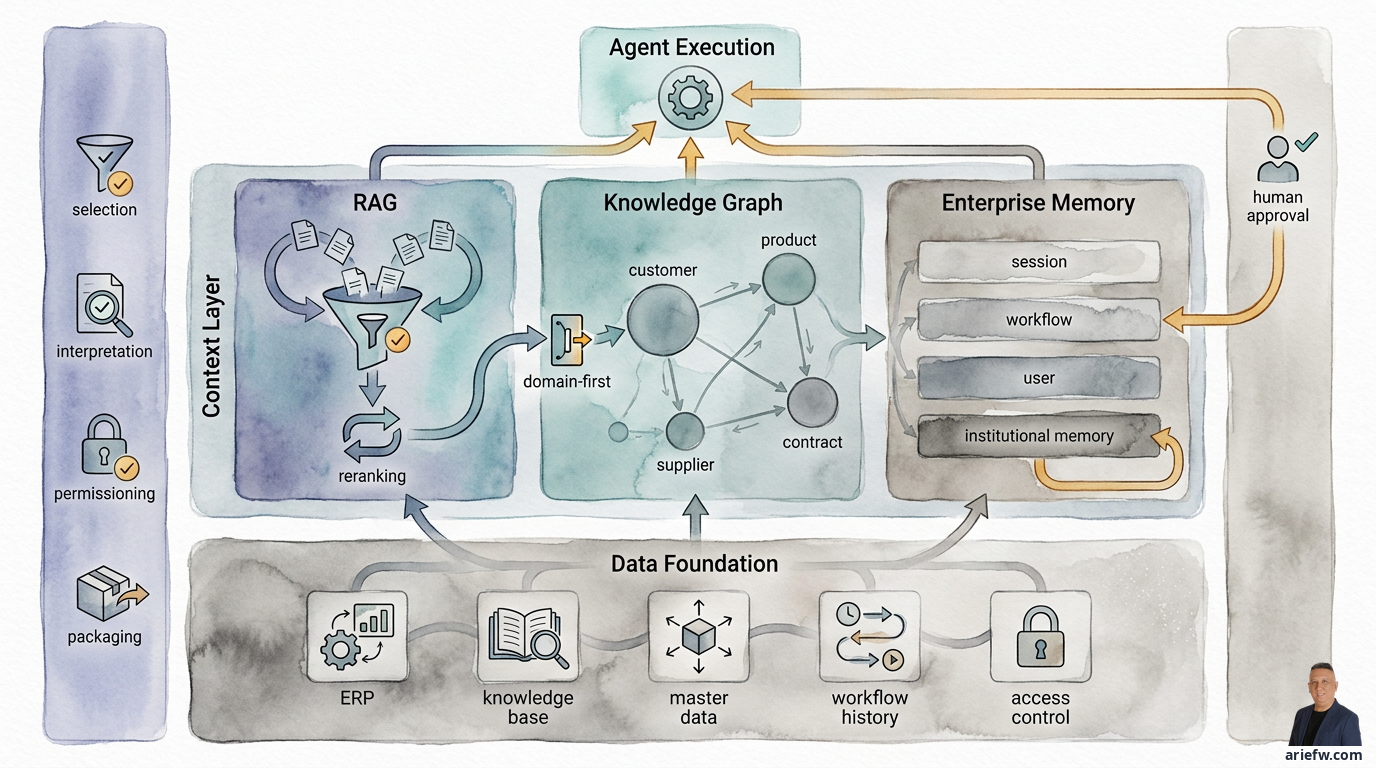
Context Layer: RAG, Knowledge Graph, and Enterprise Memory
Imagine your finance team is trying to use an agent to help with the monthly book close process. The agent can access data, but the results are odd: sometimes it pulls accounting policies that are no longer valid, sometimes it mixes data from different entities, and sometimes it forgets that a certain step has already been completed. Your team starts to doubt—can this agent really help, or is it just adding to their workload?
Situations like this aren't because the AI model is weak. The problem is more fundamental: the context provided to the agent is too raw, too broad, or uncontrolled. Many teams try to patch this deficiency with ever-longer prompts, increasingly complex instructions, or more aggressive retrieval. The results are unstable. Sometimes the agent seems smart, sometimes it retrieves the wrong document, sometimes it forgets a previous decision, and sometimes it violates access boundaries.
For an enterprise, context isn't just "supplementary information." Context is an operational layer that determines whether an agent can make decisions that are relevant, safe, and accountable.
What is Meant by the Context Layer
When an agent works, it almost never relies on just one data source. To resolve a single case, an agent might need to combine transaction status from an ERP, policies from a knowledge base, entity relationships from master data, decision history from previous workflows, and access boundaries based on user or process identity. All of this cannot be provided raw.
