Evaluation dan Testing untuk AI Agents
Bayangkan sebuah tim finance sedang menyiapkan agent untuk membantu proses close bulanan. Agent ini dirancang untuk mengumpulkan data dari ERP, mengklasifikasikan exception, dan menyusun draft commentary. Di permukaan, semuanya tampak berjalan baik. Namun, saat tim mulai menguji, mereka menemukan sesuatu yang mengkhawatirkan: agent kadang menggunakan evidence yang tidak relevan, kadang merujuk policy yang sudah usang, dan kadang mengeksekusi tindakan yang seharusnya butuh approval.
Situasi ini bukan kasus langka. Banyak perusahaan mulai menyadari bahwa menguji agent tidak bisa disamakan dengan menguji aplikasi biasa atau chatbot sederhana. Cek apakah jawaban terdengar masuk akal, lalu lanjut pilot—pendekatan ini terlalu dangkal untuk agentic systems. Agent enterprise tidak hanya menjawab. Ia mengambil konteks dari retrieval, memilih tool, memanggil API, mematuhi atau melanggar policy, meminta approval atau tidak, lalu memengaruhi outcome bisnis.
Pertanyaan yang muncul kemudian adalah: bagaimana perusahaan membuktikan bahwa agent bertindak benar, aman, konsisten, dan layak secara bisnis? Tanpa disiplin evaluasi yang tepat, perusahaan akan mudah tertipu oleh agent yang fasih secara bahasa tetapi lemah secara operasional.
Mengapa Testing Tradisional Tidak Cukup
Tim procurement mungkin sedang menguji agent yang menerima permintaan pembelian, mengambil policy kategori, memeriksa vendor, lalu membuat draft request. Tim finance close menguji agent yang mengumpulkan evidence, mengklasifikasikan exception, lalu menyiapkan commentary. Tim IT operations menguji agent yang menerima event, menjalankan diagnostik, lalu membuka tiket atau memicu runbook.
Dalam semua contoh ini, yang perlu diuji bukan hanya kalimat akhir. Yang lebih penting justru konteks apa yang diambil, tool apa yang dipilih, apakah urutan langkahnya tepat, kapan agent berhenti, dan apakah outcome akhirnya sesuai aturan bisnis.
Ini jebakan paling umum: agent bisa menghasilkan respons yang sangat meyakinkan, tetapi tetap salah karena evidence yang dipakai tidak relevan, policy yang dirujuk sudah usang, tool yang dipanggil salah, tindakan dieksekusi tanpa izin, atau kasus yang seharusnya dieskalasi justru ditangani otomatis. Di customer operations, agent menjanjikan refund karena bahasa pelanggan terdengar valid, padahal entitlement tidak mendukung. Di finance, agent menyusun commentary close yang rapi, tetapi tidak didukung evidence yang cukup. Di IT operations, agent menyarankan remediasi yang masuk akal secara teknis, tetapi tidak sesuai change policy.
