Reference Architecture for Enterprise Agent Platform
Imagine your finance team has successfully built an agent to assist with the month-end close process. The results are promising: reconciliation time is reduced, exceptions are detected faster, and the team can focus on analysis rather than data entry. Seeing this success, the procurement team starts building an agent for intake-to-PO. The customer service team wants an agent for complaint resolution. The IT operations team begins designing an agent for incident triage.
Each team starts with the same enthusiasm. Each builds in its own way. The finance team creates simple logging in a spreadsheet. The procurement team chooses a different gateway model. The customer service team stores context in local files. The IT operations team builds its own approval mechanism.
Locally, all these decisions make sense. At the enterprise level, the consequences begin to surface: tool integrations are duplicated, access controls are inconsistent, logs and audits cannot be compared, and cross-agent evaluation becomes difficult. What once felt like progress slowly turns into fragmentation.
This is the point where companies start asking: are we building several agent applications, or are we building an enterprise platform to run agents securely and at scale?
Why the "Each Team Builds Its Own" Pattern Becomes Problematic
Many organizations start with the right approach: pick one high-value use case, build a quick pilot, and prove the benefits. Problems arise when that initial success is replicated without platform discipline. Each team builds an agent with its own stack, logging, and controls. The result is agent sprawl: many agents running, but no shared foundation to manage them all consistently.
To understand why this becomes a problem, we need to distinguish between two things that are often conflated.
An agent application is a solution for a specific use case. For example, an agent for AP exception handling, an agent for procurement intake-to-PO, or an agent for customer complaint resolution. Each contains workflows, prompts, tools, context, and a UI specific to that domain. This is the layer directly visible to business users.
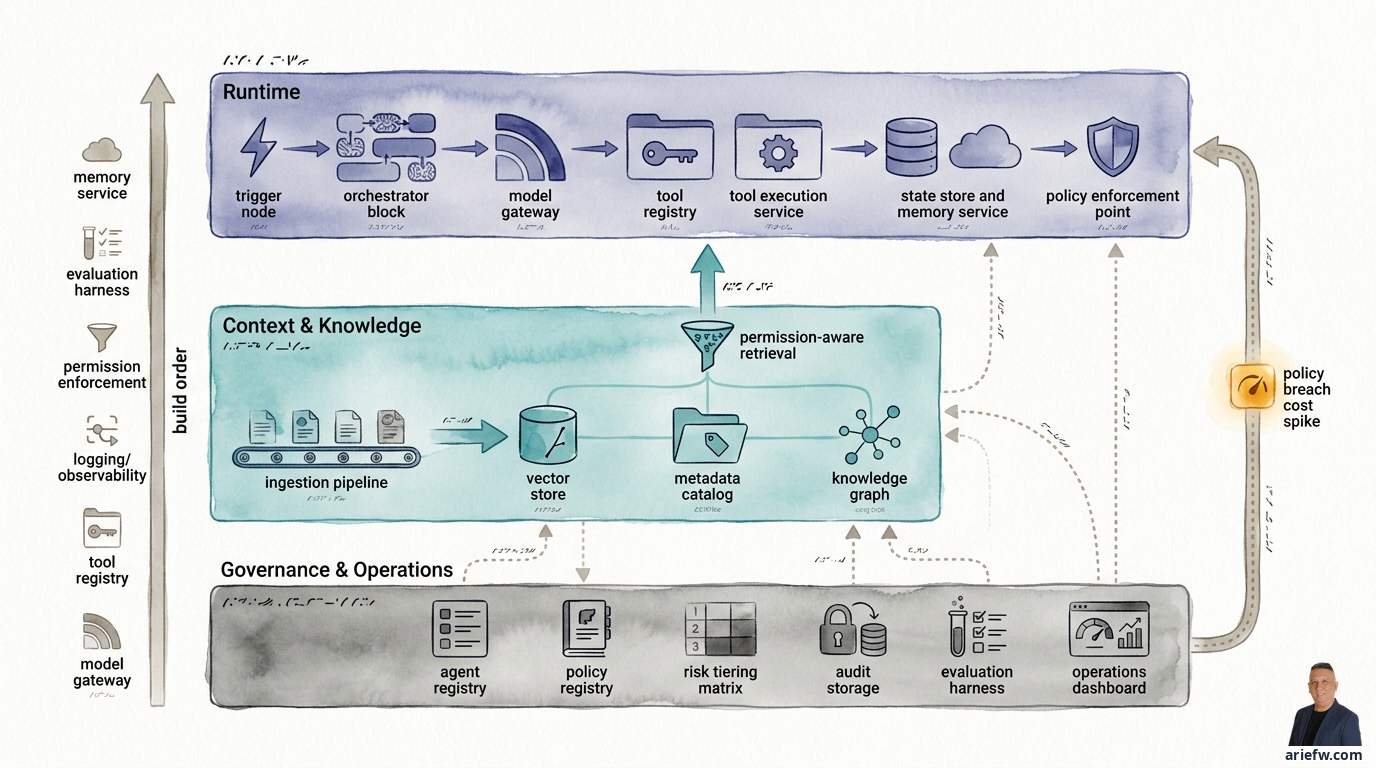
An enterprise agent platform is a shared layer used by many agent applications. This platform does not directly solve a specific business process. It provides standard capabilities such as identity and access control, model gateway, tool registry, context retrieval, observability, evaluation harness, deployment and rollback, policy enforcement, and registry and lifecycle governance.
