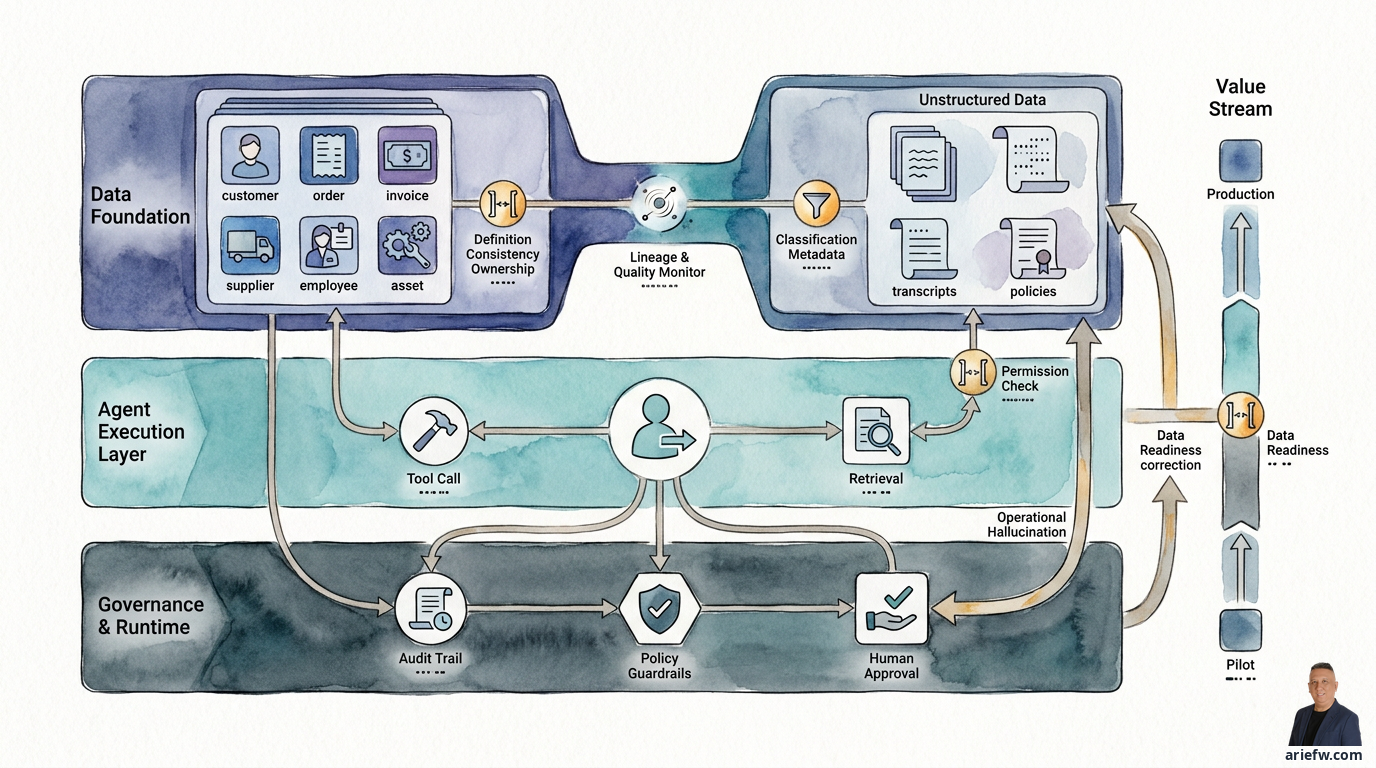
Data Foundation for Agentic AI
Imagine your finance team has built an agent that can help with the month-end close process. The agent connects to the ERP, can read journal entries, and even starts drafting reconciliations. In the demo, everything runs smoothly. But when it's used for the actual close period, the agent starts misreading invoice statuses, recommending the wrong accounts, and escalating exceptions that have already been resolved. The finance team ends up rechecking everything from scratch.
What went wrong? It wasn't the model. It wasn't how the agent connected to the system. The problem lies in the data that fuels the agent itself.
Many companies focus too heavily on models, agent frameworks, or platforms. Yet in an enterprise context, models are increasingly easy to buy or replace. What is far harder to replicate is the company's context: internal data definitions, process structures, operational policies, decision history, and relationships between business entities. All of this lives in data, both structured and unstructured.
