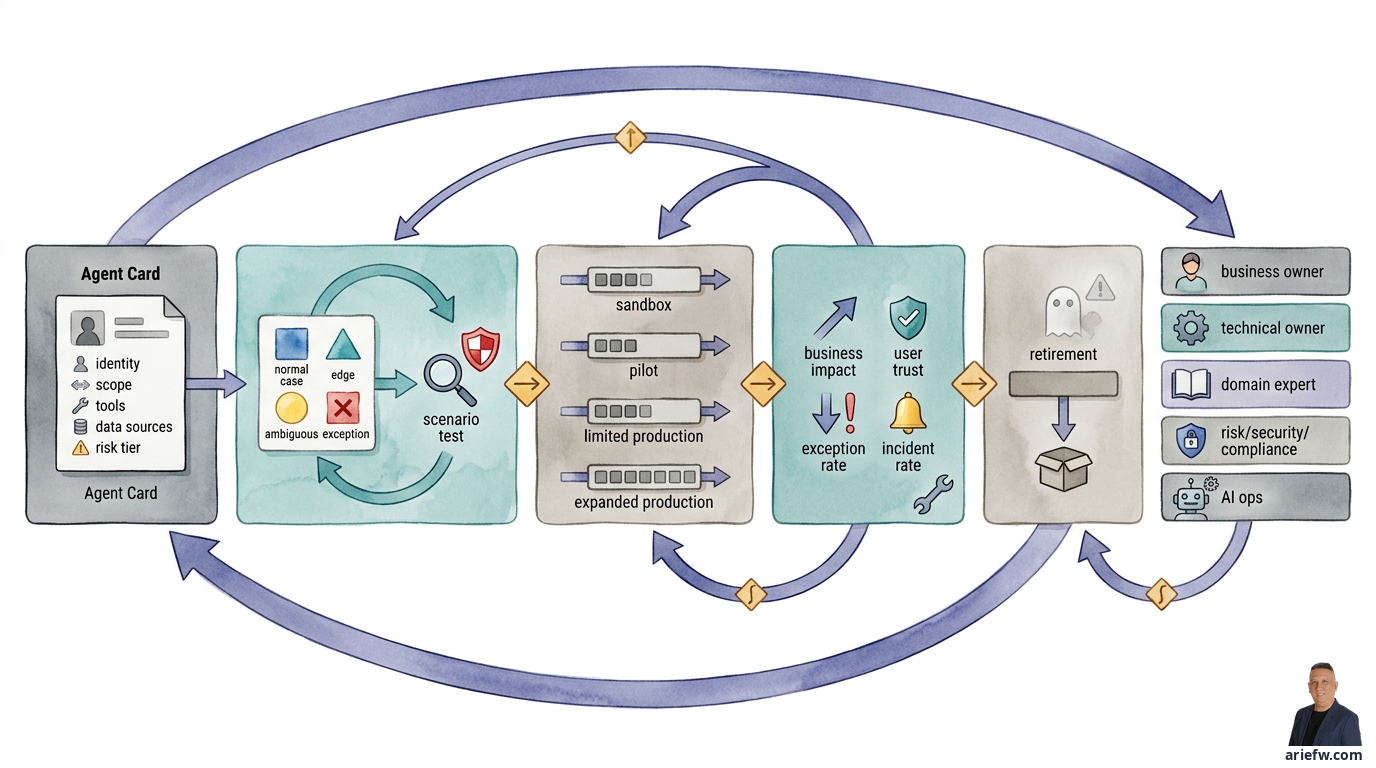
Agent Lifecycle Management
Imagine your finance team has just launched an agent to help with the monthly closing process. In the demo, everything runs smoothly. The agent pulls data from the ERP, reconciles it with spreadsheets, and prepares adjusting journal entries. Three weeks later, a staff member discovers the agent has started using outdated accounting rules because its knowledge source was never updated. No one knows when the change occurred. The agent keeps running, still appears active, but slowly begins producing output that no longer complies with policy.
This scenario is not fiction. Many companies experience the same pattern: great enthusiasm during the pilot, then attention wanes once the agent is actually in use. Yet an agent is not just a prompt that can be left unattended. It is a combination of system instructions, models, tools, APIs, memory, policy approvals, data sources, workflow orchestration, and the human roles surrounding it. Change one component—swap the base model, add a new tool, or expand the knowledge corpus—and the agent's behavior can shift dramatically, even if it looks the same from the outside.
The question is: how does a company ensure an agent is managed from birth to retirement, not just maintained for the demo?
Why Agents Cannot Be Treated Like Ordinary Applications
The traditional application lifecycle revolves around code, releases, and infrastructure. The AI model lifecycle revolves around data, training, and model deployment. Agents sit at the intersection of both, with an added layer of decision-making and action. They are behavioral systems, not single components.