Karena dua eksekusi dengan input yang mirip bisa menghasilkan jalur yang sedikit berbeda, testing agent tidak bisa hanya berbasis exact match pada output teks. Perusahaan perlu menguji perilaku yang diharapkan, batas tindakan yang diizinkan, kualitas keputusan, dan robustness terhadap variasi input. Evaluasi agent harus bergerak dari testing output ke testing behavior and outcome.
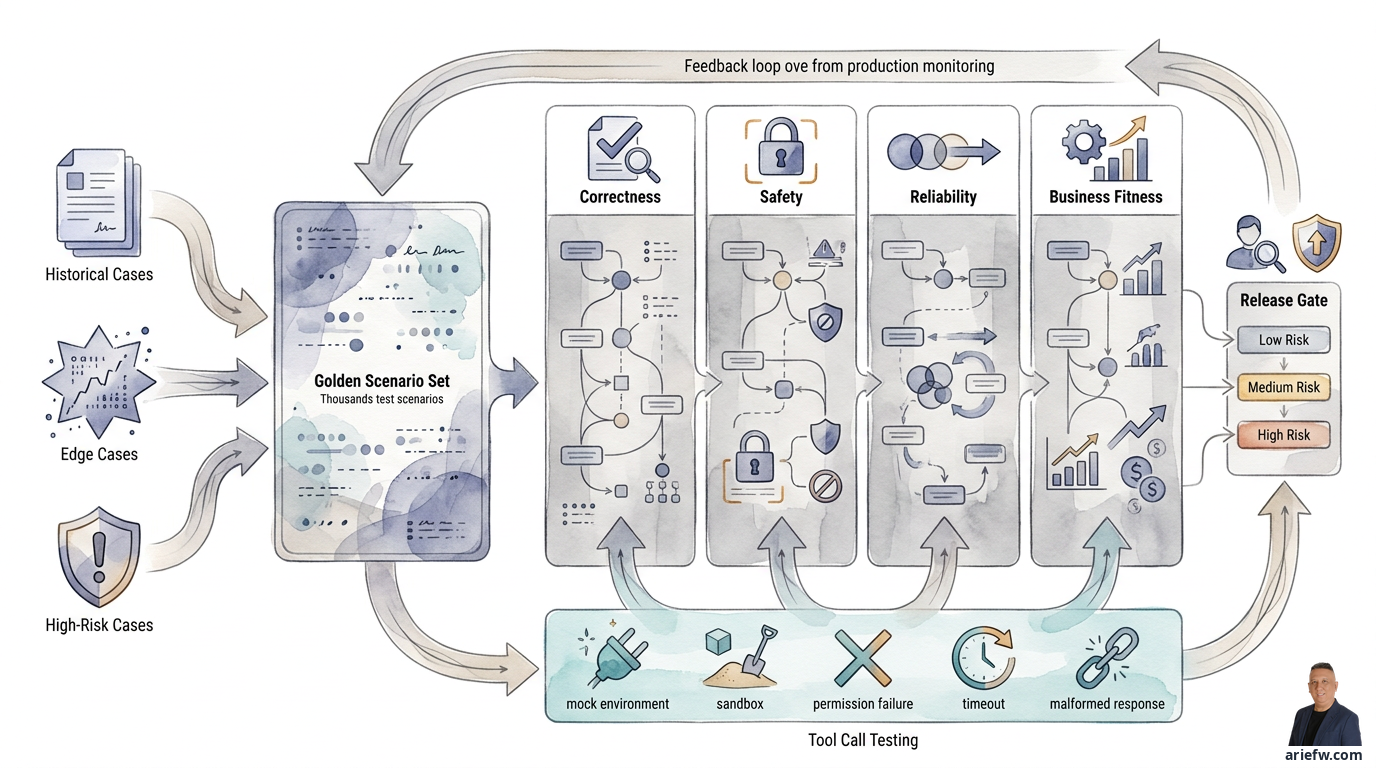
Bangun Golden Scenario Sets, Bukan Sekadar Demo Cases
Fondasi evaluasi yang sehat adalah golden scenario set: kumpulan skenario representatif yang dipakai berulang untuk menguji agent sebelum release dan setelah perubahan. Ini bukan sekadar daftar pertanyaan demo. Golden set harus mencerminkan realitas operasi.
Ada tiga sumber utama skenario. Pertama, historical cases: ambil kasus nyata dari operasi sebelumnya, seperti exception invoice yang sering muncul, tiket pelanggan yang berulang, insiden TI yang umum, atau intake procurement yang tipikal. Kasus historis penting karena memberi baseline terhadap pola kerja nyata, bukan asumsi tim proyek.
Kedua, edge cases: masukkan kasus yang jarang tetapi penting, seperti data tidak lengkap, dokumen bertentangan, input ambigu, atau kombinasi kondisi yang membuat agent mudah salah. Sering kali justru di sinilah agent gagal saat masuk production.
Ketiga, high-risk cases: skenario berisiko tinggi harus selalu ada, misalnya permintaan yang menyentuh data sensitif, transaksi di atas threshold, instruksi yang mencoba mem-bypass policy, atau kasus yang seharusnya ditolak atau dieskalasi. Untuk domain regulated, skenario ini lebih penting daripada sekadar menguji kualitas bahasa.
Setiap skenario harus punya expected behavior yang jelas. Kesalahan umum adalah hanya menyimpan jawaban yang diharapkan. Untuk agentic systems, expected behavior harus lebih kaya. Minimal, setiap skenario sebaiknya mendefinisikan apakah agent seharusnya memberi jawaban tertentu, memanggil tool tertentu, tidak memanggil tool tertentu, meminta approval, mengeskalasi ke manusia, menolak permintaan, atau berhenti karena data tidak cukup.
Di procurement, untuk pembelian katalog bernilai rendah, agent boleh membuat draft request. Untuk vendor yang belum approved, agent harus menolak eksekusi dan mengarahkan ke due diligence. Untuk nilai tinggi, agent harus meminta approval. Di customer service, untuk pertanyaan status order, agent cukup membaca data dan menjawab. Untuk refund kecil yang memenuhi policy, agent boleh menyiapkan tindakan. Untuk pelanggan VIP dengan histori dispute, agent harus mengeskalasi.
Golden scenario set harus hidup, bukan statis. Ia harus diperbarui ketika workflow berubah, policy diperbarui, tool baru ditambahkan, data source berubah, atau failure mode baru ditemukan di production. Jika golden set tidak ikut berubah, regression test akan memberi rasa aman palsu. Agent mungkin lulus terhadap skenario lama, tetapi gagal terhadap realitas operasi yang sudah bergeser.
