IT Delivery Model with AI Software Agents
Many technology teams begin their AI journey from the most comfortable starting point: the coding assistant. Developers use AI to write boilerplate code, create unit tests, or summarize documentation. The results feel immediate—individual tasks become faster. But if we stop there, we are only scratching the surface.
More fundamental questions start to emerge when teams realize that the bottleneck in software delivery isn't typing speed. Requirements remain ambiguous. Reviews pile up. Testing is delayed. Incidents take too long to understand. And handoffs between roles continue to be a source of delay untouched by any coding assistant.
This is where companies begin to move beyond simply giving developers tools, toward redesigning how technology teams work as a whole. It's no longer about how fast one person can write code, but how AI can take part in end-to-end software delivery and IT operations workflows.
What Changes When AI Starts Working in the Workflow
Until now, copilots have operated in a simple pattern: a developer asks for help, the AI offers suggestions, and the human selects and executes. This model speeds up individual tasks, but it doesn't change the structure of delivery. Systemic problems—like inconsistent test coverage, security findings discovered too late, or unclear deployment readiness—remain.
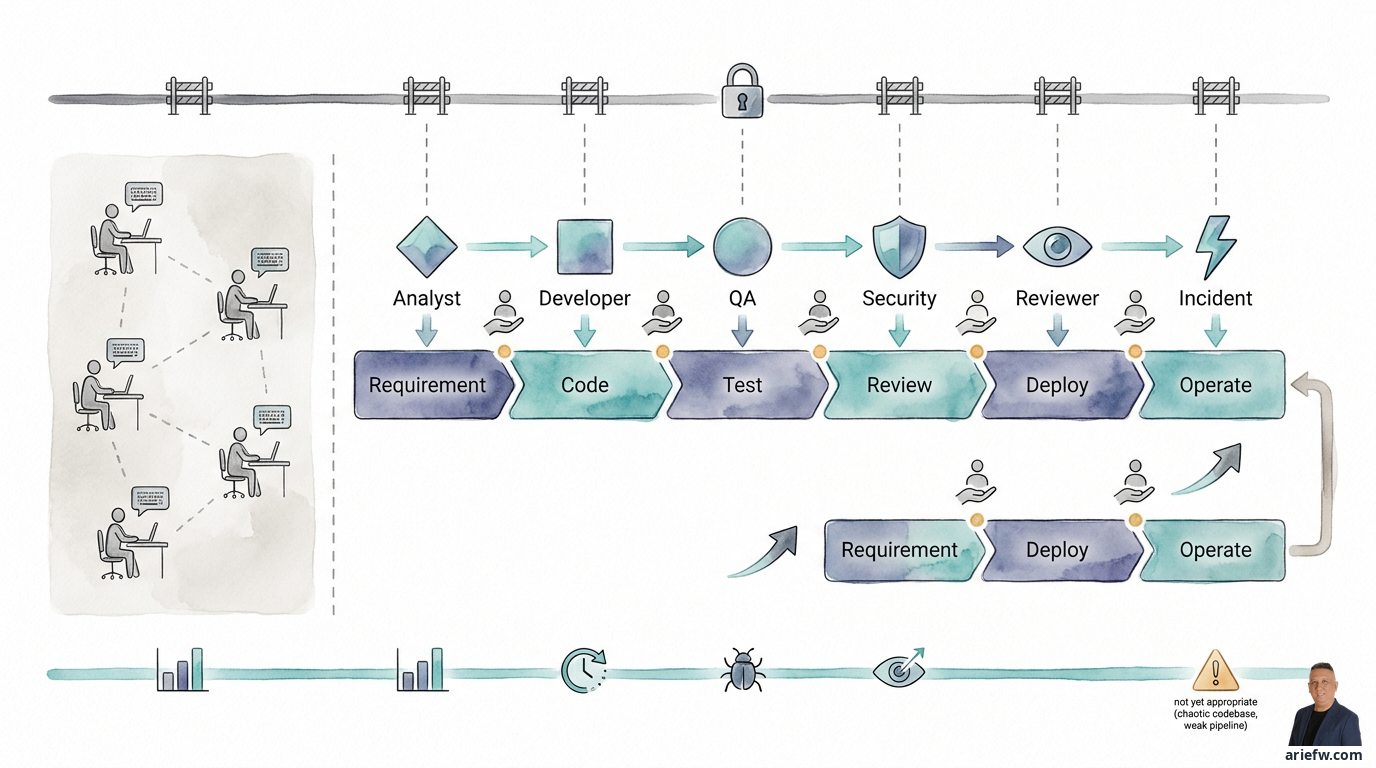
Software agents work differently. They don't just respond to requests one at a time. They can take part in longer sequences of work: breaking down requirements into user stories, creating initial implementations, generating tests, performing initial reviews, checking dependencies, and helping triage production incidents. In other words, copilots boost task productivity, while software agents have the potential to change the delivery flow itself.
