Performance Metrics für Human-Agent Teams
Stell dir vor, dis Finance-Team fangt a, en Agent für de monatlich Abschluss z'bruuche. De Agent holt d'Date us em ERP, schribt en Draft-Kommentar und bereitet d'Beleg für jedes Konto vor. S'Controllership-Team het uf einisch meh Zit. D'Frage, wo ufchömed, sind nüm "Wie viel Schtund hend mer gspart?", sondern "Isch d'Qualität vom Abschluss würkli besser?" oder "Hilft de Agent em Team, Anomalie z'finde, wo vorher überse worde sind?"
Söttigi Froge chömed i vilne Firme uf. Wenn de Pilot vo agentic AI i paar Funktione lauft – sei's im Finance Close, Procurement Intake, Customer Operations oder IT Incident Triage – merkt s'Management, dass di alte Metrik nüm länged. Produktivität pro FTE, Utilization, Transaktionsvolumen und grundlegendi SLA sind no nützlich, aber si erfasst nöd, was würkli passiert, wenn Mönsch und Agent zäme schaffed.
S'Problem isch: Ohni di richtige Metrik fallt e Firma leicht i zwei Illusione. Di erschti isch de Demo-Effekt: S'Syschtem gseht us wie neui Technik, reagiert schnäll, d'Oberfläche isch überzügend – aber de operativ Impact isch chli. Di zweiti isch d'Automations-Vanity: D'Firma isch stolz uf d'Aazahl vo Task, wo "automatisiert" sind, aber d'Chöste, s'Risiko oder de Ufwand für d'Prüefig vom Mönsch stigt.
Worum di alte Metrik nüm länged
Di traditionelle Metrik sind us eme relativ klare Operationsmodell entstande: De Mönsch macht d'Arbet, s'Syschtem understützt, und de Output wird über Volume, Zit und Chöste gmesse. I dem Modell sind FTE-Utilization, Durchsatz, Backlog und SLA guet gnueg. Aber wenn de Agent aafangt, Teil vo de Arbet z'übernäh – Kontext läse, Tool ufruefe, Draft vorbereite, Fäll routiere, limitierti Aktione usfüere und nur zum Mönsch eskaliere, wenn nötig – denn ändert sich d'Arbetsstruktur grundlegend.
En einzelne Business-Outcome wird nüm vo einere Aart Arbet produziert. Er wird vo Digital Labor, Human Oversight, Workflow Orchestration, Datequalität und operative Guardrails zäme brocht. Wenn d'Firma di alte Metrik einzeln wiiter bruucht, chömed Verzerrige.
Nimm zum Bischpil de Finance Close. D'Utilization vom Controllership-Team cha sinke, wil de Agent d'Evidenz-Samlig und de Draft-Kommentar übernimmt. Mit alte Auge gseh, gseht das us wie "Mönsch-Kapazität isch underbrucht". Aber in Woorheit verlageret sich d'Mönsch-Kapazität uf d'Prüefig vo Material, Root-Cause-Analyse und Business Partnering. Weniger manuelli Arbet heisst nöd immer weniger Wert. Manchmal isch es es Zeiche, dass de Operating Model besser wird.
I de Customer Operations cha de Agent d'Aazahl vo Tickets pro Tag erhöhe. Aber wenn viel Fäll vom Supervisor müend korrigiert werde, oder de Kunde nomal aalüte muess, wil s'Problem nöd würkli glöst isch, denn isch de höchi Durchsatz irreführend. I de Shared Services cha de Agent schnäll uf fascht alli Aafrage antworte. Aber wenn die Antwort nume en Bständigung oder en generische Text isch, gseht d'SLA grüen us, aber d'Lösigsqualität isch schlächt. I Procurement oder IT Operations cha de Agent d'Arbet uf Level 1 reduziere. Aber wenn unauthorized Tool Calls, Policy-Verstöss oder falschi Routing zuenämed, denn werded di "gsparte" Chöste hinde use tür bezahlt.