If agentic architecture is the new execution engine, then the data foundation is both the fuel and the navigation system. Without a strong data foundation, an agent can sound convincing but be operationally wrong. It can provide answers that seem reasonable, yet pick the wrong vendor, misread an order status, or misinterpret a policy.
The difference between a demo agent and one fit for daily operations is usually not about conversational quality. The difference lies in data readiness.
Why Data Matters More Than the Model
In AI discussions, the model often takes center stage because it's the most visible. People compare reasoning capabilities, latency, or output quality. All of that matters. But for the enterprise, the model is just one component. Real business value emerges when the model operates on top of the correct company context.
Models can be bought; company context cannot
Companies can purchase access to frontier models, use open-source models, or switch model vendors over time. However, no vendor can instantly provide your company's definition of an "active customer," the invoice mismatch tolerance rules for a specific business unit, the relationships between contracts, orders, shipments, and disputes, or the history of exceptions that typically arise during finance close.
An agent that doesn't understand this context will fail at the most critical point: operational execution.
Consider procurement. An agent might be able to read a purchase request and suggest a processing path. But if supplier master data is inconsistent, spend categories are non-standard, and local policies are scattered across various documents, the agent could route the request down the wrong path. Linguistically, it sounds smart. Operationally, it creates rework.
Another example is customer operations. An agent can summarize a customer's history well. However, if entitlement status, SLAs, and contract exceptions are unavailable or out of sync, the agent might make service promises that don't align with the contract. This isn't just a technical error; it can become a commercial and reputational problem.
An agent without accurate data produces operational hallucination
The term hallucination is often used to describe a model fabricating facts. In the enterprise, a more dangerous form is operational hallucination: output that sounds credible but is wrong regarding business reality.
For example, a finance agent concludes an invoice is unpaid when the status in the ERP has already changed. Or an HR agent answers a leave policy question based on an outdated document. Or an IT operations agent recommends a runbook that is irrelevant because the CMDB is inaccurate. Or a supply chain agent suggests rerouting without understanding actual stock constraints.
The problem isn't just answer accuracy. The problem is that the agent starts influencing actions, priorities, and decisions.
Data readiness is the differentiator between pilot and production
Many agentic pilots appear successful because data is cleaned manually, the scope is narrowed, documents are selected one by one, and the project team monitors results intensively. Once in production, conditions change. Data comes from many systems, business definitions are not uniform, documents are messy, permissions are complex, and exceptions are far more numerous.
At this point, companies realize that data readiness is not a supporting task. It is a prerequisite for scaling.
Therefore, the more important question than "what model are you using?" is often: which business data serves as the source of truth, who owns it, how consistent are its definitions, how is its quality monitored, and how does the agent access it without violating controls?
Structured Data: The Foundation for Action Agents
If an agent is going to act within enterprise systems, it needs access to structured data that represents the official state of the business. Structured data typically includes core entities like customer, order, invoice, product, employee, supplier, asset, contract, ticket, and financial transactions. This is the data closest to operational actions. When an agent checks a status, validates a condition, or prepares an action, it almost always relies on structured data.
More than just tables; consistent business objects
A common mistake is assuming structured data is sufficient because the company already has an ERP or CRM. In reality, the existence of a system does not automatically mean the data is ready for an agent.
To be useful for agentic AI, structured data needs at least six characteristics.
Consistent business definitions. What does "active customer" mean? When is an order considered "fulfilled"? What is the difference between "supplier approved" and "supplier enabled"? If these definitions differ across functions or countries, the agent will struggle to make consistent decisions. In record-to-report, for example, definitions of sensitive accounts, materiality, or reconciliation status must be clear. If not, a close orchestration agent will prioritize the wrong items.
Clear ownership. Every data domain must have a business owner, not just a technical administrator. It must be clear who is responsible for the quality of customer master, vendor master, employee data, or product hierarchy. Without ownership, data problems will continue to be dismissed as "system issues," even though their impact directly affects agent operations.
Traceable lineage. An agent needs to work with data whose origins are clear. If a field in a dashboard comes from layered transformations without good lineage, it's difficult to ensure the agent is reading the correct business state or just a stale derivative. This is especially important for use cases touching operational decisions, not just insights.
Monitored quality. Data quality cannot be assumed. Companies need to monitor completeness, uniqueness, consistency, timeliness, and validity. In accounts payable, for example, if the vendor master has duplicates or tax IDs are incomplete, an invoice resolution agent will frequently misattribute cases. In HR operations, if the organizational structure is not up-to-date, an onboarding agent could misdirect approvals or notifications.
