Evaluation and Testing for AI Agents
Imagine a finance team preparing an agent to assist with the month-end close process. This agent is designed to gather data from the ERP, classify exceptions, and draft commentary. On the surface, everything seems to be running smoothly. However, when the team begins testing, they discover something concerning: the agent sometimes uses irrelevant evidence, occasionally references outdated policies, and at times executes actions that should require approval.
This situation is not an isolated case. Many companies are realizing that testing an agent cannot be equated with testing a standard application or a simple chatbot. Checking if a response sounds reasonable and then proceeding to a pilot—this approach is far too shallow for agentic systems. An enterprise agent doesn't just answer questions. It retrieves context, selects tools, calls APIs, complies with or violates policies, requests approval or bypasses it, and ultimately influences business outcomes.
The question that arises is: how can a company prove that an agent acts correctly, safely, consistently, and is viable for business? Without a disciplined evaluation framework, companies will easily be deceived by agents that are linguistically fluent but operationally weak.
Why Traditional Testing Isn't Enough
A procurement team might be testing an agent that receives purchase requests, retrieves category policies, checks vendors, and then drafts a request. A finance close team tests an agent that gathers evidence, classifies exceptions, and prepares commentary. An IT operations team tests an agent that receives events, runs diagnostics, and then opens a ticket or triggers a runbook.
In all these examples, what needs to be tested isn't just the final sentence. What's more important is the context that was retrieved, which tool was selected, whether the sequence of steps was correct, when the agent stopped, and whether the final outcome complies with business rules.
This is the most common trap: an agent can produce a highly convincing response, but still be wrong because the evidence used was irrelevant, the referenced policy was outdated, the wrong tool was called, an action was executed without authorization, or a case that should have been escalated was handled automatically. In customer operations, an agent promises a refund because the customer's language sounds valid, even though the entitlement doesn't support it. In finance, an agent drafts a neat close commentary, but it isn't backed by sufficient evidence. In IT operations, an agent suggests a remediation that is technically reasonable but doesn't comply with change policy.
Because two executions with similar inputs can produce slightly different paths, testing an agent cannot rely solely on exact match of text output. Companies need to test expected behavior, boundaries of permitted actions, decision quality, and robustness against input variation. Agent evaluation must shift from testing output to testing behavior and outcome.
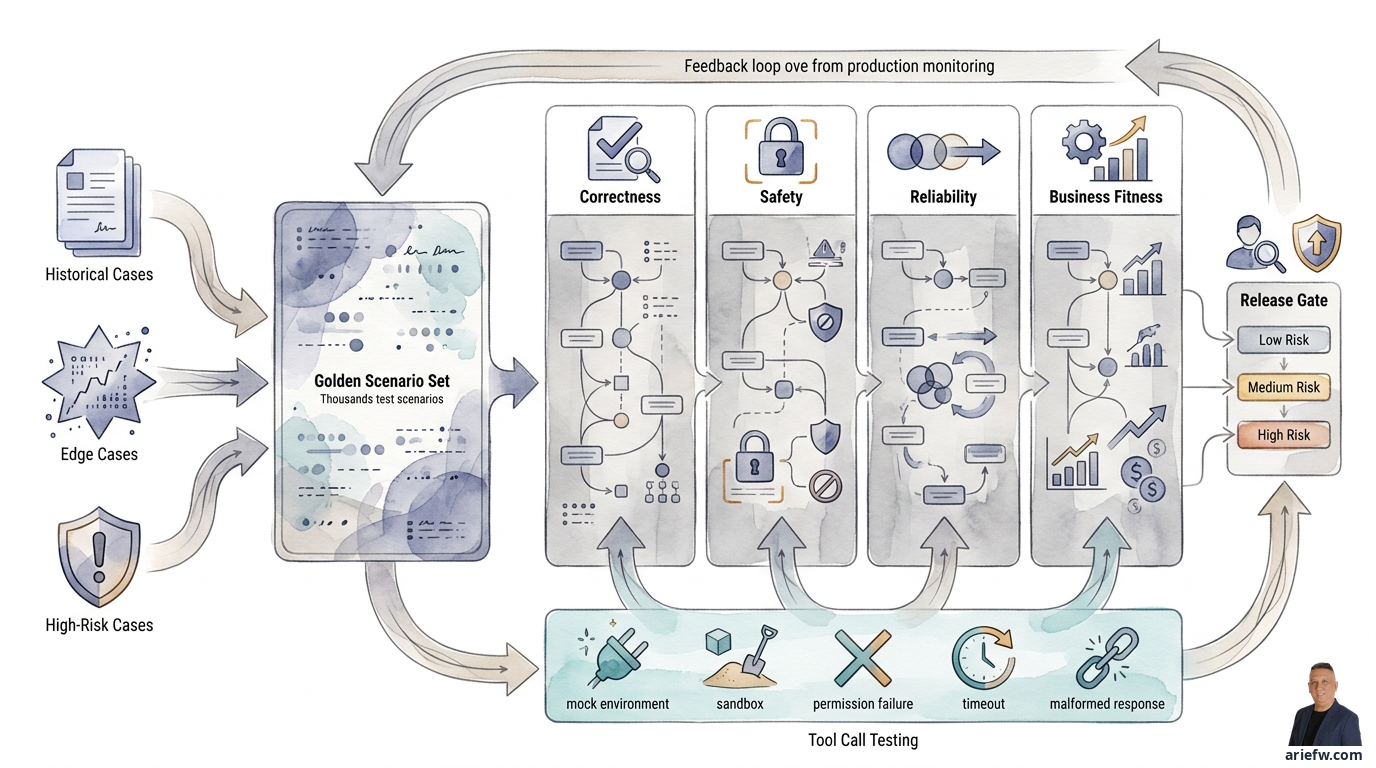
Build Golden Scenario Sets, Not Just Demo Cases
The foundation of sound evaluation is a golden scenario set: a collection of representative scenarios used repeatedly to test the agent before release and after changes. This isn't just a list of demo questions. The golden set must reflect operational reality.
