90-Day Roadmap for Building an Agentic Enterprise Pilot
Many companies have moved past the initial phase of AI curiosity. Tools have been tried, copilots have been used, and several proofs of concept have been presented. However, the more critical question now is no longer "is agentic AI interesting?" but rather: how do you build a pilot that is real enough to prove value, safe enough to run, and disciplined enough to serve as a foundation for scale?
This is where many organizations stumble. They rush to build demos without a baseline. Or conversely, they spend too long crafting a strategy and never actually get to a real workflow. Yet, agentic transformation will not be born from presentations. It is born from operational pilots that are well-scoped, properly measured, and honestly reviewed.
This article concludes our series on operating models, workforce, metrics, and governance with one practical goal: to provide a 90-day plan for building a measurable and safe agentic enterprise pilot.
The underlying principle is simple: start with one valuable domain, limit the scope to control risk, explicitly design agents and controls, test on real workflows (not just prompts), and then make a decision to scale, redesign, or stop based on evidence.
This roadmap is not a universal recipe. It is best suited for companies that already have reasonably stable core processes, a clear business sponsor, and a minimum level of readiness in data, integration, and governance. If those foundations are not in place, the 90 days can still be valuable—but the outcome might not be a live pilot, but rather a conscious decision that the company needs to strengthen its foundations first.
Why 90 Days is the Right Horizon
For an agentic enterprise pilot, 90 days is typically long enough to generate operational evidence, yet short enough to maintain execution focus. Too short, and the team only has time to create a demo. Too long, and the pilot turns into a mini transformation program that loses its discipline.
Within 90 days, a company should be able to answer five core questions. First, does the chosen workflow actually have a real value pool? Second, can the agent operate within safe autonomy boundaries? Third, are users genuinely helped, not just impressed? Fourth, are the controls, audit trail, and monitoring sufficient for limited production? Fifth, are the economics and operational fit strong enough for scale?
If these five questions cannot be answered, the organization does not yet have a healthy foundation for expanding the agentic model to other domains.
Days 1–15: Choose the Right Domain and Build a Baseline
The first phase is not about technology. It's about choosing the right battlefield. The most common mistake at the start is selecting a use case that is too easy but unimportant, or one that is too ambitious and fails before providing any learning. The first pilot should sit in the middle: high business value, reasonably available data, strong sponsorship, and manageable risk.
A good domain for a pilot typically has these characteristics: the workflow occurs frequently, there is a real bottleneck or backlog, there are many manual handoffs or exception handling steps, source systems and data are relatively accessible, the process owner is clear, and pilot failure does not immediately create uncontrollable material risk.
Examples that often make sense include finance close support for evidence gathering, variance triage, and draft commentary; procurement intake for request classification, policy checks, and routing; customer operations for case summarization, response drafting, and escalation triage; IT operations for incident triage, runbook recommendations, and change readiness checks; supply chain exception handling for exception detection, context assembly, and initial mitigation recommendations; and shared services or GCCs with high volume, relatively standard processes, and easier centralized governance.
Conversely, avoid domains where the underlying process is chaotic, policies are undocumented, data is scattered without an owner, or where the pilot touches material decisions without clear guardrails.
Once the domain is chosen, the team must map the real workflow from start to finish. Not just where AI could be inserted, but the main process steps, handoffs between teams, the most frequent exceptions, systems used, documents or knowledge referenced, approval points, and the most costly or slowest pain points.
In procurement intake, for example, a request comes in from a business user, gets classified, checked against policy, verified for vendor or category, and then routed to a catalog, sourcing, or special approval path. In many companies, the bottleneck isn't a single step, but a combination of misclassification, incomplete documents, and repeated handoffs.
In finance close, the numbers are already in the ERP or consolidation tool, but the team still has to chase inputs, gather evidence, flag variances, and draft explanations. An agent might not need to close the books, but it could be very useful for orchestration and triage.
Without a baseline, the pilot will end up based on opinion. At a minimum, establish initial metrics such as cycle time, cost per case or cost per transaction, error or correction rate, backlog or queue size, escalation rate, and user satisfaction or internal stakeholder satisfaction. Not all metrics need to be perfect, but they must be sufficient to compare the state before and after the pilot.
In this phase, one critical decision must also be made: what is the definition of pilot success? For example, cycle time decreases for a specific subset of cases, the agent's correction rate is below an agreed threshold, users accept the agent's output at a certain proportion, there are no material policy violations, and the cost per outcome is reasonable. If the definition of success is not agreed upon at the start, the pilot will be difficult to close objectively.
