Identity and Access Control for AI Agents
Imagine your finance team is preparing an agent to assist with the monthly book close process. This agent can read open journals, check reconciliations, and draft comments for outstanding items. Everything runs smoothly in the demo. But when the agent starts actually sending draft adjustments to the ERP, a question suddenly brings the team to a halt: who is actually performing this action? Is the agent acting on behalf of a specific controller? Or as an independent system? And if the result is wrong, who is responsible?
This question is not merely technical. It strikes at the core of how a company views agents: as anonymous helpers, or as digital actors that need to be treated on par with humans and other applications in terms of control and accountability.
Many organizations today are already quite advanced in thinking about models, prompts, and API integrations for their agents. But when use cases start moving from demo to production, one thing is often overlooked: the agent lacks a clear identity. It runs on a generic service account, with permissions that are too broad, and logs that are insufficient to explain the provenance of its actions. Consequently, when an agent starts reading invoices, opening tickets, changing order statuses, or triggering procurement workflows, the company cannot answer basic questions: what identity is the agent using, on whose behalf is it acting, what permissions does it have, and in what workflow context did the action occur?
For the enterprise, this is not a minor detail. Without an explicit identity and access model, auditability, accountability, and runtime governance will collapse precisely when the agent starts delivering real value.
Agents Are Not Anonymous Scripts
In traditional enterprise architecture, we are accustomed to recognizing several types of actors: humans, applications, service accounts, and scheduled processes. Agentic AI adds a new category: digital actors that can reason, choose tools, and act across multiple steps. Therefore, agents should not be treated like anonymous scripts that happen to run in the background.
An agent must have a clear identity because the company needs to know three fundamental things: who is performing the action, under whose mandate the action is taken, and in what workflow the action occurs. Without these three elements, enterprise control becomes blurred.
Consider a procurement agent that receives an intake request, checks contracts, and then creates a draft purchase request in the ERP. If that action is recorded only as activity from a single generic service account, then when a problem arises, the company cannot distinguish whether the action was triggered by a specific user, was part of a scheduled workflow, was an autonomous action by the agent due to a specific event, or involved access misuse. The same applies in finance close, customer operations, or IT operations. When agents start touching business state, their identity must be traceable just like the identity of a human or any other application.
Agent identity is also the foundation of accountability. In the old operating model, accountability typically follows the human: analyst, approver, supervisor, or system owner. In the agentic model, some actions shift to digital labor. That does not mean accountability disappears. Quite the opposite: accountability must be made more explicit. The company needs to be able to answer: what function does this agent belong to, who is its business owner, who is its technical owner, what tools is it allowed to use, and what are the boundaries of its permitted actions? Without this, the organization will face a dangerous situation: the agent takes real actions, but there is no control model commensurate with its impact.
Furthermore, identity also determines the trust boundary. An agent interacting with internal employees is different from an agent serving external customers. An agent that only reads a knowledge base is different from an agent that can change payment statuses. An agent operating within a verified user context is different from an agent serving a public or semi-public channel. Therefore, an agent's identity is not just a technical name. It determines what data can be accessed, what tools can be called, and what level of oversight is required. If all agents are treated the same, the company will tend to fall into one of two extremes: too permissive or too restrictive. Both are bad.
Static Role-Based Permissions Are Not Enough
Once the agent's identity is clear, the next step is authorization. This is where many organizations make old mistakes in a new form: granting access based on static roles, and then hoping that is secure enough. For agentic AI, this approach is too coarse.
Agent permissions should not be determined solely by the agent's role, but also by context: who the user being represented is, what task is being executed, what data is being accessed, the sensitivity of the information, and the risk of the action to be taken. This approach is known as context-aware authorization.
Take a simple example in accounts payable. An agent may read invoices, POs, and goods receipts to analyze mismatches. The agent may draft resolution recommendations. But the agent should not automatically be allowed to change payment status or release payment blocks. Why? Because the final action has a much higher risk profile than simply reading or recommending.