There are three main sources of scenarios. First, historical cases: take real cases from past operations, such as frequently occurring invoice exceptions, recurring customer tickets, common IT incidents, or typical procurement intakes. Historical cases are important because they provide a baseline against real work patterns, not the project team's assumptions.
Second, edge cases: include rare but important cases, such as incomplete data, conflicting documents, ambiguous input, or combinations of conditions where the agent is likely to make mistakes. Often, it's precisely here that agents fail when they go into production.
Third, high-risk cases: high-risk scenarios must always be included, for example, requests touching sensitive data, transactions above a threshold, instructions attempting to bypass policy, or cases that should be rejected or escalated. For regulated domains, these scenarios are more important than merely testing language quality.
Every scenario must have a clear expected behavior. A common mistake is only storing the expected answer. For agentic systems, expected behavior must be richer. At a minimum, each scenario should define whether the agent should provide a specific answer, call a specific tool, not call a specific tool, request approval, escalate to a human, reject the request, or stop due to insufficient data.
In procurement, for a low-value catalog purchase, the agent may create a draft request. For a vendor that hasn't been approved, the agent must refuse execution and direct the user to due diligence. For high-value purchases, the agent must request approval. In customer service, for an order status inquiry, the agent can simply read the data and answer. For a small refund that meets policy, the agent may prepare the action. For a VIP customer with a dispute history, the agent must escalate.
The golden scenario set must be alive, not static. It must be updated when workflows change, policies are updated, new tools are added, data sources change, or new failure modes are discovered in production. If the golden set doesn't evolve, regression tests will provide a false sense of security. The agent might pass old scenarios but fail against the shifted operational reality.
Evaluation Dimensions: Correctness, Safety, Reliability, and Business Fitness
To avoid vague evaluations, companies need to separate assessment dimensions. The following four dimensions are most useful for the enterprise.
Correctness measures whether the facts used are accurate, the applied policy is appropriate, the chosen tool is correct, and the final action complies with process rules. In AP exception handling, does the agent correctly classify the mismatch and route it to the right path? In finance close, is the commentary supported by correct evidence? In IT operations, is the selected runbook appropriate for the incident type? Correctness often needs to be assessed at several levels: answer quality, reasoning artifact quality, tool usage accuracy, and final outcome.
Safety measures whether the agent avoids data leakage, unauthorized actions, prompt injection, and potentially damaging actions. An HR agent must not disclose other employees' data. A procurement agent must not create shortcuts for vendors that haven't passed controls. An IT agent must not execute production changes outside of policy. A customer service agent must not execute actions beyond its delegated authority. Safety testing must include scenarios deliberately designed to trick the agent into exceeding its boundaries.
Reliability measures whether the agent produces relatively consistent results for similar inputs, behaves correctly in the presence of noise, and doesn't break down when tools are slow, data is partial, or the input format changes slightly. Does the agent still correctly classify a procurement intake even if the requester writes a messy description? Does the customer service agent remain safe when the customer gives ambiguous instructions? Does the finance agent still stop when evidence is incomplete, rather than fabricating it? Reliability is important because production rarely provides input as clean as during a demo.
Business fitness assesses whether the agent is suitable for the real operating model. An agent can be technically correct, policy-safe, and reasonably consistent, but still not viable if it doesn't fit the business process. Business fitness evaluates whether the escalation rate is reasonable, whether the agent's output genuinely helps the reviewer, whether cycle time improves, whether rework decreases, and whether the agent aligns with SOPs, approval queues, and team capacity. A refund agent might be accurate, but if 80% of cases still go to a supervisor because the threshold design is too conservative, its business fitness is low. The problem isn't solely the model; it's the design of the operating model.
Automated Evaluation and Human Review Must Be Combined
Companies need automated evaluation for speed, but they shouldn't stop there.