This distinction matters because if it's not understood, two common mistakes emerge. First, organizations see an increase in coding speed and assume the entire delivery cycle has improved. But if reviews, testing, and releases remain slow, system throughput doesn't change much. Second, some organizations grant agents too much autonomy too quickly—giving them automatic merge rights or deployment capabilities without mature guardrails. This is dangerous, especially in environments with core systems, high technical debt, and audit obligations.
Software agents are most useful for work that is repetitive but still requires technical context, has traceable artifacts, can be tested automatically, and has clear risk boundaries. Examples include breaking down requirements for small enhancements, creating regression tests, performing initial pull request reviews, or triaging incidents based on runbooks. Conversely, agents are less suitable when forced to take over major architectural decisions, redesign core systems full of trade-offs, or handle high-risk production changes without human oversight.
Not One Agent for Everything
The healthiest way to think about software agents in the delivery cycle is not as a single entity that does everything, but as a collection of agents with limited roles. This pattern is better suited for the enterprise because responsibilities are clearer, evaluation is easier, control is more precise, and the failure of one agent doesn't immediately break the entire flow.
An Analyst agent can help translate requirements. Many delivery problems start with tickets that state general goals but aren't clear enough to implement. This agent can transform business requirements into user stories, draft acceptance criteria, identify initial dependencies, and flag areas that are still ambiguous. However, it's important to remember: the product manager, business analyst, or lead engineer must still validate whether the breakdown is correct from both a business and technical perspective.
A Developer agent can create an initial implementation once requirements are clear enough. It can write skeleton code, draft initial functions, update configurations, or generate draft migration scripts for limited changes. Its main value isn't replacing the engineer, but reducing the time to start from zero. The human engineer then reviews whether the design fits architectural patterns, whether error handling is adequate, and whether the change is safe for other systems.
A QA agent can help solve a classic problem: code is finished faster than tests. This agent can create unit tests, draft integration tests, generate synthetic test data, and translate acceptance criteria into test scenarios. This is extremely useful because testing is often a less glamorous but critical bottleneck for delivery quality.
A Security agent can be brought in early to check for risky dependencies, flag vulnerable coding patterns, check for secret exposure, and link changes to secure coding policies. When a developer agent adds a new library, the security agent can immediately flag that the library has issues that need review.
A Reviewer agent can perform an initial review of a pull request: whether the changes match the requirements, whether tests are missing, whether the structure is consistent, and whether documentation needs updating. This is not a replacement for human code review, but it can reduce the review burden by filtering out basic issues before a senior engineer gets involved.
In a healthy multi-agent pattern, humans retain three primary responsibilities. Decisions about system boundaries, performance trade-offs, and cross-domain integration must remain led by human engineers. For changes that will enter the main branch or production path, humans remain the final accountable party. And no agent should be the owner of production risk—accountability stays with the engineering manager, tech lead, or designated change owner.
Imagine a team building an enhancement for a customer service module in an internal CRM. The Analyst agent breaks down the requirements into user stories. The Developer agent drafts the implementation. The QA agent generates unit tests and regression scenarios. The Security agent checks new dependencies and customer data access patterns. The Reviewer agent provides initial comments on the pull request. A human engineer reviews the design, fixes edge cases, and decides whether the change is ready to merge. The CI/CD pipeline runs automated checks before the change can proceed. This pattern is far more realistic than the narrative of "AI writing the entire application."