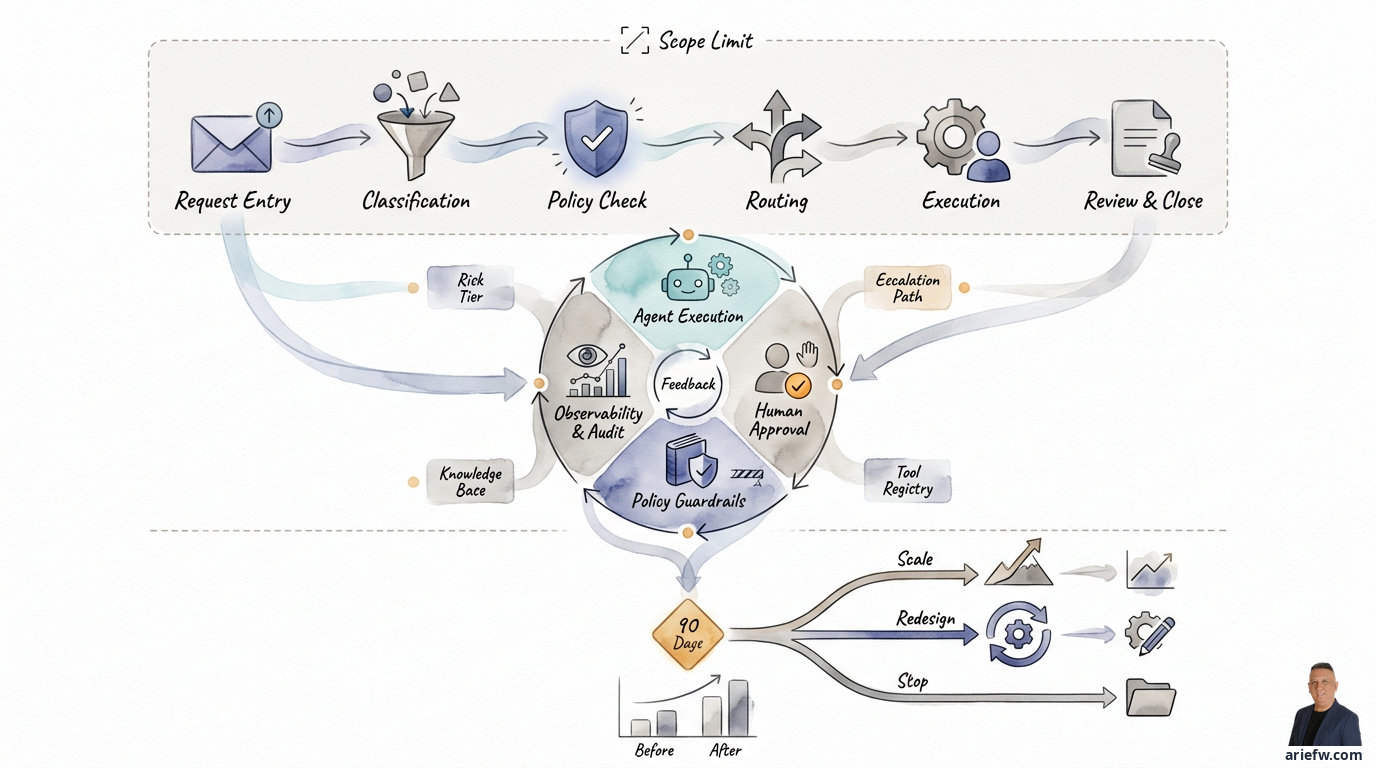
Days 16–35: Design the Agent, Autonomy Boundaries, and Controls
Only after the domain and baseline are clear should the company move to agent design. The focus of this phase is not making the agent smart, but making it clear, bounded, and auditable.
Every pilot should have an agent card—a concise document that explains the agent's operational identity. At a minimum, it should include the goal or desired outcome, the scope or cases that can and cannot be handled, the tools such as APIs, systems, or workflow engines that can be called, the data sources like knowledge bases, ERP, CRM, ticketing, or policy documents, the owners including business owner, product or agent owner, and risk owner, the risk tier (low, medium, or high based on impact), and the success criteria covering value, quality, adoption, and risk metrics.
The agent card forces the organization to stop talking abstractly. It turns an idea into an operational object that can be reviewed jointly by business, IT, security, and risk.
