Agentic AI FinOps: Managing Cost, Latency, and Capacity
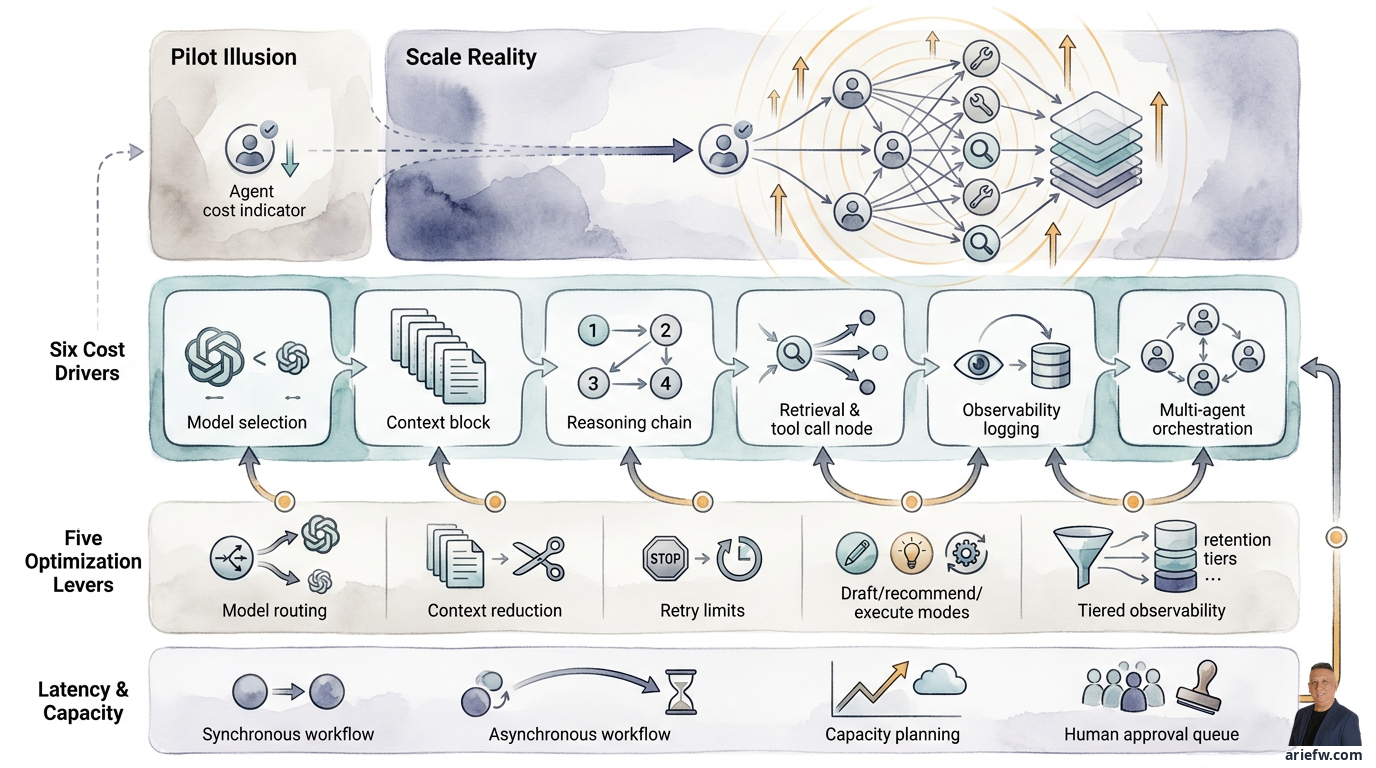
A shared services manager watches a pilot agent for AP exception handling run smoothly. The cost per transaction on the dashboard looks small, latency is acceptable, and the team is happy because their workload has decreased. Six months later, when volume increases tenfold, the cloud bill balloons, users start complaining about slowness, and the IT team is scrambling to keep up with capacity. What happened?
A seemingly cheap pilot often hides the true costs. An agentic workflow isn't a single, simple model call. It can involve multiple reasoning steps, retrieval from a knowledge layer, tool calls to enterprise systems, retries, evaluations, logging, and sometimes the coordination of several agents at once. When this pattern is brought to enterprise scale, its economics change completely.
This is where companies need to start thinking about Agentic AI FinOps. It's not just about saving tokens, but about managing three things simultaneously: the real cost of producing a successful outcome, how quickly the agent delivers a still-usable result, and whether the platform, models, APIs, and operations team can handle the volume and load spikes.