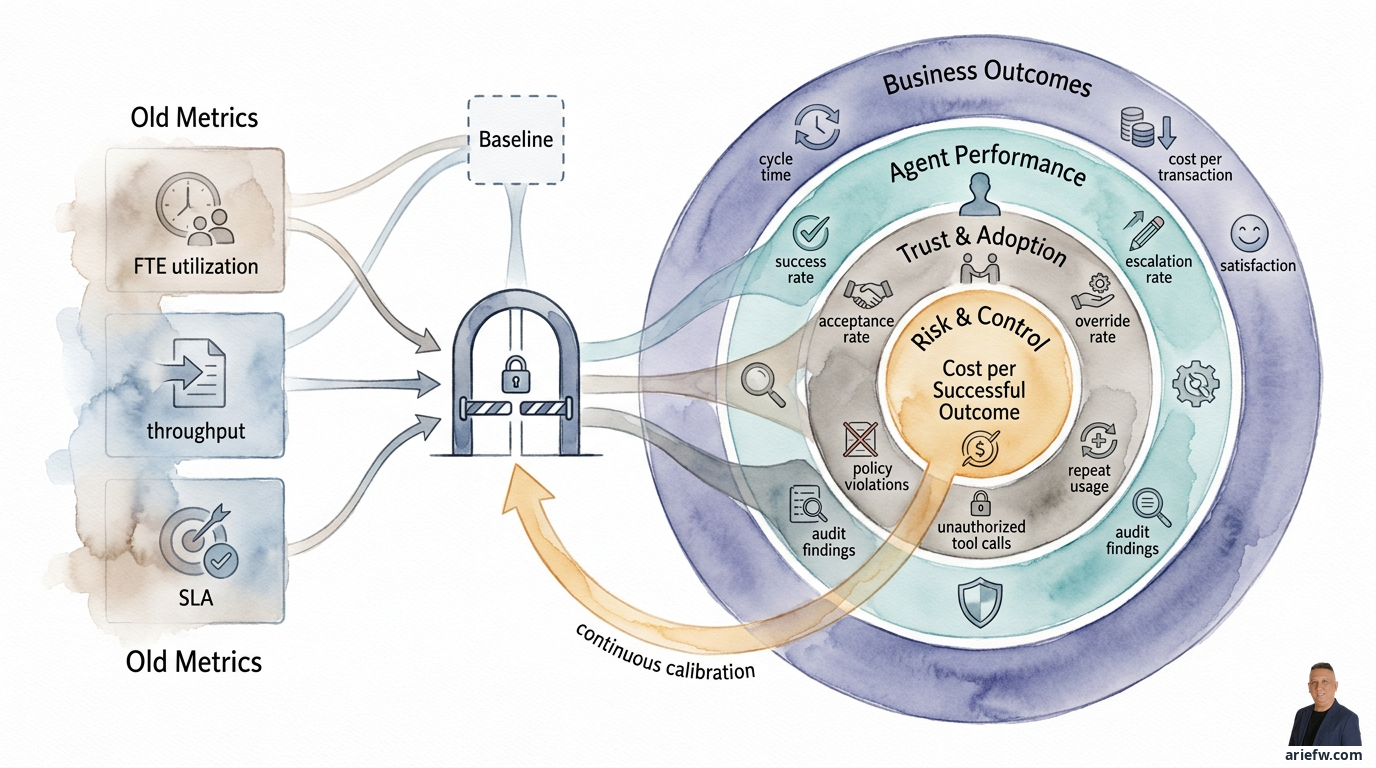
Drum bruucht d'Firma neui Dimensions für d'Messig. Mindeschtens füfi müend i d'Scorecard: Business Outcome, Autonomiegrad, Exception und Escalation, Trust und Adoption, und d'Effektivität vo de Kontrolle. Ohni das isch es schwirig, en Pilot vo agentic AI z'unterscheide – isch es en interessante Versuech oder en Fähigkeit, wo würkli skaliert werde sött?
Business Metrics: Fang bim Outcome a, nöd bi de Aktivität
Di erschti Schicht isch immer s'Gschäft. De Agent isch nöd s'Ziel. De Agent isch en neue Wäg, zum en Outcome z'erschaffe. Drum müend di wichtigschte Metrik immer no d'Froog beantworte: Isch de Gschäftsprozess besser worde, sit de Agent im Isatz isch?
Einigi vo de relevanteschte Metrik sind Cycle Time, Cost per Transaction oder Cost per Case, Durchsatz, SLA-Erfüllig, Kundezfrideheit oder interni Benutzerzfrideheit, und Revenue Leakage oder Loss Avoidance für spezifischi Use Cases. Jedes Gebiet het en chli andere Fokus.
Im Finance Close misst d'Close-Zit, d'Zit für d'Lösig vo Exception, d'Aazahl vo Kontene, wo z'spät prüeft werded, d'Qualität vom Draft-Kommentar und de Backlog vo Issue, wo i di nöchschti Periode mitgnoh werded. Wenn de Close Agent nume s'Drafting beschlünigt, aber de Bottleneck vo de Prüefig nöd reduziert, isch de Business Value no limitiert.