IT Operations: From Alert to Faster Action
If software agents are only used in the development phase, companies are only capturing part of the value. Another highly relevant area is IT operations. Many operations teams still spend significant time reading alerts, searching for runbooks, opening logs from multiple tools, gathering configuration context, and preparing escalations. This work is important, but it's often repetitive and time-consuming, especially under pressure.
An Incident agent can read alerts from monitoring tools, correlate them with the service map, find relevant runbooks, check logs and recent changes, and then prepare a hypothesis for the cause along with remediation proposals. For example, after a payment application deployment causes a spike in error rates, the incident agent can see that a new deployment happened 20 minutes ago, pull the main error logs, match them with the rollback runbook, and prepare a recommendation. Its main value is accelerating situational understanding, not directly executing high-risk actions.
A Service desk agent can handle standard requests like access resets, answering technical FAQs, helping with tool onboarding, or opening tickets with the correct classification. This is highly relevant for shared IT services that handle high volumes. However, the boundaries must be clear: if a request touches high privileges, sensitive data, or important configuration changes, the agent must stop at verification and escalation.
A Change management agent can check readiness before a release. Many production problems aren't because the code is completely wrong, but because the change wasn't sufficiently prepared. This agent can check dependencies between services, ensure tests and scans are complete, assess whether there are any related open incidents, check the release window schedule, and prepare a risk summary for approvers. This makes the change process more evidence-based, rather than just a manual checklist.
Non-Negotiable Controls
The closer an agent gets to the codebase, pipeline, and production, the more critical controls become. In IT functions, guardrails are not an afterthought. They are a design requirement.
Even if an agent produces good code, it should not automatically merge to the main branch, change production configuration, or execute a deployment unless there is a very clear policy and approval matching the risk tier. For low-risk changes in non-production environments, autonomy can be looser. But for the production path, companies must be conservative.
Every change made or assisted by an agent needs to pass automated tests, static analysis, security scans, traceability back to a requirement or ticket, and human review according to the risk level. This is important not just for quality, but also for auditability. If an incident occurs, the organization must be able to answer: which requirement did this change originate from, which agent was involved, what controls were executed, and who approved the final step.
The success of engineering agents should not be measured solely by how much code is generated. More relevant metrics are lead time, defect leakage, incident MTTR, developer satisfaction, and review burden. The trade-offs here must be read honestly. If lead time drops but defect leakage rises, the model isn't healthy. If coding is faster but the review burden spikes, the company has simply moved the bottleneck.
When This Pattern Isn't Right Yet
Not every organization is ready to adopt this model. Several conditions suggest scaling up should be delayed: a very messy codebase with no test baseline, undisciplined CI/CD pipelines, weak requirements management, overly loose production access, minimal observability, or an engineering culture not yet ready for evidence-based review. In such conditions, agents tend to accelerate output without strengthening the control system. The result is delivery that looks fast but becomes increasingly fragile.
Organizations that are most ready typically already have mature engineering pipelines, clear coding and testing standards, connected ITSM and observability, and clear ownership between engineering, platform, security, and operations.
Platform engineering will become a key function in this model. Not just because they build the developer platform, but because they must provide a secure tool registry, controlled access to CI/CD and observability, policy enforcement, audit trails, and environments that separate draft, test, and production actions. Without platform discipline, software agents will quickly turn into a collection of wild automations that are difficult to audit.
Questions to Take Home
The decision that needs to be made now isn't about choosing the best AI tool. The question is more fundamental: does your company's IT function still see AI primarily as a coding aid for individuals, or has it started to redesign software delivery, IT operations, and platform engineering as a measurable, controlled, and scalable human-agent work system?
If the answer is still the former, start by distinguishing the agenda of copilots and software agents. Choose bounded initial workflows—like requirement breakdown, test generation, or incident triage—rather than jumping straight to automatic merge and deploy. Set autonomy limits per agent: which actions are only draft, recommend, execute with approval, and which are not allowed at all. Build controls into the pipeline, not into presentations. And define outcome metrics, not vanity metrics.
If the answer is already the latter, then the next challenge is ensuring that every agent has clear boundaries, every change has a control trail, and every architectural decision and production risk remains in human hands. Because in the end, transforming the delivery model isn't about how much code AI can generate, but about how humans and agents can work together in a measurable and accountable way.