Take a procurement agent as an example. It might receive an intake request, retrieve category policies, check vendors and contracts, call an ERP API, request approval if the value exceeds a certain threshold, and then create a purchase request. If the prompt changes, the agent could become more aggressive or more conservative. If a new tool is added, its scope of action expands. If the policy engine is updated, the approval path could change. All of this happens without major changes to the user interface.
In deterministic applications, small changes usually produce relatively predictable results. In agentic systems, this is not always the case. A customer operations agent that previously only gave refund recommendations is now given an execution tool for low-value cases. A finance close agent that previously used one accounting guidance source now pulls context from an additional repository. An IT operations agent that previously only opened tickets can now run automated diagnostic runbooks. Technically, these changes might seem small. From a governance perspective, the risk profile shifts dramatically.
For this reason, companies need a discipline called agent lifecycle management: a way to design, build, test, launch, monitor, improve, and, at the right time, retire an agent. Without a clear lifecycle, organizations will face the same patterns repeatedly: promising pilots that are difficult to audit, small changes triggering unexpected behavior, unclear agent ownership, evaluations done only once at the start, and agents that are no longer relevant remaining alive in production.
Lifecycle management is not extra bureaucracy. It is a mechanism to keep agents safe, effective, policy-compliant, and business-viable over time. Companies will only grant agents higher autonomy if they trust that those agents have clear specifications, are tested rigorously, are monitored after going live, are corrected when drift occurs, and can be shut down quickly if needed.
Start with Specifications, Not Prompts
A common mistake in building agents is starting with the question, "What agent can we build?" A healthier enterprise approach is to start with operational specifications.
Every agent should have an agent card: a concise but formal document that defines the agent's identity and operational boundaries. At a minimum, the agent card should include the business purpose, scope, inputs and outputs, permitted tools, data sources and context sources, business owner and technical owner, risk tier, and level of autonomy. The agent card forces the organization to stop seeing the agent as an "AI feature" and start seeing it as a digital operations unit.
A good specification should also define what success looks like for the agent. In AP exception handling, success might mean more accurate exception classification, faster routing, and reduced rework. In customer operations, success might mean faster resolution of simple cases without an increase in complaint reopening. In IT operations, success might mean more complete incident enrichment and more consistent triage. Success criteria should connect three layers: the quality of the agent's decisions, compliance with policy, and the impact on business process metrics.
A mature agent specification doesn't just explain what is expected; it also explains how the agent could fail. Common failure modes include: misunderstanding intent, pulling irrelevant or outdated context, selecting the wrong tool, violating policy thresholds, escalating too often, being overconfident in ambiguous cases, or failing to stop when instructions conflict. In procurement, an agent might mistakenly classify a non-standard purchase as a regular catalog item. In finance, an agent might prepare commentary that sounds reasonable but lacks sufficient supporting evidence. In HR services, an agent might answer a policy question using an old, unupdated document. These failure modes should be documented from the start because they will determine the design of tests, guardrails, and monitoring.
Equally important: domain experts need to be involved from the specification phase. An agent that touches enterprise workflows cannot be designed solely by the AI or engineering team. Domain experts are needed to capture formal business rules, common exceptions, tacit judgment that has historically been undocumented, and the points where humans actually add value. Without domain experts, agents often look smart in demos but fail when faced with the exception-heavy reality of production.
Test Behavior, Not Just Output
Testing an agent cannot be the same as testing a regular application, and it is also insufficient to only test the quality of the model's answers. What must be tested is the agent's behavior within the context of a real workflow.
Every agent should have a golden dataset: a collection of representative cases used to consistently test basic behavior. This dataset should include normal cases, edge cases, ambiguous cases, and common exception cases from operations. But a golden dataset alone is not enough. Companies also need scenario tests that simulate end-to-end flows: input received, context retrieval, tool calls, policy checks, approvals, and the final outcome. In customer operations, for example, test whether the agent correctly processes small refunds, stops at large refunds, and escalates when the customer history shows a pattern of abuse.
Because agents can take action, testing must verify that the agent only uses permitted tools, uses the correct parameters, does not attempt to bypass approvals, and adheres to delegated authority limits. This is especially important after changes to the prompt, tool registry, policy engine, or API integrations. An agent that passes language quality tests may not pass operational control tests.
For agents entering production, red teaming is not a luxury. It is a necessity. The goal is not to find cosmetic errors, but to simulate attacks and conditions that could break controls. Some scenarios to test include: prompt injection, data leakage, privilege escalation, and conflicting instructions. A procurement agent might receive a vendor attachment containing hidden instructions to alter the approval path. An IT operations agent might receive an event that triggers a runbook, but the supporting data has been manipulated. An HR agent might be asked questions in a way that attempts to extract other employees' personal information.
A principle often overlooked: an agent is not a system that can be tested once and considered stable. Every significant change to the model, prompt, tool, memory, policy, or context corpus should trigger retesting. If not, companies will experience "silent drift": the agent looks the same, but its behavior changes, and that change is only noticed after an incident or a decline in trust. Repeated testing adds discipline and release time, but without it, deployment speed only shifts risk into operations.