I de Procurement Operations misst de Cycle Time vom Intake bis zur PO, de Prozentsatz vo Aafrage, wo vo Aafang a uf em richtige Wäg sind, d'Rework-Rate, d'Ihaltig vo de Sourcing-Policy und d'Zfrideheit vom interne Requester. En Agent, wo schnäll isch, aber oft falsch klassifiziert, erhöht d'Arbet vom Buyer, statt si z' reduziere.
I de Customer Operations misst d'First-Contact Resolution, d'durchschnittlichi Lösigsziit, d'Repeat-Contact-Rate, d'Kundezfrideheit und de Wert vo unnötige Refunds oder Concessions. I de IT Operations misst d'Mean Time to Triage, d'Mean Time to Resolve, de Incident Backlog, de Change Failure Impact und d'Qualität vom Handoff vom Agent zum Engineer. I de Supply Chain misst d'Exception-Resolution-Zit, de Service Level, d'Inventory Availability, d'Expedite-Chöste und de Impact uf d'Order Fulfillment.
Ein Disziplin, wo oft vergesse wird, isch d'Baseline vor de Implementierig. Viel Team startet de Agent und vergliicht d'Ergebnis mit eme Gfühl, nöd mit ere echte Baseline. Aber ohni Baseline cha d'Firma nöd säge, ob de Cycle Time würkli besser isch, ob d'Chöste pro Outcome gsunke sind, oder ob d'Verbesserig vo andere Faktor chunnt – wie Policy-Änderige, Dateverbesserige oder es Redesign vom manuelle Prozess. Mindeschtens vor em Live-Gang sött d'Firma s'aktuelle Fall-Volume, d'Lösigsziite, d'Error- oder Rework-Rate, d'Betriebschöste und d'Qualität vom Outcome dokumentiere.
D'Firma muess au ufpasse mit de Value Attribution. Nöd alli Verbesserige nach de Implementierig vom Agent chömed vom Agent. De Cycle Time im Procurement cha sinke, wil d'Approval Matrix vereifacht worde isch, nöd nume wil de Agent de Intake macht. D'Qualität vom Close cha besser werde, wil d'Date-Mapping verbesseret worde isch. D'Kundezfrideheit cha stige, wil d'Knowledge Base grüezt worde isch. Das isch kei Problem – oft chunnt de Wert us de Kombination vo Prozess-Redesign, Date-Cleanup und Agent. Aber d'Firma muess ehrlich si in de Value Attribution. Wenn alli Verbesserige als Ergebnis vo AI deklariert werded, wird de Business Case brüchig und d'Governance verlürt Glaubwürdigkeit.
Agent Performance Metrics: D'Qualität vo Digital Labor messe
Nach em Business Outcome isch di zweiti Schicht d'Leistig vom Agent sälber. Das isch wichtig, wil en guete Business Metric nöd heisst, dass de Agent gsund isch. Es cha si, dass s'Gschäftsergebnis besser wird, aber d'Compute-Chöste stiged, d'Correction-Rate isch hoch, oder de Supervisor trait im Hintergrund e grossi Lascht.
Einigi zentrali Metrik, wo überwacht werde müend, sind d'Success Rate, d'Escalation Rate, d'Tool Failure Rate, d'Correction Rate, d'Hallucination Rate und d'Confidence Calibration.
D'Success Rate isch nöd nume "de Agent het en Antwort gäh". Definier Success als en Outcome, wo fertig isch und kei materielli Korrektur bruucht. Im Service Desk heisst Success, dass de Request richtig erledigt isch, nöd nume s'Ticket zuegmacht. Im Finance heisst Success, dass de Draft oder d'Empfählig vom Reviewer mit minimale Korrekture cha bruucht werde. Im Procurement heisst Success, dass de Request richtig routiert isch und kei Rework uslöst.
D'Escalation Rate zeigt, wie viel Fäll zum Mönsch müend. Das isch en wichtige Metrik, aber er muess im Kontext gläse werde. Z'hoch heisst, de Agent isch z'konservativ oder no nöd gnueg usgreift. Z'nidrig heisst, de Agent isch villicht z'aggressiv und riskiert, Fäll z'überse, wo sötted eskaliert werde. S'Ziel isch nöd immer "so nidrig wie möglich", sondern passend zum Risk Tier und Workflow Design.
Vieli Fähler vom Agent chömed nöd vom Reasoning, sondern vo de Integration: API fählt, Date sind nöd verfüegbar, d'Permission isch falsch, oder s'Tool het en Timeout. Wenn d'Tool Failure hoch isch, lyt s'Problem bi de Architektur und em Platform, nöd nume bim Modell.