Sufficient semantics. Structured data for an agent is not enough if it's just "stored." It must have meaning that can be understood across systems. This is where enterprise data models, canonical models, or master data management become relevant. More mature organizations also emphasize a consistent enterprise data model so that agent decisions don't vary depending on the source system.
Secure access interface. Agents should not read core tables indiscriminately. Access to structured data must go through an interface that maintains permissions, audit trails, stable schemas, and policy enforcement. In other words, structured data for agents must be accessed like an enterprise capability, not a technical shortcut.
Enterprise examples: finance, procurement, and shared services
In finance close, an agent assisting with the close needs data like reconciliation status, open journals, aging exceptions, close calendars, and account mappings. If this data is consistent and has clear lineage, the agent can prioritize exceptions, prepare commentary, and orchestrate follow-ups. If not, the agent only adds noise.
In procurement, an intake-to-PO agent needs supplier master data, spend categories, active contracts, budget status, and purchase history. If the supplier master is chaotic or categories are non-standard, the agent will frequently choose the wrong purchasing path. In this domain, master data quality often matters more than model sophistication.
In shared services, structured data is often scattered across functions. A case management agent might need to combine ticket data, SLAs, transaction status, and interaction history. If identifiers across systems are not synchronized, the agent will struggle to build a unified view of a case.
When structured data isn't enough
Structured data is critical for action. But much enterprise context doesn't live in transaction tables. Policies, contracts, emails, call transcripts, SOPs, and case notes often determine decisions. This is where unstructured data comes in.
Unstructured Data: Where Real Context Often Hides
Many organizations only realize the value of unstructured data when they start building agents. Until then, documents and communications were often treated as passive archives. In agentic AI, these sources become an active context layer.
Unstructured data typically includes policy documents, SOPs, contracts, emails, call transcripts, chat history, images or scanned documents, meeting minutes, knowledge articles, and case handling notes. For many enterprise workflows, this is where the reasoning behind decisions resides.
In customer operations, the ticket status might be in the CRM, but the customer's emotional context, promises made, or root cause often reside in transcripts and conversation history. In procurement, the supplier master is in the system, but commercial terms and contract exceptions are in documents. In HR, employee data is in the HRIS, but local policies, FAQs, and program exceptions often live in portals, PDFs, or emails. In IT operations, alerts are on the observability platform, but runbooks, postmortems, and historical workarounds are often scattered across wikis, ticket notes, and chat channels.
Agentic AI unlocks new value from unstructured data because the agent doesn't just "search for documents." It can read multiple sources simultaneously, compare document contents, connect historical context with transaction state, and then act or escalate based on that context.
Unstructured data needs a pipeline, not just document upload
Many early implementations stop at "upload documents to a vector store." For the enterprise, that's too shallow. Unstructured data needs to be managed through a disciplined pipeline.
Ingestion. Documents must come from clear sources: official repositories, email archives, call center platforms, contract management systems, knowledge bases, or curated file shares. If ingestion is uncontrolled, the agent will pull context from non-authoritative sources.
Classification. Not all documents carry the same weight. Companies need to distinguish between official policies, drafts, expired documents, active contracts, informal communications, and reference materials. Without classification, an agent could cite an old document as if it were still current.
Chunking and enrichment. Long documents need to be broken into units that can be retrieved relevantly. But chunking cannot be blind. Metadata like document owner, effective date, version, region, function, confidentiality level, and active/inactive status is often more important than the embedding itself.
Embeddings and retrieval. Embeddings enable semantic search, but enterprise retrieval must go beyond similarity search. It needs to consider metadata, permissions, and workflow context. An HR policy for Indonesia should not appear for an employee case in another country just because the language is similar.
Retention and lifecycle. Unstructured data also has a lifespan. Old emails, sensitive transcripts, or expired contracts should not remain active context indefinitely without rules. Retention policies must be applied so the agent doesn't build decisions from memory that should no longer be relevant.
Important trade-offs with unstructured data
There is a temptation to feed all documents into the agentic system. This is rarely wise. The more documents included without curation, the higher the noise, the greater the risk of retrieval errors, the harder it is to maintain permissions, and the more expensive the processing cost.
Therefore, a healthier strategy is to start with an authoritative, high-value corpus. For example, official SOPs for shared services, active contracts for procurement, verified knowledge articles for the service desk, or curated HR policies. Not every file the company has ever created.