Without this distinction, companies often go astray. Some think they are building a platform when they are actually just creating their first agent with many custom components that are hard to reuse. Others spend too long building a generic platform without a real use case, turning it into an infrastructure project that never gets used.
A shared platform becomes important because of three problems that emerge at scale. First, reusability: capabilities like model routing, permission-aware retrieval, audit logging, and approval orchestration do not need to be rebuilt for every agent. Second, control consistency: if all agents pass through the same policy enforcement, observability, and identity patterns, governance becomes much stronger. Third, operating leverage: the platform team can centrally manage cost, latency, incidents, and lifecycle, while domain teams focus on business logic.
Of course, not every organization needs to build a full platform immediately. If a company is still running one or two pilots that haven't touched core systems, a lightweight approach may suffice. However, once agents start calling enterprise APIs, accessing sensitive data, executing actions, or being used across functions, the shared platform pattern becomes a necessity, not a luxury.
Runtime: Where Agents Actually Execute
The first layer in the reference architecture is where agents receive triggers, reason, retrieve context, call tools, and generate actions. This is where execution logic resides.
The orchestrator is the component that manages the agent's workflow. It receives triggers from users, events, or workflows, breaks tasks into steps, determines when to call the model, when to use tools, when to request human approval, and when to stop or escalate. For simple use cases, the orchestrator can be lightweight. But for enterprise workflows like finance close or supply chain exception management, the orchestrator becomes critical because the processes are multi-step, involve handoffs, and often span multiple systems. In finance close, the orchestrator can sequence steps for reconciliation data retrieval, exception classification, drafting commentary, and routing to a controller. In IT operations, the orchestrator can combine event monitoring, diagnostics, runbooks, and engineer approval.
The model gateway is a component that is often underestimated, yet it is very important. Its function is not merely to connect to a model, but to select the appropriate model for a given task, manage fallback if the primary model fails, apply standard logging, control cost and latency, and maintain consistency in model usage policies. Without a model gateway, each agent tends to call models directly with different patterns. As a result, the company loses control over cost, quality, and auditability. The model gateway is also crucial for a multi-model strategy. Simple classification tasks might suffice with a lighter model, while complex reasoning or cross-document synthesis may require a more powerful model.
Tools in an enterprise agent platform should not be treated as a free-to-use API list. Two distinct layers are needed. The tool registry is a catalog of available tools, containing metadata, owner, permissions, risk tier, and usage contracts. The tool execution service is the runtime layer that actually executes the tool call after validation. Every agent action must pass through parameter validation, permission checks, policy evaluation, audit logging, and, if necessary, an approval workflow. This prevents agents from acting directly on ERP, CRM, HRIS, or ITSM systems without adequate control. A procurement agent may be allowed to call a tool to create a draft purchase request, but the tool execution service can deny execution if the vendor is not yet approved. A customer operations agent may prepare a refund, but execution is held if the value exceeds a policy threshold.
Enterprise agents rarely work in a single, isolated interaction. They need to store workflow status, results from previous steps, intermediate decisions, and sometimes relevant memory for subsequent interactions. Therefore, the architecture needs to distinguish between a state store for deterministic operational workflow status and a memory service for additional context that the agent can use across sessions or steps. Many implementations lump everything together as memory, even though their governance requirements differ. Workflow state usually needs to be stricter, more structured, and easier to audit. Memory can be more flexible, but must still adhere to permission and retention policies.
The policy enforcement point is the location in the runtime where policy decisions are applied. It must be close to tool calls, data access, and action execution. Without an explicit enforcement point, policies remain documents or scattered logic across many components. For an enterprise, this is too fragile.
Context and Knowledge: Agent Quality Is Determined Here
Many agent failures are not due to a poor model, but because the context provided is wrong, incomplete, outdated, or violates permission boundaries. The context layer is not an add-on; it is a primary dependency for agent quality.
The platform needs an ingestion pipeline to bring documents, knowledge articles, policies, SOPs, transcripts, and reference data into the context layer in a managed way. This pipeline handles extraction, chunking or segmentation, metadata enrichment, sensitivity classification, versioning, and update synchronization. Without disciplined ingestion, retrieval will pull irrelevant or stale documents.