An example in HR operations: an agent may read onboarding status and document completeness, and draft notifications to the hiring manager. But the agent should not change compensation data or employment status without proper approval. An example in customer operations: an agent may view ticket history and customer entitlements, and prepare low-value refunds if policy conditions are met. But refunds above a certain threshold must stop for supervisor review.
In all these examples, static roles are insufficient. What is needed is authorization that considers runtime context.
Practically, there are four dimensions of context that should be evaluated each time an agent calls a tool or accesses data. First, the user or originating principal context: is the agent acting on behalf of a specific employee, a specific team, or a specific business function? If so, the agent's rights should not exceed the originating mandate without a clear reason. Second, the task or workflow context: is the agent performing analysis, drafting, transaction execution, or approval support? Access rights for each stage must differ. Third, the data context: is the data being accessed public, internal, confidential, or highly sensitive? Is it related to payroll, vendor banking details, strategic contracts, or protected customer information? Fourth, the action risk context: reading data, creating a draft, executing a change, and approving a transaction are four different risk levels. Their controls should not be equated.
Why is this important? Because an over-permissioned agent is one of the most real risks in the enterprise. The temptation is great: to make a pilot succeed quickly, teams often grant broad access to an agent. In the short term, this speeds up the demo. In the long term, it creates over-permissioned agents that are difficult to audit and dangerous when scaled. The healthier principle remains the same as for human and application security: least privilege. The difference is that with agentic AI, least privilege must be applied more dynamically because agents work across contexts.
Delegated Authority: On Whose Behalf Does the Agent Act?
Many agent actions do not truly belong to the agent. The agent often acts on behalf of someone or some function. Therefore, the company needs to clearly distinguish between the agent's identity and the source of its authority. This is the essence of delegated authority.
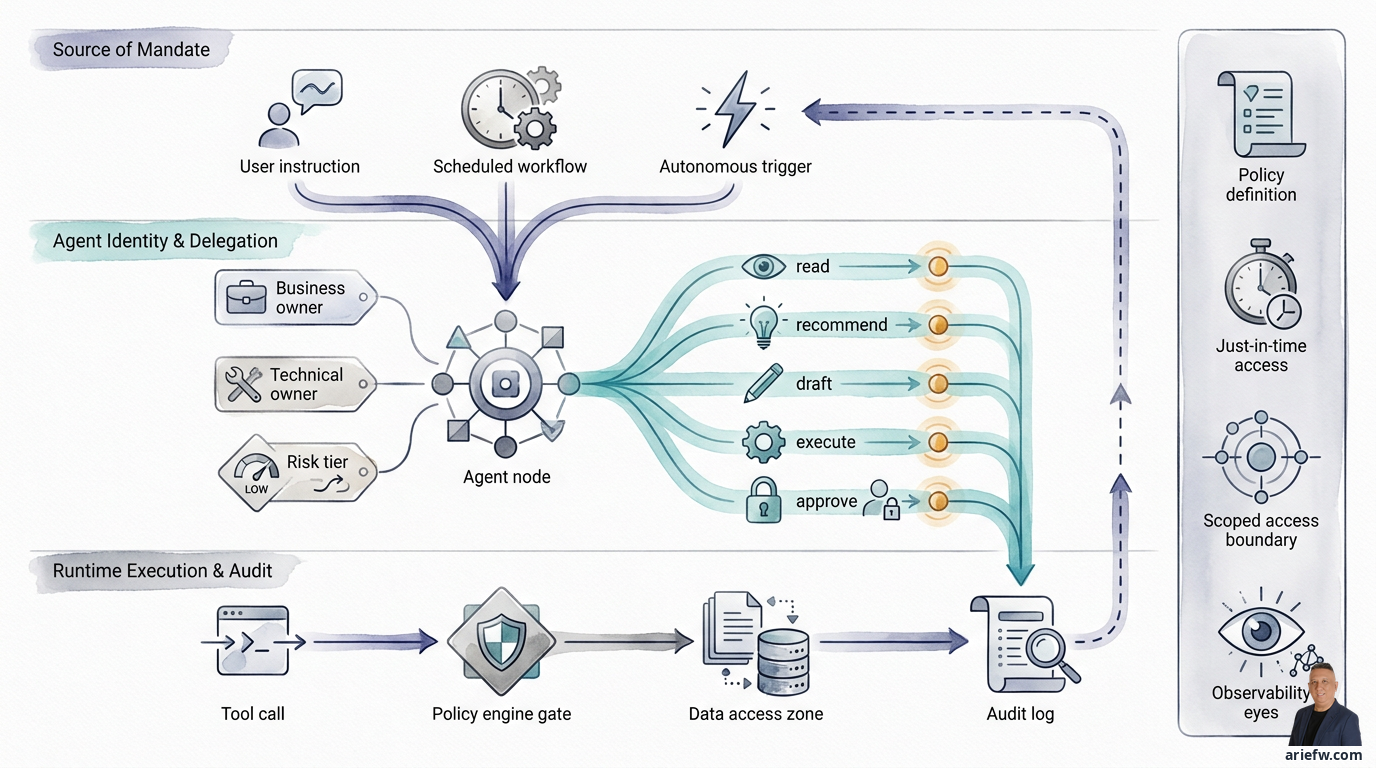
In enterprise practice, an agent's actions typically originate from one of three sources. First, user instruction: for example, a buyer asks a procurement agent to check contracts and create a draft purchase request. In this case, the agent acts on explicit user instruction. Second, a scheduled workflow or formal business process: for example, a finance close agent checks for outstanding exceptions every night and sends follow-ups. Here, the mandate comes from an organizationally approved workflow. Third, an autonomous event-based trigger: for example, an IT operations agent receives an event that a specific service has failed, then runs diagnostics and opens an incident. Or a supply chain agent receives a shipment delay event and prepares mitigation options. In this case, the action is triggered by an event, not a direct human command.
These three sources of mandate must be distinguished in the system. If not, the audit trail will lose critically important context.
