AIエージェントの評価とテスト
ある金融チームが、月次決算プロセスを支援するエージェントを準備していると想像してみてほしい。このエージェントは、ERPからデータを収集し、例外事項を分類し、ドラフトのコメンタリーを作成するように設計されている。表面上は、すべてが順調に見える。しかし、チームがテストを開始すると、ある憂慮すべき事態に気づく。エージェントは時として無関係なエビデンスを使用し、時には時代遅れのポリシーを参照し、承認が必要なアクションを実行してしまうことがあるのだ。
この状況は決して珍しいケースではない。多くの企業が、エージェントのテストは通常のアプリケーションや単純なチャットボットのテストとは同列に扱えないことに気づき始めている。回答がもっともらしく聞こえるかどうかを確認し、そのままパイロットに進むというアプローチは、エージェンティックシステムにはあまりにも浅はかだ。エンタープライズエージェントは、単に回答するだけではない。エージェントは検索からコンテキストを取得し、ツールを選択し、APIを呼び出し、ポリシーに従うか違反し、承認を要求するかしないか、そしてビジネス成果に影響を与える。
そこで生じる疑問は、企業はどのようにしてエージェントが正しく、安全で、一貫性があり、ビジネスとして妥当な行動をとっていることを証明できるのか、ということだ。適切な評価の規律がなければ、企業は言葉は流暢だが、運用面では脆弱なエージェントに容易に惑わされてしまうだろう。
従来のテストでは不十分な理由
購買チームは、購買依頼を受け付け、カテゴリポリシーを取得し、ベンダーを確認し、ドラフトのリクエストを作成するエージェントをテストしているかもしれない。決算チームは、エビデンスを収集し、例外事項を分類し、コメンタリーを作成するエージェントをテストしている。IT運用チームは、イベントを受け付け、診断を実行し、チケットを起票するか、Runbookをトリガーするエージェントをテストしている。
これらすべての例において、テストすべきなのは最終的な文章だけではない。より重要なのは、どのようなコンテキストが取得されたか、どのツールが選択されたか、一連のステップが適切だったか、エージェントがいつ停止すべきか、そして最終的な成果がビジネスルールに準拠しているかどうかである。
ここに最も一般的な落とし穴がある。エージェントは非常に説得力のある応答を生成できるが、使用されたエビデンスが無関係であったり、参照されたポリシーが時代遅れであったり、呼び出されたツールが間違っていたり、許可なくアクションが実行されたり、本来エスカレーションされるべきケースが自動処理されたりするため、依然として誤っている可能性があるのだ。カスタマーオペレーションでは、顧客の言葉がもっともらしく聞こえるという理由でエージェントが返金を約束するが、実際には権利が認められていない。財務では、エージェントは整然とした決算コメンタリーを作成するが、それを裏付ける十分なエビデンスがない。IT運用では、エージェントは技術的には妥当な是正措置を提案するが、変更ポリシーに準拠していない。
類似した入力でも実行ごとにわずかに異なるパスが生成される可能性があるため、エージェントのテストはテキスト出力の完全一致のみに基づくことはできない。企業は、期待される動作、許可されるアクションの境界、意思決定の質、および入力のばらつきに対するロバスト性をテストする必要がある。エージェントの評価は、出力のテストから、動作と成果のテストへと移行しなければならない。
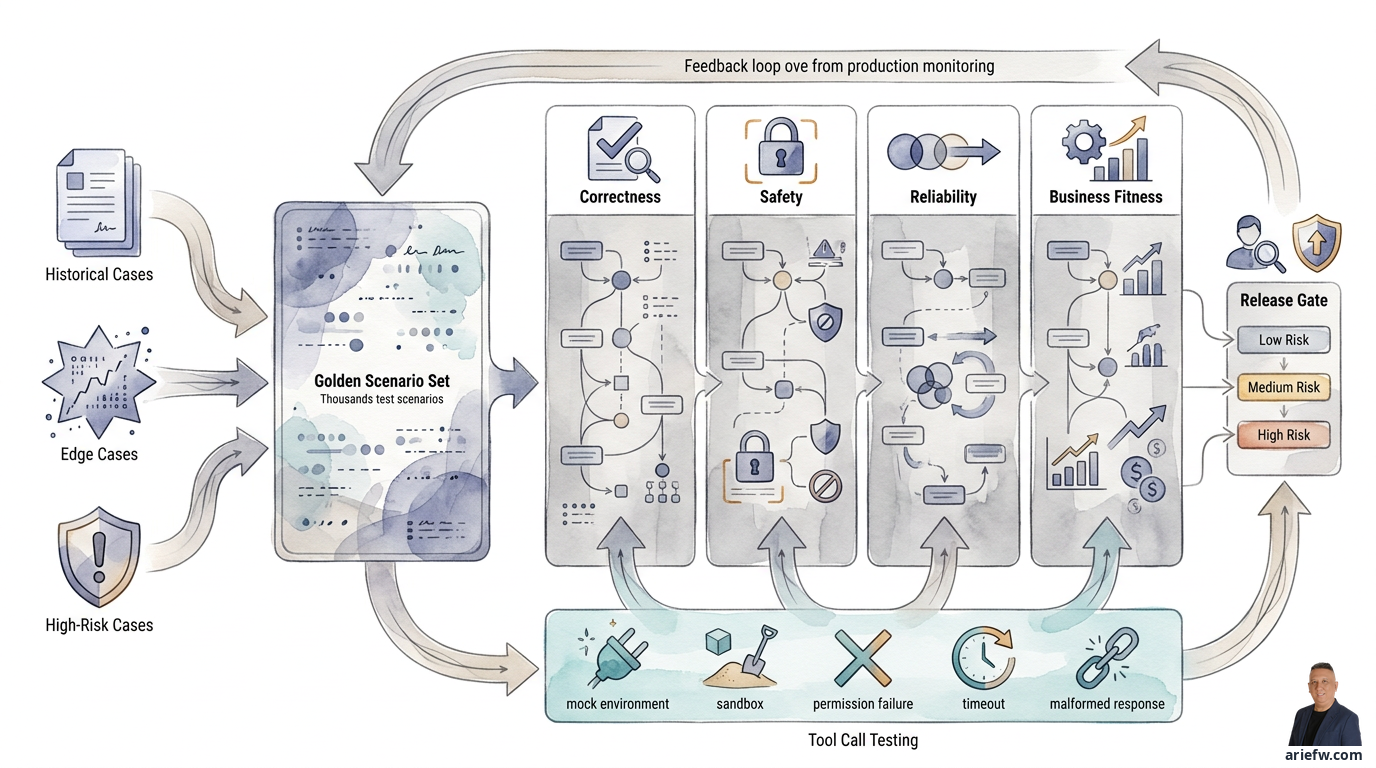
デモケースではなく、ゴールデンシナリオセットを構築する
健全な評価の基盤は、ゴールデンシナリオセットである。これは、リリース前や変更後にエージェントをテストするために繰り返し使用される、代表的なシナリオの集合体だ。これは単なるデモ用の質問リストではない。ゴールデンセットは、運用の現実を反映していなければならない。
シナリオには主に3つのソースがある。第一に、過去のケースである。過去の運用から実際のケースを採取する。例えば、頻繁に発生する請求書の例外、繰り返し発生する顧客チケット、一般的なITインシデント、典型的な購買インテークなどだ。過去のケースは、プロジェクトチームの想定ではなく、実際の業務パターンに対するベースラインを提供するため重要である。