One of the most important decisions in the first 90 days is how much autonomy the agent should have. A healthy progression usually starts with read or monitor, where the agent only reads data and provides insights. Next is draft or recommend, where the agent prepares summaries, recommendations, or proposed actions. Then comes execute with approval, where the agent performs actions after human approval. Finally, execute with monitoring, which is only for very clearly bounded, low-risk actions.
For the first pilot, most companies should stop at the draft or recommend level, unless the use case is truly low-risk. In IT incident triage, for example, the agent can gather logs, suggest a runbook, and prepare an escalation, but not automatically change production configurations. In procurement intake, the agent can classify and route standard requests, but not create new vendors. In finance, the agent can prepare an evidence pack and draft commentary, but not make material accounting decisions.
A healthy agentic pilot always has clear answers to three questions: when must a human approve, when must a case be escalated, and what must be recorded for audit. Approval thresholds can be based on transaction value, agent confidence, case type, data sensitivity, or operational impact. Escalation paths must point to real roles, not abstract organizational boxes—for example, AP supervisor, regional controller, procurement operations lead, incident manager, or on-duty supply chain planner. Minimum audit requirements typically include the source data used, the tools or APIs called, the policies or knowledge referenced, the agent's output, the human decision, and the final outcome.
Many pilots fail not because of a bad model, but because the operational foundation wasn't ready. Four minimum components need to be in place: a knowledge base, API access, a tool registry, and a sandbox environment.
The knowledge base contains SOP documents, policies, FAQs, runbooks, or sufficiently cleaned case histories. Don't expect retrieval to work well if the knowledge is still messy. API access to core systems must be limited and need-based. The pilot doesn't need all integrations, just the ones that truly determine the outcome. The tool registry is a list of tools the agent is allowed to call, complete with access rights and usage limits. This is crucial to prevent tool sprawl and the risk of unauthorized access. The sandbox environment is a test environment realistic enough to try workflows without recklessly touching production.
The trade-off in this phase is clear: the faster the team wants to go live, the greater the temptation to cut corners on control design. That almost always becomes an expensive debt in the following weeks.
Days 36–65: Build the MVP and Test Rigorously
The third phase is where many organizations feel they are already done too quickly. Yet, an agentic MVP is not a chatbot that can answer questions. An MVP is a narrow workflow that actually works on real cases.
Choose a subset of cases that is representative enough but still manageable. For example, only a specific category of invoice exceptions, only specific close entities, only low-to-medium severity incidents, only non-strategic procurement requests, or only supply chain exceptions for one region. The goal is not to show all possibilities, but to prove that the agent can work in one real flow from start to finish.
Before the pilot goes live, the agent must be tested on historical cases. This is crucial because historical data reveals the reality of exceptions, noise, and ambiguity that don't appear in demos. Use several types of testing. Historical case testing to see if the agent produces usable output for cases that actually happened. Adversarial scenarios to see what happens if documents are incomplete, data conflicts, prompts are ambiguous, or a user tries to force the agent out of scope. Policy checks to ensure the agent remains compliant with thresholds, approval rules, and access limits. Human review to assess whether the agent's output truly helps the reviewer or just adds to their workload.
In practice, pilot iteration usually revolves around four areas. First, prompt and instruction design: does the agent understand the goal, output format, and action boundaries? Second, retrieval: is the knowledge retrieved relevant, up-to-date, and specific enough? Third, tool schema: are the API parameters, input-output structure, and error handling clear enough? Fourth, guardrails: does the agent know when to stop, ask for approval, or escalate?
In customer operations, for instance, the agent might draft a good response, but the retrieval pulls an old policy. The problem isn't the model; it's the knowledge governance. In IT operations, the agent might understand an alert, but the tool schema for log retrieval is inconsistent. The result is a triage that looks smart but isn't reliable.
An enterprise pilot doesn't need to wait for a perfect agent. What's more important is whether the agent's output is correct enough to use, clear enough to review, safe enough to run within certain limits, and consistent enough to measure. If the team spends too long chasing model perfection, the pilot will stall. If they go live too quickly without usability, trust will collapse.
Days 66–90: Run a Limited Pilot, Monitor Closely, and Make a Decision
The final phase is the moment of proof. No longer in the lab, but in limited operations.
The pilot should be explicitly bounded: one team, one entity, one transaction category, one region, or one case type. This limitation is crucial so that monitoring can be tight and rollback remains possible if problems arise. The close agent is only used for two regional entities. The procurement agent only handles low-value indirect spend requests. The incident agent is only active for specific services and only provides recommendations. The supply chain agent only monitors inbound exceptions for one product line.