Data Governance for Agents: From Policy to Runtime
At this stage, many companies feel they already have data governance: data classification, access policies, data owners, retention policies. The problem is that traditional governance often stops at documents, committees, or manual controls. For agentic AI, governance must be translated into runtime.
The key question is not just "who can access this data?" but who can access this data through an agent, for what purpose, in what workflow, with what level of autonomy, and does that access result in an action or just an insight.
Permissions must apply during retrieval and tool calls
This is a critical point. If an agent pulls context from documents or structured data, permissions must be checked at the time of retrieval, not after the answer is generated.
An HR agent must not pull compensation data if the user is not authorized. A procurement agent must not expose strategic contracts to a regular requester. A finance agent must not display data for a specific entity outside the user's scope. A customer service agent must not access sensitive history without proper identity verification.
The same applies to tool calls. The right to read an order status is different from the right to modify an order. The right to view a vendor is different from the right to modify the vendor master.
Governance for agents requires context of purpose
In the enterprise, data access isn't just about identity; it's also about purpose. An agent might legitimately read invoice data to resolve an AP exception, but it is not legitimate to use that same data to create a summary shared with irrelevant parties.
Therefore, agentic governance needs to link the agent's identity, the identity of the user or process it represents, the business purpose, and the workflow in progress. This is more complex than traditional application access models, but also more realistic.
Audit trails must explain decision context
For an agent, a good audit trail is not enough if it only records that "access occurred." It must be able to explain what data was retrieved, from which source, under what permission, in what workflow, and how that data influenced the decision or action. This is important for risk, compliance, and operational improvement. If an agent gives a wrong recommendation, the company must be able to trace whether the problem was data quality, incorrect retrieval, missing metadata, or an unenforced policy.
Signs that data governance is not ready for agents
Some common symptoms include: data owners don't know their data is being used by an agent; official documents and drafts are mixed without clear versioning; permissions in the knowledge layer are looser than in the source system; there is no metadata about effective dates or policy regions; an agent can access data because of a generic service account; and there is no easy way to deactivate a corpus or specific data source during an incident.
If these symptoms exist, scaling agentic AI will increase risk faster than value.
Strengthening the Data Foundation Before Scaling
After understanding the importance of the data foundation, there are several decisions to make now. First, determine the priority data domain for your first agentic use case. Don't start with "all company data." Choose the domain closest to your priority value stream, such as customer, invoice, supplier, employee, or ticket. Second, decide on the source of truth for structured data and the authoritative corpus for unstructured data. The agent should not be left to choose from an ambiguous data landscape. Third, establish ownership across data and workflows. It must be clear who owns the business data, who owns the knowledge corpus, and who is responsible for permissions and quality monitoring. Fourth, build runtime governance, not just document governance. Permissions, metadata, retention, and policies must apply during retrieval and tool calls. Fifth, choose a curation strategy for unstructured data. Start with a high-value, official corpus; don't include all documents just for the sake of coverage.
To assess your company's readiness, check whether the primary structured data domain for your priority use case has been identified; business definitions for key entities are reasonably consistent across functions; there is a clear owner for customer, supplier, employee, order, invoice, or other relevant domains; key data quality is monitored at least for completeness, consistency, and timeliness; the agent accesses structured data through an interface that maintains permissions and audit trails; the unstructured data corpus the agent will use has been curated and distinguished from draft or expired documents; important metadata like version, effective date, region, and confidentiality classification is available; retrieval applies permissions consistent with the source system; retention policies for documents, transcripts, and interaction history have been considered; and there is sufficient logging to trace what data the agent used to generate recommendations or actions.
Watch for danger signals that this topic is not ready to scale. If the AI team says "we'll clean the data later"; if core master data is still being debated across functions; if the agent pulls answers from documents with unclear official status; if there is no version or effective date metadata on policies; if the agent's service account has overly broad access across data domains; if retrieval from the knowledge base does not respect user permissions; if there is no adequate data lineage for important fields; and if the business has not appointed an owner responsible for the quality of the context the agent uses, then scaling will amplify risk.
Before expanding agentic AI, ask honestly: is our company building an agent that truly understands how the business works, or are we just building a smart interface on top of data that isn't yet trustworthy? If the answer is the latter, the next priority is not adding new agents. The priority is strengthening the data foundation so that existing agents are trustworthy, auditable, and scalable.