Dimensi Evaluasi: Correctness, Safety, Reliability, dan Business Fitness
Agar evaluasi tidak kabur, perusahaan perlu memisahkan dimensi penilaian. Empat dimensi berikut paling berguna untuk enterprise.
Correctness mengukur apakah fakta yang dipakai benar, policy yang diterapkan sesuai, tool yang dipilih tepat, dan tindakan akhir sesuai aturan proses. Di AP exception handling, apakah agent mengklasifikasikan mismatch dengan benar dan merutekan ke jalur yang tepat. Di finance close, apakah commentary didukung evidence yang benar. Di IT operations, apakah runbook yang dipilih sesuai jenis insiden. Correctness sering perlu dinilai pada beberapa level: kualitas jawaban, kualitas reasoning artifact, akurasi tool usage, dan outcome akhir.
Safety mengukur apakah agent menghindari data leakage, unauthorized action, prompt injection, dan tindakan yang berpotensi merusak. Agent HR tidak boleh mengungkap data karyawan lain. Agent procurement tidak boleh membuat jalur pintas untuk vendor yang belum lolos kontrol. Agent IT tidak boleh menjalankan perubahan produksi di luar policy. Agent customer service tidak boleh mengeksekusi tindakan di luar delegated authority. Safety testing harus mencakup skenario yang sengaja mencoba memancing agent keluar dari batasnya.
Reliability mengukur apakah agent memberi hasil yang relatif konsisten pada input yang mirip, tetap berperilaku benar saat ada noise, dan tidak runtuh ketika tool lambat, data parsial, atau format input berubah sedikit. Apakah agent tetap mengklasifikasikan intake procurement dengan benar meski requester menulis deskripsi yang berantakan. Apakah agent customer service tetap aman saat pelanggan memberi instruksi ambigu. Apakah agent finance tetap berhenti ketika evidence tidak lengkap, bukan mengarang. Reliability penting karena production jarang memberi input yang bersih seperti saat demo.
Business fitness menilai apakah agent cocok untuk operating model nyata. Agent bisa benar secara teknis, aman secara policy, dan cukup konsisten, tetapi tetap tidak layak jika tidak cocok dengan proses bisnis. Business fitness menilai apakah tingkat eskalasinya masih masuk akal, apakah output agent benar-benar membantu reviewer, apakah cycle time membaik, apakah rework turun, dan apakah agent cocok dengan SOP, approval queue, dan kapasitas tim. Agent refund mungkin akurat, tetapi jika 80% kasus tetap masuk supervisor karena desain threshold terlalu konservatif, maka business fitness-nya rendah. Masalahnya bukan semata model, melainkan desain operating model.
Automated Evaluation dan Human Review Harus Dikombinasikan
Perusahaan membutuhkan evaluasi otomatis untuk kecepatan, tetapi tidak boleh berhenti di sana.
Automated evaluation berguna untuk regression testing cepat setelah perubahan model, prompt, tool, atau policy; membandingkan versi agent; mendeteksi penurunan performa pada golden set; dan memberi sinyal awal sebelum release. Automated eval sangat penting ketika agent berubah sering. Tanpanya, setiap perubahan akan bergantung pada pengujian manual yang lambat dan tidak konsisten. Namun automated eval punya batas. Ia bagus untuk pola yang bisa didefinisikan cukup jelas, misalnya apakah tool yang benar dipanggil, apakah agent menolak skenario terlarang, apakah output mengandung field wajib, apakah jalur approval dipicu dengan benar.
Untuk domain enterprise, terutama yang penuh judgement, human review tetap wajib. Reviewer domain dibutuhkan untuk menilai apakah rekomendasi agent masuk akal secara bisnis, apakah evidence cukup, apakah eskalasi terjadi di titik yang tepat, dan apakah output benar-benar usable oleh tim operasi. Di finance, controller perlu menilai apakah draft commentary agent layak dipakai, bukan hanya benar secara tata bahasa. Di procurement, buyer perlu menilai apakah klasifikasi kebutuhan dan jalur sourcing masuk akal. Di customer operations, supervisor perlu melihat apakah respons agent sesuai tone, entitlement, dan risiko sengketa.
Banyak tim mulai memakai model lain untuk menilai kualitas output agent. Ini bisa berguna untuk triage awal, clustering error, atau scoring kasar. Tetapi untuk domain kritikal, LLM-as-judge tidak boleh menjadi satu-satunya dasar sign-off. Alasannya sederhana: ia bisa bias terhadap gaya bahasa, bukan kebenaran bisnis; ia bisa gagal memahami policy internal; dan ia tidak memegang akuntabilitas operasional. Pola yang lebih sehat adalah automated eval untuk regression cepat, LLM-as-judge untuk membantu triage atau prioritisasi review, human expert review untuk sign-off pada domain penting, dan production monitoring untuk memvalidasi performa nyata setelah live.