The context layer is the layer that transforms data and knowledge into context ready for decision-making. Its work encompasses four things. First, selection: choosing information that is truly relevant for a specific task. Second, interpretation: giving business meaning to information, for example, distinguishing an active policy from an old draft. Third, permissioning: ensuring the agent only sees context it is actually allowed to access. Fourth, packaging: presenting the context in a form the agent can use efficiently.
Without these four tasks, agents tend to fall into two bad patterns. First, over-reliance on long prompts that try to cram all instructions and context in at once. Second, over-reliance on uncontrolled retrieval, causing the agent to pull in too much or too little information.
Why the Context Layer is Its Own Architectural Domain
In a simple copilot, context is often considered sufficient if the model can search documents. In an agentic enterprise, that's not enough. The agent must understand the current operational situation, interpret applicable rules, remember steps already taken, and act within its authority boundaries.
Look at the finance close example. An agent helping resolve exceptions can't just read the close SOP. It also needs to know which entity is being processed, which accounts are material, what exceptions have already been opened, who made previous decisions, and whether similar cases were resolved with a specific treatment before.
Consider the procurement example. An intake-to-PO agent can't just read the purchasing policy. It needs to know the spend category, relevant active contracts, approved suppliers, approval thresholds, and the exception history for that business unit.
The context layer is the bridge between the data foundation and agent execution. Without this bridge, the agent operates on information insufficient for making good decisions.
RAG for Controlled Knowledge Retrieval
The first and most commonly used component of the context layer is retrieval-augmented generation, or RAG. Its role is clear: help the agent retrieve relevant documents or pieces of information from the enterprise knowledge base, and then use that information to answer, reason, or prepare an action.
For many use cases, this is a reasonable entry point. Service desks needing to read knowledge articles, HR operations needing to answer policy questions, procurement needing to reference SOPs and contracts, legal ops needing to compare clauses, or finance needing to pull accounting guidance.
However, good RAG is far more difficult than just dumping documents into a vector database. Its quality is determined by upstream design, not just the search model.
Six factors are usually the most critical. First, data sources. If the corpus contains a mix of official policies, old drafts, informal emails, and files with unclear ownership, retrieval will produce noise. RAG is only as good as the quality of the corpus fed into it.
Second, chunking. Long documents must be broken into units that can be retrieved relevantly. Chunks that are too large make retrieval fuzzy. Chunks that are too small break the context. For the enterprise, chunking often needs to follow the structure of business documents, not just character counts.
Third, metadata. Metadata is often more important than embeddings. Effective dates, document versions, region, function, confidentiality level, active or inactive status, and document owner help make retrieval far more precise.
Fourth, search strategy. Similarity search alone is often insufficient. Many better implementations combine semantic search, keyword search, metadata filtering, and sometimes query expansion based on workflow context.
Fifth, reranking. Initial retrieval results need to be reordered so the most relevant and authoritative pieces appear first. This is especially important when several documents look similar but have different business statuses.
Sixth, answer evaluation. RAG should not be judged solely on whether "the answer sounds good." Companies need to test whether the agent retrieved the correct document, cited a still-valid policy, didn't mix conflicting sources, and produced an answer that genuinely aids decision-making.
One of the most dangerous mistakes is building a RAG that is technically clever but blind to permissions. An agent should not retrieve a document just because it is semantically relevant. The agent must also check whether that document is accessible to the user or workflow it represents. An HR agent should not pull sensitive compensation documents for all employees. A procurement agent should not open strategic contracts to a regular requester. Permission-aware RAG means access control is applied during retrieval, not after the answer is formed.
Knowledge Graph for Business Relationships Not Captured by Documents
If RAG helps an agent find what is written, then a knowledge graph helps an agent understand what is related to what. A knowledge graph explicitly represents business entities and relationships. Entities can be customers, products, suppliers, contracts, assets, locations, policies, risks, employees, or cases. Relationships can be that a customer has a specific contract, a supplier provides components for a specific product, or a product is subject to a specific policy.
For enterprise agents, graphs are useful because many operational decisions cannot be made from a single document or table. Decisions often depend on a network of relationships.
The clearest example is in a supply chain control tower. When a shipment is delayed, the agent needs to understand which customer order this shipment is linked to, what products that order contains, which suppliers those products depend on, what SLA or priority that customer has, which locations are affected, and whether there are specific escalation contracts or policies. All of this is easier to model as a graph than as a pile of documents.
Another example is in compliance review. An agent needs to assess whether a specific transaction, vendor, contract, and policy are related to certain risk categories. If these relationships aren't explicit, the agent will struggle to reason consistently.