Healthy delegated authority must have boundaries. At a minimum, delegation needs to be revocable at any time, time-bound, scoped to specific tasks, and, where relevant, limited by transaction value. An example in procurement: the agent may create draft requests for standard spend categories as long as the value is below a certain limit. Above that, the agent may only recommend. An example in customer service: the agent may process goodwill credits up to a certain value for customers meeting specific criteria. Beyond that, the agent must stop. An example in IT operations: the agent may execute low-risk remediation runbooks on non-production environments or specific services, but must not make material production changes without approval.
One common weakness is that delegation is understood only in business terms but is not translated into technical controls. Yet the system must be able to clearly record who granted the mandate, which agent executed it, when the mandate was valid, what tools were used, and whether the action complied with policy. Without this, the company will struggle to distinguish between legitimate actions, actions outside the mandate, and actions that should no longer be valid.
Implementation Patterns for the Enterprise
To ensure identity and access control for agents do not remain mere principles, companies need to translate them into operational implementation patterns.
First, give every agent a formal service identity. Every agent entering production should have its own service identity, not share a generic account. This identity must be registered, have an owner, and be connected to the enterprise agent catalog. At a minimum, the required metadata includes: agent name and purpose, business owner, technical owner, process domain, allowed tools, risk tier, and lifecycle status. This is important so that the agent is treated as an operational asset, not an experiment left to run on its own.
Second, bind every tool call to a policy engine. An agent should not be free to call a tool simply because the tool is available. Every tool call should pass through a policy engine that evaluates the agent's identity, the user's identity or mandate source, the type of action, the data object or transaction, the workflow context, and applicable approval rules. With this pattern, control occurs not just at login, but at runtime, precisely when the agent is about to act. This is critical because agentic AI is dynamic. A single session can include multiple steps with different risk levels. Authorization must follow those steps, not just the initial identity.
Third, separate permissions by action type. One of the most useful designs is to separate access rights into action layers: read, recommend, draft, execute, and approve. This separation is far more relevant for agents than traditional application access models. An example in finance: read to view journals, reconciliations, and evidence; recommend to suggest exception treatments; draft to prepare commentary or draft adjustments; execute to post specific authorized actions; approve, which almost always remains with humans for material items. An example in procurement: read to view contracts, vendors, and policies; draft to create purchase requests; execute to send requests to the workflow; approve, which remains with human approvers. With this separation, companies can gradually increase agent autonomy without opening all rights at once.