During the live pilot, measure at least these five dimensions. Value: has cycle time, backlog, or throughput improved compared to the baseline? Quality: what is the correction rate, acceptance rate, and the quality of truly usable output? Risk: are there any policy deviations, unauthorized access, or decisions the agent should not have made? Adoption: are users actually using the agent and finding it helpful? Cost: what is the cost per successful outcome, and are the economics reasonable for scale?
This is where our previous articles on metrics and outcome-based operating models become highly relevant: the pilot should not be evaluated solely on whether the agent works or users like it. It must be evaluated as part of the operating model.
A healthy pilot has a short but disciplined review rhythm: what worked, what went wrong, what overrides were most frequent, what cases should not have been included, and what changes need to be made in the following week. This review should ideally involve the business owner, the agent or product owner, the operations lead, the platform or integration lead, and a risk or control representative.
On day 90, the organization must make a decision. Not extend the pilot without direction. There are three possible outcomes. Scale if the pilot shows real value, acceptable quality, controlled risk, and healthy user adoption. The scope can be expanded gradually. Redesign if value exists, but the agent design, data, workflow, or controls are not yet mature enough. The use case is still viable, but needs structural iteration. Stop if the use case turns out to be insufficiently valuable, too risky, or the foundations aren't ready. Stopping a pilot is better than forcing a scale. A decision to stop is not a failure if it's based on evidence. In fact, it's a sign that governance is working.
What Often Makes a 90-Day Pilot Fail
Before concluding, it's worth highlighting some of the most common failure patterns.
First, starting with technology instead of workflow. The team focuses too much on the model and interface, but doesn't understand the real process they aim to change. Second, not having a baseline. Everyone feels the pilot is good, but there's no evidence that outcomes improved. Third, scope is too broad. The pilot tries to touch too many systems, too many cases, or too many functions at once. Fourth, governance comes too late. Approval thresholds, audit trails, and access controls are only considered when the agent is almost live. Fifth, there is no active business sponsor. The pilot becomes a technology project, not an operating model change. Sixth, there is no final decision. The pilot keeps getting extended, but is never truly scaled or stopped.
The companies that move most effectively are usually not the most aggressive, but the most disciplined in connecting workflow, controls, metrics, and decisions.
Practical Checklist
Decisions to Make Now
Choose one pilot domain that truly matters. Don't start with a use case that is just easy to demo. Pick a workflow with real value, a clear owner, and manageable risk.
Agree on the agent's autonomy boundaries from the start. Decide if the agent will only read, prepare drafts, give recommendations, or execute specific actions with approval.
Establish the baseline and success criteria before building. At a minimum, measure cycle time, backlog, error or correction rate, user satisfaction, and relevant risk indicators.
Build controls as part of the design, not as an afterthought. Approval thresholds, escalation paths, audit trails, tool access, and a sandbox must be ready before the pilot goes live.
Set the day-90 stage-gate. From the beginning, agree that the pilot must end with a decision: scale, redesign, or stop.
Quick Readiness Checklist
- An active business sponsor exists, not just a technology sponsor.
- The end-to-end workflow is mapped, including handoffs and key exceptions.
- Baseline operational metrics are available.
- An agent card is defined with goal, scope, tools, data sources, owner, risk tier, and success criteria.
- A minimum viable knowledge base is ready and reasonably clean.
- API access and tool registry are limited to pilot needs.
- A sandbox or test environment is available.
- Human approval thresholds and escalation paths are clear.
- A monitoring dashboard exists for value, quality, risk, adoption, and cost.
- A weekly review forum is established.
Red Flags That a Pilot is Not Ready for Scale
- The pilot is still evaluated on demo quality, not operational outcomes.
- No credible baseline exists.
- Users have to correct most of the agent's output.
- The agent frequently goes out of scope or calls inappropriate tools.
- The knowledge base is not trusted by business users.
- The business sponsor is passive, and daily decisions are made only by the technology team.
- There is no sufficient audit trail to explain the agent's actions.
- Inference and integration costs are rising, but not linked to successful outcomes.
- The pilot keeps getting extended without a decision to scale, redesign, or stop.
Reflective Questions for CIOs, COOs, CHROs, and Transformation Leaders
If you could only prove one thing about agentic AI in your company within 90 days, would you choose an impressive demo—or a real workflow that is faster, safer, and more measurable?
The answer to that question usually determines whether a company is building an AI experiment, or truly starting an agentic transformation.