Many organizations avoid knowledge graphs because they imagine a large, expensive, and time-consuming enterprise-wide project. That's not necessary. A more realistic approach is to start with domain graphs for priority use cases. A graph for vendor–contract–category–policy relationships in procurement, a graph for customer–product–ticket–SLA in customer service, or a graph for entity–account–journal–control in finance close.
A domain-first approach offers three advantages: it delivers value faster, is easier for business owners to validate, and is simpler to govern than trying to map the entire company at once.
Graphs are very useful, but not always necessary. A graph is typically worthwhile when entity relationships truly affect decisions, workflows are cross-domain, and reasoning is insufficient if relying only on documents. A graph may not be worthwhile yet if the use case is still simple and document-based, business entities are not yet stable, or the organization lacks sufficiently clear data ownership.
Enterprise Memory: Remembering Without Storing Fallacies as Facts
The third component of the context layer is memory. Memory allows an agent to remember context that isn't always available in a single prompt or query. This is important because much enterprise work spans multiple steps, multiple days, and even multiple teams.
However, memory in the enterprise must be understood with discipline. Not everything needs to be remembered, and not all memories should be treated equally.
There are four types of memory that need to be distinguished. First, session memory: the context of a conversation or interaction within a single session. For example, the agent still remembers that the user is discussing a specific invoice. Session memory is useful for keeping a conversation coherent, but usually doesn't need to be stored for long.
Second, workflow memory: memory about the status of an ongoing task. What steps have been completed, what documents have been reviewed, what decisions have been made, who has given approval, and what exceptions are still open. This is critical for workflows like finance close, procurement case management, or incident response.
Third, user memory: preferences or specific context about a user, such as a preferred report format or certain work patterns. User memory can improve the experience but must be managed carefully as it touches on privacy and fairness.
Fourth, institutional memory: longer-lasting organizational learning. Patterns of frequent exceptions, treatments that have worked before, human feedback on agent recommendations, and recurring operational knowledge. Institutional memory is most valuable for continuous improvement, but also most risky if not curated.
Without memory, agents tend to operate like they have operational amnesia. Every time a case is opened, the agent starts from scratch. Handoffs between sessions are poor, previous decisions are not considered, human feedback is lost, and long workflows become fragile.
In IT operations, an agent handling recurring incidents should be able to remember which runbook worked before, who the relevant approvers are, and what system dependencies are often the root cause. In collections, an agent should remember previous promise-to-pay arrangements, customer responses, and follow-up actions already taken, so it doesn't send contradictory communications.
In the enterprise, memory should not be treated like free-form notes without rules. There are four minimum disciplines. Retention: it must be clear what is stored, for how long, and when it is deleted. Privacy: memory can contain sensitive data, so its storage and use must adhere to strict privacy and access policies. Audit: the company must be able to explain what memory the agent used to produce a specific recommendation or action. Correction: memory must have a correction mechanism. If the agent stores an incorrect conclusion, human feedback must be able to correct or flag that memory.
Memory is not yet ready to scale if the organization hasn't clearly distinguished the types of memory, lacks a retention policy, human feedback doesn't feed into a correction mechanism, or the agent stores too much context without classification.
Unifying RAG, Graph, and Memory in a Single Context Layer
These three components do not replace each other. They complement each other. RAG helps the agent retrieve relevant knowledge from documents and enterprise corpora. The knowledge graph helps the agent understand relationships between business entities. Memory helps the agent maintain continuity of context across sessions, workflows, and operational learning.
In a mature enterprise workflow, all three often work together. In procurement exceptions, RAG retrieves the relevant purchasing policy and contract clauses, the graph shows the relationship between the requester, category, supplier, contract, and approval path, and memory remembers that a similar case was previously rejected due to incomplete documents. In finance close, RAG retrieves accounting guidance and the close SOP, the graph maps the relationship between entities, accounts, journals, and controls, and memory stores the history of exceptions and previous controller decisions.
This is where the context layer truly becomes an execution layer, not just a search layer.
Practical Implications
The context layer is not a technology project that can be completed in a week. It is an architectural decision that determines whether an agent can be trusted to make operational decisions.
For the CIO, the question is whether the company already has a governable context layer, or is still relying on prompt engineering and ad hoc retrieval. For the COO, on priority workflows, what context does the agent truly need to make relevant and safe decisions. For the CHRO, if agents start storing user memory or institutional memory, are the policies on privacy, fairness, and correction already in place. For the transformation leader, are agentic use cases built on trustworthy enterprise context, or just on a demo retrieval that looks convincing.
If the answers to these questions are still unclear, the next priority is not to add new agents. The priority is to build a context layer that is accurate, relevant, and safe. Because that is where operational trust in agents is truly formed.