Testing Tool Calls: Tempat Risiko Nyata Sering Muncul
Dalam agentic systems, tool call adalah titik di mana agent mulai menyentuh realitas enterprise. Karena itu, pengujian tool usage harus jauh lebih disiplin daripada sekadar memastikan API bisa dipanggil.
Setiap tool penting sebaiknya diuji dalam beberapa kondisi: mock environment untuk memverifikasi alur dasar, sandbox transaction untuk melihat dampak end-to-end tanpa menyentuh produksi, permission failure untuk memastikan agent bereaksi aman saat akses ditolak, timeout untuk melihat apakah agent retry, fallback, atau mengeskalasi dengan benar, dan malformed response untuk menguji robustness terhadap respons API yang tidak sempurna.
Di ERP procurement, jika API vendor master gagal, agent seharusnya tidak menebak status vendor. Ia harus berhenti atau mengeskalasi. Di CRM customer service, jika data entitlement tidak lengkap, agent tidak boleh menjanjikan kompensasi. Di IT operations, jika runbook tool mengembalikan hasil ambigu, agent harus menahan tindakan lanjutan.
Banyak agent terlihat baik saat semua tool berjalan normal. Masalah muncul ketika satu API lambat, data parsial, respons tidak sesuai schema, atau policy engine menolak tindakan. Perilaku yang diharapkan dalam kondisi ini harus eksplisit: berhenti, meminta data tambahan, mengeskalasi, atau memberi jawaban terbatas. Yang tidak boleh terjadi adalah agent mengarang, mem-bypass tool, atau mencoba jalur lain yang tidak diizinkan.
Jika tool resmi ditolak oleh policy, agent tidak boleh mencoba memakai tool lain untuk mencapai hasil yang sama, menyamarkan intent agar lolos, atau memberi instruksi manual kepada user untuk mem-bypass kontrol. Jika agent tidak boleh membuat vendor baru, ia tidak boleh menyarankan user "gunakan kategori vendor sementara saja" sebagai jalan pintas. Itu mungkin terdengar membantu, tetapi secara governance justru berbahaya.
Release Gates: Tidak Semua Agent Boleh Masuk Production dengan Standar yang Sama
Setelah evaluasi dilakukan, perusahaan perlu release gate yang formal. Tujuannya bukan memperlambat inovasi, melainkan memastikan bahwa agent yang masuk production memang layak untuk risk tier-nya.
Agent low-risk seperti internal knowledge assistant tentu tidak perlu proses seberat agent yang bisa mengeksekusi refund, memposting jurnal, atau menjalankan remediasi TI. Secara praktis, release gate bisa dibedakan seperti ini.
Low-risk assistant fokus pada correctness dasar, safety minimum, observability dasar, dan owner yang jelas. Medium-risk workflow agent menambahkan golden scenario pass rate yang lebih ketat, tool call testing, human review formal, rollback atau disable plan, dan monitoring kualitas pasca-live. High-risk execution agent butuh scenario coverage yang lebih luas, safety dan adversarial testing, sign-off risk/security/compliance, approval workflow readiness, observability lengkap, rollback dan incident response plan, serta limited rollout sebelum scale.
Sebelum production, minimal perusahaan perlu memastikan skenario utama dan high-risk case telah diuji, pass rate memenuhi ambang yang disepakati untuk risk tier tersebut, failure mode utama sudah diketahui dan ada mitigasinya, observability dan audit logging siap, owner bisnis dan teknis jelas, rollback atau kill switch tersedia, dan fungsi risk terkait sudah memberi sign-off bila diperlukan. Yang penting, gate tidak boleh hanya bertanya "apakah modelnya bagus?" tetapi "apakah sistem ini aman dan operasional untuk dijalankan?"
Bayangkan perusahaan akan merilis agent AP exception triage. Checklist release yang sehat bisa mencakup golden scenario set yang mencakup kasus normal, edge, dan high-risk; agent lulus uji klasifikasi, routing, refusal, dan escalation; tool call ke ERP dan case management telah diuji di sandbox; permission failure dan timeout behavior sudah diverifikasi; policy untuk payment-related action dipastikan hanya read/recommend; observability dashboard dan alert dasar aktif; business owner AP operations dan technical owner platform ditetapkan; rollback plan tersedia jika correction rate atau escalation rate melonjak setelah live. Checklist untuk payment execution agent tentu harus jauh lebih berat daripada ini.
Pada akhirnya, evaluasi agent bukan soal mencari skor sempurna. Tujuannya adalah memastikan bahwa perusahaan tahu batas kepercayaan yang layak diberikan kepada agent, dalam konteks proses, risiko, dan operating model yang nyata. Di enterprise, itu jauh lebih berharga daripada demo yang terlihat pintar tetapi tidak siap menghadapi dunia produksi.