Fourth, use just-in-time and scoped access where possible. For more sensitive actions, access should not be permanently active. It is safer if the agent obtains temporary access, only for a specific task, and that access expires after the task is complete. This approach helps reduce the blast radius in case of configuration errors or misuse.
Fifth, store audit logs that truly explain the action. Audit logs for agents are not sufficient if they only record that an API was called. Logs worthy of the enterprise must link the user or mandate source, the agent's identity, the policy decision, the tool call made, the input used, the output generated, any approvals that occurred or were bypassed, and the final state change in the system. This is the minimum trail to answer audit questions, investigate incidents, or evaluate agent quality. If the company cannot reconstruct this chain, then the agent is not truly ready for production scale.
How These Patterns Work in Practice
In finance close, the close orchestration agent has its own service identity. It may read reconciliation status, open journals, and evidence. It may draft commentary and follow-ups. But for material adjustments, the policy engine mandates human approval. The log records the controller who gave the mandate, the agent that prepared the draft, the policy applied, and the final journal status.
In procurement intake-to-PO, the procurement agent acts on behalf of the requester or buyer depending on the process stage. It may read contracts, vendor master data, and category policies. It may create draft requests for standard categories. If the transaction value exceeds a limit or the vendor is not yet approved, the tool call for execution is rejected or diverted to an approval workflow.
In customer operations, the service agent has its own identity and operates within a verified customer context. It may read ticket history and entitlements. It may execute small goodwill credits if policy conditions are met. For VIP customers, recurring cases, or values above a threshold, the agent only provides recommendations and waits for a supervisor.
In IT operations, the incident response agent receives an event from the observability platform. It may run diagnostics and low-risk remediation on specific services. For actions touching critical production, the policy engine requires approval from the on-call engineer. All steps are recorded: the originating event, the acting agent, the runbook called, the result, and the system state change.
When These Patterns Are Not Yet Appropriate
Not all organizations are ready to immediately implement a mature model. There are several danger signals indicating that an agent is not yet ready to scale. The agent still uses a shared service account without a unique identity. Permissions are granted too broadly just to get the use case working. There is no separation between rights to read, draft, and execute. Delegated authority is not explicitly recorded. Tool calls do not pass through a policy engine or runtime control. Audit logs only record the final output, not the decision chain. There is no quick way to revoke an agent's access in the event of an incident. The business owner does not know exactly which tools and data the agent is using.
If several of these symptoms are still present, scaling agentic AI will amplify risk faster than value.
Agents with execution autonomy are also not appropriate for domains that touch material transactions without clear rollback, where policy definitions cannot yet be translated into runtime rules, where data is still unstable, or where process ownership is still unclear. In such conditions, it is safer to start with read, recommend, and draft while first strengthening identity, policy, and logging.
Questions to Take Home
After understanding this topic, there are several decisions that should be made now. First, determine the agent identity model in your company: will every agent have a formal service identity, a clear business owner, a technical owner, and a defined risk tier? Second, decide on the authorization model to be used: will the company continue to rely on static roles, or move to context-based authorization for every tool call? Third, define the delegated authority model: when does the agent act on behalf of a user, on behalf of a workflow, or due to an autonomous event? How is delegation limited, revoked, and audited? Fourth, separate agent permission levels: are access rights already differentiated between read, recommend, draft, execute, and approve? Fifth, determine the minimum auditability standard: can the company link the user, agent, policy decision, tool call, input, output, and final state change?
If tomorrow an auditor, regulator, or risk committee asks, "who performed this action, under whose mandate, and why did the system allow it?", can your company already answer with complete evidence—not just a verbal explanation? If the answer is not yet definitive, then before adding more agents, the next priority is not a new feature. The priority is building the identity, authorization, and delegation that make an agent worthy of trust as an enterprise actor.