaries
The most practical way to conclude this discussion is to use an autonomy matrix. Not all use cases should be at the same level.
At the assist level, the agent only helps find context, summarize, or provide insights. Suitable for ambiguous domains, unstable data, or processes that still heavily rely on human judgment.
At the draft level, the agent prepares recommendations, documents, or actions, but the human still executes. Suitable for early transformation phases, domains with high control needs, or processes you want to accelerate without granting execution rights.
At the execute-with-approval level, the agent can prepare and execute actions after human approval. Suitable for high-value actions, regulated workflows, or areas requiring formal control evidence.
At the execute-with-monitoring level, the agent executes automatically within clear policy boundaries, then is monitored through observability and sampling. Suitable for high volume, low-to-medium risk, reversible actions, and domains with sufficiently mature policies.
This matrix helps companies avoid two extremes: granting full autonomy too quickly, or keeping the agent in assist mode for too long even when the process is ready.
Practical Implications
After reading this article, there are several decisions to make. First, determine the guardrail points at runtime. Do your guardrails only filter output, or do they already control input, retrieval, tool access, action execution, and output? Second, decide on the policy engine architecture. Which rules should be deterministic, which areas can use classifiers, and how will policy decisions be recorded for audit? Third, define risk tiers and approval thresholds. Which actions can be auto-executed, which need monitoring, which require approval, and which must remain human-led? Fourth, design a truly usable approval workflow. Will the approver receive sufficient context, evidence, risks, and alternatives to make a quick and responsible decision? Fifth, prepare escalation and remediation paths. When should the agent stop, to whom does it escalate, and how is rollback or compensation action performed if the result is wrong?
There are several danger signals that this topic isn't ready to scale. The agent can already call production tools, but guardrails are still limited to prompts and content filters. Human approval is used for almost all cases because the company doesn't trust the runtime policy yet. There is no formal record of why an action was allowed, denied, or escalated. Human reviewers receive approval requests without sufficient evidence. There is no rollback path if the agent incorrectly changes a business state. Business, technology, risk, and audit teams have different definitions of "safe for automation." Agent autonomy is increased due to efficiency pressure, not because of proven controls and quality.
A reflective question for CIOs, COOs, CHROs, and transformation leaders: if tomorrow one of your company's agents takes a wrong action that has a real impact on a customer, employee, or transaction, can you quickly explain which guardrail should have stopped it, which policy allowed it, who should have approved it, and how the system would recover? If the answer isn't clear, then the next focus shouldn't be adding more agents, but strengthening control and runtime governance first.