Why Pilots Often Deceive the Economics
The most common mistake is calculating agent costs solely based on model price per token or per request. In an enterprise workflow, one outcome can consist of many components. Take AP exception handling: the agent receives a case, retrieves context from the ERP and knowledge base, calls a model for classification, calls a tool to check invoice and goods receipt status, might retry if data is incomplete, and then prepares a recommendation or escalation. On the surface, each step seems cheap. But the real cost comes from accumulation.
The same happens in customer operations. A refund agent might read customer history, check entitlements, retrieve policy, formulate a recommendation, request approval for certain cases, and then log the result in the CRM. If daily case volume is high, the small cost per step becomes material. This is especially true if the agent frequently loops, retries, or calls a model that is too large for a task that is actually simple.
Pilots typically run at low volume, with relatively clean data, pre-selected scenarios, and high human oversight. Under these conditions, costs appear manageable. But upon entering production, case variety increases, exceptions become more frequent, users try more interaction patterns, and source systems don't always respond perfectly. Consequently, the number of steps per transaction rises. Costs that once seemed small become significant.
Therefore, a more accurate metric isn't cost per prompt or cost per token, but cost per successful outcome. What needs to be calculated isn't just the inference cost, but the cost to produce a genuinely valuable outcome. For example, the cost per exception successfully classified and routed correctly, the cost per low-risk refund completed without rework, or the cost per incident successfully triaged correctly. If an agent is cheap but has a high correction rate, excessive escalation rate, or many cases need redoing, then its economics are actually poor.
Six Often-Overlooked Cost Drivers
To manage economics effectively, companies need to understand where the costs truly come from. In agentic systems, there are six main drivers.
First, model selection. More powerful models are typically more expensive and often slower. The problem is that many teams use the best model for every step, including lightweight tasks like intent classification, field extraction, simple routing, or format validation. For procurement intake, for example, initial spend category classification might be adequately handled by a smaller model. A more powerful model is only needed if the case is ambiguous, involves non-standard contracts, or touches higher-risk decisions.
Second, context length. Context length is a frequently invisible cost killer. The more documents, transcripts, history, and metadata stuffed into the prompt, the more expensive and slower the inference. This problem often arises when an organization hasn't been disciplined in building precise retrieval. As a result, the agent is given too much context just to be safe. Costs rise, latency worsens, and quality isn't necessarily better because the model drowns in noise.
Third, the number of reasoning steps. Multi-step agentic workflows are indeed useful for complex tasks. But each additional reasoning step means additional cost. If not controlled, an agent can become overly diligent in thinking about problems that are actually simple. In IT operations, for basic incident enrichment, an agent doesn't need to perform lengthy reasoning. If every incident is treated like a complex investigation, costs and latency will spike without commensurate added value.
Fourth, retrieval calls and tool calls. Every retrieval to a vector store, knowledge graph, or data product has computational cost and latency. Every tool call to an ERP, CRM, HRIS, or ITSM also has a cost, both direct and indirect: API consumption, middleware load, event processing, and sometimes licensing or platform fees. In an enterprise, tool calls are often more expensive operationally than they appear at the AI application level.
Fifth, the frequency of evaluation and observability. Logging, tracing, audit storage, and post-production evaluation also have costs: storage for transcripts and traces, telemetry processing, dashboards and alerting, sample reviews, periodic regression testing. The more mature the governance, the greater the cost of controls. This isn't a reason to reduce observability, but a reason to include it in the cost model from the start.
Sixth, multi-agent orchestration. Multi-agent architectures can improve modularity, but they can also worsen economics. If one request must pass through an orchestrator, then two or three task agents, the cost per outcome rises quickly. This pattern is worthwhile if it genuinely provides better quality or control. But for simple use cases, multi-agent is often an uneconomical architectural luxury.
Five Optimization Levers Without Ruining Outcomes
Healthy FinOps doesn't mean always choosing the cheapest option. The goal is to find the most reasonable combination of cost, quality, and risk for a specific use case.
Model routing is the most important lever. Use small models for simple tasks and reserve more powerful models only for complex reasoning, ambiguous cases, high-risk decisions, or synthesis across many sources. In finance close, for example, a lightweight model for extracting variance drivers from structured data, and a more powerful model for drafting commentary that combines numbers, policy, and business narrative. The trade-off is clear: routing adds architectural and evaluation complexity. But without routing, costs will quickly spiral out of control.
Reduce context bloat. Much of agentic AI's cost is actually the cost of excessive context. The three most practical techniques are: more precise retrieval, summarization before main reasoning, and caching frequently used context. In customer operations, an agent doesn't always need to bring the entire customer history into the prompt. A relevant summary for the active case, plus on-demand access for further detail, is sufficient. However, summarization and caching also carry risks. Summaries can lose important nuances, and caches can become stale. These techniques are better suited for domains with relatively stable information patterns and low to medium risk.