Three storage components have distinct roles. The vector store facilitates semantic search over unstructured content. The metadata catalog provides structure: document source, owner, effective date, classification, domain, and access rights. The knowledge graph is useful when the company needs to understand relationships between entities: vendors, contracts, products, customers, accounts, incidents, locations, or policies. Not every use case needs a knowledge graph from the start. For a simple knowledge assistant, vector retrieval plus metadata may be sufficient. But for enterprise use cases involving complex relationships—such as supply chain disruption, customer entitlement, or cross-entity finance exceptions—a graph can improve reasoning quality and context navigation.
Permission-aware retrieval is one of the most important capabilities. An agent should not retrieve context simply because a document is semantically similar. Retrieval must be permission-aware: it must consider the user or principal making the request, which agent is asking, what domain is being processed, and what data is accessible in that context. An HR agent should not pull compensation documents unrelated to the case. A customer service agent should not retrieve another customer's history. A finance agent should not mix guidance across entities without appropriate access rights.
A good enterprise agent almost always needs to combine two types of context: structured data from ERP, CRM, HRIS, data warehouses, or event streams, and unstructured data from documents, emails, SOPs, contracts, knowledge bases, or transcripts. The platform should ideally have a context service that can securely unify both. In AP exception handling, the agent needs invoices, POs, and goods receipts from structured systems, plus policies and case history from documents. In customer operations, the agent needs entitlement and order history from CRM/OMS, plus knowledge articles and interaction transcripts. If the context service is weak, the agent will sound intelligent but act on a fragile foundation.
Governance and Operations: Making Agents Production-Ready
An enterprise platform is not complete with just runtime and context. It also requires a governance and operations layer that makes agents auditable, testable, and manageable throughout their lifecycle.
The agent registry is the official catalog of all agents running in the enterprise. At a minimum, it should contain the agent's name and purpose, business and technical owners, risk tier, tools and data sources, autonomy level, lifecycle status, and key dependencies. The policy registry stores rules used across agents: transaction thresholds, approval rules, tool restrictions, risk classifications, and domain-specific policies. Without a registry, the company lacks a proper inventory for governance.
Not all agents need the same level of control. The platform must support risk tiering. An internal knowledge agent in assist mode is certainly different from an agent that can execute actions in an ERP. An agent that drafts commentary is different from an agent that can trigger refunds or production remediation. This risk tiering must be connected to approval workflows, observability depth, testing rigor, and release controls.
All important traces—tool calls, policy decisions, approvals, context retrievals, outcomes—must go into a secure and traceable audit storage. In addition, the platform needs an evaluation harness: an environment and tools for testing agents before and after release. This includes golden datasets, scenario tests, policy compliance tests, regression tests when models, prompts, or tools change, and post-production sampling evaluations. Without an evaluation harness, the company only knows the agent is running, but not whether its quality is improving or degrading.
From an operations perspective, the platform needs to provide a runtime health dashboard, a quality and outcome dashboard, alerts for technical incidents, policy breaches, and cost spikes, a mechanism for quick rollback or disablement, and cost management for model, retrieval, and tool usage. Agentic systems can fail not only technically. They can also become too expensive, too slow, escalate too often, or silently degrade decision quality.
A Sensible Build Order
A classic mistake in platform strategy is trying to build the complete architecture from day one. This almost always ends up slow, expensive, and far from business needs. A healthier approach is to build a minimum viable platform born from the first production-grade use case.
A practical order that usually makes the most sense starts with the model gateway. Start here so that all early agents have a standard path for model access, logging, fallback, and cost control. Next, the tool registry and tool execution. Once agents start touching enterprise systems, this capability becomes mandatory. Without it, integrations will be wild and hard to audit. After that, basic logging, tracing, and observability. Before scaling, the company must be able to see what agents are doing and what their cost and latency are. Permission enforcement and policy checks follow when agents start reading sensitive data or executing actions. An evaluation harness is needed once changes to models, prompts, or tools become frequent. A memory service and a more mature agent registry can be built later, unless the use case requires them from the start.
The guiding principle: capabilities must arise from real use cases. If a company builds a knowledge graph without a use case that truly requires complex relationships, it risks becoming an expensive, rarely-used asset. If it builds a sophisticated memory service when agents are still task-based and stateless, that is also premature. A healthy platform grows from real needs, but with a consistent architectural pattern.
Imagine a company starting with two use cases: AP exception handling in shared services and incident triage in IT operations. From these two use cases, the company might find that the most urgent shared needs are a model gateway, tool registry, observability, permission-aware retrieval, and an approval workflow. A full knowledge graph or cross-agent memory might not be urgent yet. In this way, the platform grows based on real economics and risk, not on a feature list.
A good reference architecture is not the most complete one on paper, but one that allows the company to confidently answer a simple question: if we add ten new agents tomorrow in finance, procurement, customer operations, and IT, do we have a shared foundation to run them securely, at scale, and without creating agent sprawl?
If the answer is not yet, then the next priority is not to add more agents, but to strengthen the platform.