D'Correction Rate isch eini vo de ehrlichschte Metrik. Wie oft muess de Mönsch de Output vom Agent korrigiere? Die Metrik isch sehr nützlich bi Draft-Kommentar im Finance, Empfählige für Kundeantwort, Klassifikation im Procurement Intake, Incident Triage oder Zämmefassige vo Exception in de Supply Chain. Wenn d'Correction Rate hoch isch, passiert en scheinbari Produktivität: De Agent gseht aktiv us, aber de Mönsch macht d'Arbet nomal.
Für Workflow, wo Reasoning uf Basis vo Dokument, Knowledge oder Enterprise-Date bruucht, muess d'Firma verfolge, wie oft de Agent e Policy zitiert, wo's nöd git, Fakten ableitet, wo nöd dur d'Evidenz gstützt sind, oder en überzügendi aber falschi Antwort git. Nöd alli Organisatione chönd d'Hallucination Rate perfekt messe, aber Stichprobe-Prüefige und Audit vo Fäll chönd en erschte Indikator gäh.
D'Confidence Calibration isch au wichtig. En guete Agent isch nöd nume oft richtig, sondern weiss au, wenn er nöd sicher isch. Wenn höchi Confidence grad bi Fäll uftaucht, wo oft falsch sind, isch d'Calibration schlächt. Das isch gföhrlich, wil d'Benutzer de Output, wo sicher tönt, eifacher glaubed.
Wenn d'Firma en Orchestrator und mehreri Task-Agent bruucht, sölled zwei wichtigi Metrik dezuecho: d'Handoff Quality – ob de Kontext richtig zwüsched de Agent oder zum Mönsch übergeit – und d'Orchestration Failure – wie oft de Workflow fählt, wil d'Reihefolg, d'Abhängigkeite oder s'Routing falsch sind. Im IT Delivery zum Bischpil chönd de Requirement Agent, de Coding Agent, de QA Agent und de Reviewer Agent einzeln guet si, aber de ganz Workflow fählt, wenn de Handoff schlächt isch.
Zum Schluss: Vergiss d'Cost per Successful Outcome nöd. Token, Compute, Retrieval und Tool Invocation chönd still und heimlich stige, wenn de Scale wachst. Drum miss nöd nume Cost per Run oder Cost per Prompt. Miss d'Cost per Successful Outcome. Das hilft, di strategischere Froge z'beantworte: Isch de Agent würkli günstiger als s' alte Modell? Isch di zuesätzlich Autonomie de Chöste wert? Und git's Use Cases, wo technisch funktioniere, aber wirtschaftlich nöd gsund sind?
Trust und Risk Metrics: Wil Adoption ohni Vertraue nöd blybt
Human-Agent Teams werded nöd stabil, wenn d'Benutzer em Syschtem nöd vertraued, oder wenn d'Risk Function s'Gfühl het, dass d'Kontrollen unscharf sind. Drum muess d'Firma zweierli messe: Trust und Risk.
Für Trust sind einigi vo de nützlichschte Indikatore d'User Acceptance Rate, d'Override Rate, d'Explanation Usefulness und d'Repeat Usage. D'User Acceptance Rate zeigt, wie oft d'Benutzer d'Empfählig oder de Output vom Agent akzeptiered, ohni en Totalersatz z'mache. D'Override Rate zeigt, wie oft de Mönsch d'Entscheidig vom Agent ablehnt oder ersetzt. En höchi Override Rate cha uf nidrigi Qualität, nidrigs Vertraue oder e Policy, wo nöd passt, hiiwise. Aber en Override Rate vo Null isch au nöd automatisch guet – villicht sind d'Benutzer passiv oder nöd kritisch gnueg.
D'Explanation Usefulness misst, ob d'Erklärig vom Agent em Benutzer hilft, de Grund hinter de Empfählig z'verstoh. I Domain wie Finance, Procurement und IT Operations isch en nützlichi Erklärig oft wichtiger als en schnälli Antwort. Ohni das isch es schwirig, Vertraue ufzbaue. D'Repeat Usage isch en eifache aber starchi Indikator: Chömed d'Benutzer wider zum Agent, wenn si nöd dezue zwunge werded? Wenn d'Lüt de Agent nume bruuche, wil si's müend, isch d'Adoption no oberflächlich.
Für Risk muess die Schicht zäme mit Risk, Compliance, Security und Internal Audit gläse werde. Einigi zentrali Metrik sind Policy Violations, Data Exposure Incidents, Unauthorized Tool Calls und Audit Findings. Policy Violations chönd si, wenn de Agent Empfählige usserhalb vo de delegierte Authority git, d'Approval Threshold verletzt oder Fäll uf en Wäg routiert, wo nöd zur Policy passt. Data Exposure Incidents messed, ob de Agent Date zeigt, wo de Benutzer oder es bestimmts Tool nöd sött zgrie ha – das isch sehr wichtig für Workflow, wo ERP, HRIS, CRM oder Kundedate berüehred.