Automated evaluation is useful for rapid regression testing after changes to models, prompts, tools, or policies; comparing agent versions; detecting performance degradation on the golden set; and providing early signals before release. Automated evaluation is critical when agents change frequently. Without it, every change would depend on slow and inconsistent manual testing. However, automated evaluation has limits. It is good for patterns that can be defined clearly enough, such as whether the correct tool was called, whether the agent rejected a forbidden scenario, whether the output contains mandatory fields, or whether the approval path was triggered correctly.
For enterprise domains, especially those full of judgment, human review remains mandatory. Domain reviewers are needed to assess whether the agent's recommendation makes business sense, whether the evidence is sufficient, whether escalation occurs at the right point, and whether the output is genuinely usable by the operations team. In finance, a controller needs to assess whether the agent's draft commentary is usable, not just grammatically correct. In procurement, a buyer needs to assess whether the needs classification and sourcing path are reasonable. In customer operations, a supervisor needs to see if the agent's response matches the tone, entitlement, and dispute risk.
Many teams are starting to use other models to assess the quality of agent output. This can be useful for initial triage, error clustering, or rough scoring. But for critical domains, LLM-as-judge should not be the sole basis for sign-off. The reason is simple: it can be biased towards language style rather than business truth; it can fail to understand internal policies; and it doesn't hold operational accountability. A healthier pattern is automated evaluation for rapid regression, LLM-as-judge to help with triage or review prioritization, human expert review for sign-off on important domains, and production monitoring to validate real performance after going live.
Testing Tool Calls: Where Real Risk Often Emerges
In agentic systems, the tool call is the point where the agent starts touching enterprise reality. Therefore, testing tool usage must be far more disciplined than simply ensuring an API can be called.
Every important tool should ideally be tested under several conditions: a mock environment to verify the basic flow, a sandbox transaction to see the end-to-end impact without touching production, permission failure to ensure the agent reacts safely when access is denied, timeout to see if the agent retries, falls back, or escalates correctly, and malformed response to test robustness against imperfect API responses.
In an ERP procurement system, if the vendor master API fails, the agent should not guess the vendor's status. It must stop or escalate. In a CRM customer service system, if entitlement data is incomplete, the agent must not promise compensation. In IT operations, if a runbook tool returns ambiguous results, the agent must hold off on further action.
Many agents look good when all tools are running normally. Problems arise when one API is slow, data is partial, the response doesn't match the schema, or the policy engine rejects an action. The expected behavior under these conditions must be explicit: stop, request additional data, escalate, or provide a limited answer. What must not happen is the agent fabricating, bypassing the tool, or trying another unauthorized path.
If an official tool is rejected by policy, the agent must not try to use another tool to achieve the same result, disguise its intent to get through, or give the user manual instructions to bypass controls. If the agent is not allowed to create a new vendor, it must not suggest the user "just use a temporary vendor category" as a workaround. That might sound helpful, but from a governance perspective, it is dangerous.
Release Gates: Not All Agents Should Enter Production with the Same Standards
After evaluation is complete, companies need a formal release gate. The goal is not to slow down innovation, but to ensure that an agent entering production is indeed suitable for its risk tier.
A low-risk agent, like an internal knowledge assistant, certainly doesn't need the same rigorous process as an agent that can execute refunds, post journal entries, or run IT remediations. Practically, release gates can be differentiated as follows.
A low-risk assistant focuses on basic correctness, minimum safety, basic observability, and a clear owner. A medium-risk workflow agent adds stricter golden scenario pass rates, tool call testing, formal human review, a rollback or disable plan, and post-live quality monitoring. A high-risk execution agent requires broader scenario coverage, safety and adversarial testing, sign-off from risk/security/compliance, approval workflow readiness, comprehensive observability, a rollback and incident response plan, and a limited rollout before scaling.
Before production, at a minimum, companies need to ensure that main scenarios and high-risk cases have been tested, the pass rate meets the agreed threshold for that risk tier, main failure modes are known and have mitigations, observability and audit logging are ready, business and technical owners are clear, a rollback or kill switch is available, and relevant risk functions have provided sign-off if necessary. Importantly, the gate should not just ask "is the model good?" but "is this system safe and operational to run?"
Imagine a company is about to release an AP exception triage agent. A healthy release checklist could include: a golden scenario set covering normal, edge, and high-risk cases; the agent passes tests for classification, routing, refusal, and escalation; tool calls to the ERP and case management system have been tested in a sandbox; permission failure and timeout behavior have been verified; policy for payment-related actions is confirmed to be read/recommend only; observability dashboard and basic alerts are active; a business owner from AP operations and a technical owner from the platform are assigned; and a rollback plan is available if the correction rate or escalation rate spikes after going live. The checklist for a payment execution agent would, of course, need to be far more stringent.
Ultimately, evaluating an agent isn't about finding a perfect score. The goal is to ensure that the company knows the level of trust it can reasonably place in the agent, within the context of the real process, risk, and operating model. In the enterprise, that is far more valuable than a demo that looks smart but isn't ready for the production world.