Limit retries and loops. An agent that keeps trying until it succeeds is a recipe for exploding costs. Every workflow needs explicit stopping criteria, retry limits, tool call limits, and conditions for escalation to a human. In shared services, if invoice data remains incomplete after one or two validation attempts, the agent should stop and open a manual case, not keep calling the same models and tools.
Differentiate between draft, recommend, and execute modes. Not every use case needs deep reasoning at every step. For many processes, it's sufficient for the agent to prepare a draft, give a recommendation, or perform pre-processing before a human makes a decision. This is often more economical than forcing the agent to complete the entire workflow autonomously. Especially in the early scale-up phase, draft mode often provides healthier economics while maintaining trust.
Optimize observability, don't turn it off. Full logging for every interaction can be expensive. But turning off observability to save costs is a bad decision. A healthier approach: full logging for high-risk workflows, sampling or summaries for low-risk workflows, differentiated retention policies based on risk tier, and separation between mandatory audit logs and temporary debug logs. This way, the company maintains accountability without letting telemetry costs grow unchecked.
Latency: Accuracy Alone Isn't Enough
Many teams focus too much on answer quality and forget that an agent that is too slow won't be used. In an enterprise, latency affects user adoption, process SLAs, team productivity, and the perception of trust in the agent. A highly accurate but slow customer service agent will make human agents revert to their old ways. A procurement agent that takes too long to give an intake recommendation will be seen as hindering the process.
The most important design decision is distinguishing between synchronous and asynchronous workflows. Synchronous mode is suitable for interactions requiring a quick response in front of the user, such as internal Q&A, initial classification, short drafts, or simple recommendations. For this mode, the workflow must be lightweight: limited context, minimum tool calls, and a clear fallback if the process takes too long.
Asynchronous mode is suitable for heavier work, such as complex exception analysis, report generation, incident investigation, multi-source reconciliation, or batch processing in shared services. For this mode, users don't need to wait on the screen. What's more important is clear status, notification upon completion, and results that can be reviewed.
Many latency problems arise because organizations force workflows that should be asynchronous into synchronous mode for the sake of a chat-like experience. If a workflow takes time, the UX must be honest and helpful. The system needs to provide progress status, an indication of the current step, intermediate results if possible, and a fallback if the process fails or takes too long. In finance close, an agent gathering evidence and drafting commentary should provide statuses like "retrieving variance data", "checking relevant policy", then "preparing draft". This is far better than a blank screen that makes users think the system is frozen.
Capacity: Don't Wait Until a Bottleneck Occurs
Beyond cost and latency, agentic AI FinOps must also consider capacity. The question isn't just how much a transaction costs, but whether the model gateway can handle load spikes, whether the core system APIs can handle additional tool calls, whether the vector store and retrieval layer remain responsive, and whether the human approval queue becomes a bottleneck.
During month-end finance close or peak season in customer operations, volume can spike at specific times. If capacity planning isn't done, companies will see latency rise sharply, timeouts increase, retries multiply, costs spike, and user experience deteriorate. Capacity planning for agentic systems must cover the entire chain: model inference, retrieval, integration layer, workflow engine, and human approval capacity.
Who is Responsible for This Economics?
Agentic AI FinOps won't work if it's seen merely as a technical dashboard. Every production agent should have a business owner, a technical owner, a budget or spending envelope, cost alerts, usage analytics, and clear outcome targets. Without a clear owner, costs will become a "shared platform cost" that is never truly accounted for.
Agent portfolio reviews shouldn't stop at usage volume. What needs to be compared is total cost, cost per successful outcome, latency, correction rate, escalation rate, and proven business value. A popular agent isn't necessarily economical. Conversely, an agent with moderate volume can be highly valuable if its outcomes are strong and its cost per result is healthy.
There are several signals that an agent isn't ready for expansion: cost per successful outcome is too high, latency drives users back to manual processes, retries and loops are too frequent, observability shows excessive tool calls, the approval queue becomes a bottleneck, or business value hasn't been proven sufficient to cover operational and oversight costs. In such conditions, the right answer isn't always "optimize the model." Sometimes the answer is to simplify the workflow, reduce the level of autonomy, change the UX to asynchronous, or stop the use case altogether.
Ultimately, FinOps for agentic AI isn't about squeezing costs as low as possible. The goal is to ensure the company can scale agents without breaking the economics, user experience, and operational control. In the enterprise, that's the prerequisite for agentic transformation to truly be sustainable, not just look impressive in the pilot phase.