Unauthorized Tool Calls messed, ob de Agent probiert oder es schafft, es Tool z'rufe, wo nöd erlaubt isch. Die Metrik isch wichtig, vor allem bi Agent, wo a Transaktionssyschtem oder Workflow Execution aaghängt sind. Audit Findings sind d'Ergebnis vo interne Audit oder Compliance-Prüefige vo de Agent-Operatione. Wenn de Audit Trail schwach isch, d'Evidenz nöd vollständig oder de Approval-Wäg nöd klar, muess de Scale zruggghalte werde, au wenn d'Business Metric guet usgseht.
Scorecard: Value, Quality, Risk, Adoption
Am Schluss bruucht d'Firma eini Scorecard, wo nöd eisitig isch. En eifachi Struktur cha füf Dimensione umfasse. Value wird gmesse mit Cycle Time, Cost per Transaction, Durchsatz, SLA und Kundezfrideheit oder interni Zfrideheit. Quality wird gmesse mit Success Rate, Correction Rate, Hallucination Rate und Handoff Quality. Adoption und Trust wird gmesse mit Acceptance Rate, Override Rate, Repeat Usage und Explanation Usefulness. Risk und Control wird gmesse mit Policy Violations, Unauthorized Tool Calls, Data Exposure Incidents und Audit Findings. Efficiency of Digital Labor wird gmesse mit Cost per Successful Outcome, Tool Failure Rate und Escalation Rate.
So e Scorecard hilft de Exekutive, zwei Fähler z'vermide: nume de Value z'gseh ohni s'Risiko, oder z'stark ufs Risiko z'fokussiere, ohni de würkli Outcome z'messe.
Praktischi Implikatione
Nachdem du das Framework verstande hesch, gits es paar Entscheidige, wo jetzt tröffe werde müend. Erschtens: Leg d'Unit of Measurement fescht. Misch du pro Task, pro Case, pro Transaction oder pro Successful Outcome? Für Human-Agent Teams isch di letschti Massstaab meistens am nützlichschte. Zweitens: Vereinbar e Baseline vor em Scale. Start de Agent nöd ohni Vergliichsdate für Cycle Time, Chöste, Qualität und Exception Rate.
Drittens: Bau e Scorecard uf, wo über d'Funktione goht. CIO, COO, Risk und de Prozess-Besitzer müend sich uf en Mix vo Metrik für Value, Quality, Adoption und Risk einige – nöd jede mit em eigene Dashboard. Viertens: Definier, wär für jedi Metrik verantwortlich isch. De Business Owner het d'Business Outcome, s'Platform Team d'Reliability und d'Chöste, de Supervisor d'Correction und Escalation Pattern, de Risk Owner d'Control Metrics. Fünftens: Leg d'Schwelle fescht für Scale, Pause oder Rollback. Zum Bischpil: Wänn isch d'Correction Rate z'hoch? Wänn macht en Policy Violation, dass de Use Case müess aaghalte werde? Oder wänn isch d'Cost per Successful Outcome nüm vernünftig?
Einigi Gfahresignal sötted beachtet werde. Wenn de Erfolg vor allem über d'Aazahl vo Automations oder d'Reduktion vo Arbetsschunde gmesse wird, wenn's kei glaubwürdigi Baseline vor de Implementierig git, wenn d'Gschäfts-, IT- und Risk-Team underschidlichi Definitione vo "Success" hend, wenn Override und Correction hoch sind, aber nöd im Verbesserigs-Backlog landed, wenn d'Token- und Compute-Chöste stiged, aber nöd mit em Outcome verchnüpft sind, wenn de Audit Trail nöd usreicht, zum erkläre, worum de Agent e bestimmti Aktion gmacht het, wenn d'Benutzer de Agent nume bruuche, wil si's müend, nöd wil's hilft, oder wenn Policy Violations als "chliises Rüsche" abtoo werded, solang d'Business Metric guet usgseht – denn isch das Thema no nöd bereit für de Scale.
E reflektivi Frog für CIO, COO, CHRO und Transformation Leader: Wenn du morn söttsch bewise, dass es Human-Agent Team i dinere Firma würkli Wert schafft – chöntsch du nume en Demo und d'Nutzerzahle zeige, oder hesch scho e Scorecard, wo Outcome, Qualität, Adoption, Chöste und Kontrolle usgliche zeigt? Das isch de Underschid zwüsched eme interessante AI-Experiment und eme agentic Operating Model, wo bereit isch für de Scale.