Roll Out Gradually, Not All at Once
An agent should not be launched across the entire organization at once. A healthier approach is a staged rollout with four phases.
First, sandbox: the agent is tested on controlled data and workflows. The focus is on validating specifications, technical testing, and identifying initial failure modes. Second, pilot: the agent is used by a limited group of users or on a subset of cases. The goal is to observe behavior in more realistic conditions, test handoffs to humans, and measure initial metrics. Third, limited production: the agent begins touching real operations, but with a narrow domain scope, low transaction thresholds, or restricted autonomy. Fourth, expanded production: only after sufficient evidence of quality, control, and value, the agent is expanded to larger volumes, units, or scenarios.
This approach is important because agentic AI touches the operating model. If the rollout is too fast, the organization has no time to adjust SOPs, approval queues, support models, and human roles.
Once live, companies need to monitor four groups of signals. Business impact: is cycle time improving, is the backlog decreasing, is the touchless rate rising, is service quality improving? User trust: are users accepting the agent's recommendations, or is the override rate high, are supervisors starting to ignore the agent's output? Exception rate: is the agent escalating too often, are many cases falling into manual paths? This could mean the specification is too narrow or the agent's quality is insufficient. Incident rate: are there policy breaches, tool misuse, data exposures, or incorrect actions requiring rollback or remediation?
This monitoring must be connected to a process of continuous improvement, not just a passive dashboard. After deployment, the real work begins. Agents need prompt or workflow tuning, policy updates, retrieval improvements, approval threshold adjustments, and sometimes a decrease or increase in autonomy levels. Every agent should have a clear review cadence: who reviews performance, how often, what metrics are used, and when changes can be released. Without an operating cadence like this, an agent will slowly degrade while still appearing "active."
Not Every Agent Is Worth Keeping
One sign of governance maturity is the ability to retire an agent that is no longer viable. Many companies are good at launching pilots but weak at retiring capabilities that no longer provide value, are too expensive to maintain, have been replaced by other solutions, or have a risk profile that is no longer acceptable.
Some clear signals: business value is stagnant or declining, operational and monitoring costs outweigh the benefits, the exception rate remains high despite tuning, policy or regulatory changes make the agent's design no longer suitable, the source systems or tools the agent uses have changed, or the agent has become redundant because similar capabilities are now embedded in the enterprise platform. An internal knowledge agent whose corpus is no longer curated and is eroding trust. A local procurement agent built quickly but now conflicts with standard capabilities from the enterprise platform. An IT remediation agent that has become too risky after a production architecture change.
A retired agent must be deactivated from the runtime, have its access and credentials revoked, be removed or archived from the registry, have its monitoring and billing stopped, and have the reason for its retirement documented. If not, companies will accumulate zombie agents: still having access, still recorded in the system, but with no clear owner responsible. This is not just waste. It is a security and governance risk.
The Operating Model Required
For lifecycle management to work, companies typically need to clearly divide roles. The business owner is responsible for the business outcome and relevance. The technical owner or product owner is responsible for the agent's design, release, and operation. The domain expert ensures alignment with rules and exception handling. Risk, security, and compliance assess controls, policies, and material changes. The AI ops or platform team manages observability, deployment, evaluation, and incident response.
This is also why agent lifecycle management is not well-suited to being managed entirely as an experimental project. It requires a cross-functional operating model.
What Should Be Done Now
Lifecycle management is the differentiator between organizations that demo agents and organizations that operate digital labor responsibly. Without this discipline, scale only amplifies risk. With this discipline, agents can evolve from experiments into safe, measurable, and trustworthy enterprise capabilities.
Several decisions need to be made now: determine whether your company will have a formal agent card for every production agent. Decide which changes are considered material and must trigger retesting, such as changes to the model, prompt, tool, policy, memory, or context corpus. Establish a staged deployment path—whether all agents must pass through sandbox, pilot, limited production, and then expanded production. Define the post-deployment operating cadence: who reviews agent performance, how often, and based on what metrics. Create a formal retirement process: when an agent should be retired, who approves it, and how access and the registry are cleaned up.
If agents in your company are still built from prompts and tools without formal specifications, if there is no clear business owner or technical owner, if testing is only done on "clean" demo cases, if prompt or model changes are made directly in production, if there is no staged rollout, if post-live metrics are limited to latency and uptime, if unused agents still have system access, or if the organization has no formal way to retire a failing agent—then this topic is not yet ready for scale and requires additional governance.
A reflective question for leaders: are the agents in your company treated as operational assets with a formal lifecycle, or are they still treated as application experiments? Do you know which agents are truly improving process economics, and which are only adding complexity? Have the human roles in review, exception handling, and oversight been designed as part of the lifecycle, not as a reaction after an incident? If your company launches 20 agents in the next 12 months, do you have the mechanisms to test, monitor, improve, and retire all of them with discipline?