第二に、エッジケースである。データの欠落、矛盾するドキュメント、曖昧な入力、エージェントが誤りを犯しやすい条件の組み合わせなど、稀ではあるが重要なケースを含める。多くの場合、エージェントが本番環境で失敗するのは、まさにこのようなケースにおいてである。
第三に、ハイリスクケースである。高リスクのシナリオは常に含める必要がある。例えば、機密データに触れるリクエスト、しきい値を超える取引、ポリシーを回避しようとする指示、拒否またはエスカレーションされるべきケースなどだ。規制対象のドメインでは、これらのシナリオは、単に言語の質をテストすることよりも重要である。
各シナリオには、明確な期待される動作が定義されていなければならない。よくある間違いは、期待される回答のみを保存することだ。エージェンティックシステムの場合、期待される動作はよりリッチであるべきだ。最低限、各シナリオでは、エージェントが特定の回答を返すべきか、特定のツールを呼び出すべきか、特定のツールを呼び出すべきでないか、承認を要求すべきか、人間にエスカレーションすべきか、リクエストを拒否すべきか、データ不足のために停止すべきかを定義する必要がある。
購買において、低額のカタログ購入であれば、エージェントはドラフトリクエストを作成してもよい。未承認のベンダーについては、エージェントは実行を拒否し、デューデリジェンスに誘導しなければならない。高額の場合は、エージェントは承認を要求しなければならない。カスタマーサービスにおいて、注文状況の問い合わせであれば、エージェントはデータを読んで回答すれば十分である。ポリシーを満たす少額の返金であれば、エージェントはアクションの準備をしてもよい。VIP顧客で異議申し立ての履歴がある場合は、エージェントはエスカレーションしなければならない。
ゴールデンシナリオセットは、静的なものではなく、生きているものでなければならない。ワークフローが変更されたり、ポリシーが更新されたり、新しいツールが追加されたり、データソースが変更されたり、本番環境で新たな障害モードが発見されたりした場合には、更新されなければならない。ゴールデンセットが変更に追随しなければ、リグレッションテストは誤った安心感を与えることになる。エージェントは古いシナリオには合格するかもしれないが、すでに変化した運用の現実には失敗するだろう。
評価の次元:正確性、安全性、信頼性、ビジネス適合性
評価を曖昧にしないために、企業は評価の次元を分離する必要がある。エンタープライズにとって最も有用なのは、以下の4つの次元である。
正確性は、使用された事実が正しいか、適用されたポリシーが適切か、選択されたツールが正しいか、最終的なアクションがプロセスルールに従っているかを測定する。買掛金の例外処理において、エージェントは不一致を正しく分類し、適切なルートに振り分けているか。財務決算において、コメンタリーは正しいエビデンスに裏付けられているか。IT運用において、選択されたRunbookはインシデントの種類に適しているか。正確性は、多くの場合、複数のレベルで評価される必要がある。すなわち、回答の質、推論アーティファクトの質、ツール使用の正確性、そして最終的な成果である。
安全性は、エージェントがデータ漏洩、不正なアクション、プロンプトインジェクション、および損害を与える可能性のあるアクションを回避しているかを測定する。HRエージェントは他の従業員のデータを開示してはならない。購買エージェントは、管理チェックを通過していないベンダーに対して抜け道を作ってはならない。ITエージェントは、ポリシーに反する本番環境の変更を実行してはならない。カスタマーサービスエージェントは、委任された権限を超えたアクションを実行してはならない。安全性テストには、意図的にエージェントを境界の外に誘導しようとするシナリオを含める必要がある。
信頼性は、エージェントが類似した入力に対して比較的一貫した結果を提供するか、ノイズがある場合でも正しく動作するか、ツールが遅い、データが部分的である、入力形式がわずかに変更されるなどの状況で破綻しないかを測定する。購買インテークの分類において、要求者が乱雑な説明を書いた場合でも、エージェントは正しく分類できるか。カスタマーサービスエージェントは、顧客が曖昧な指示を出した場合でも、安全な状態を保てるか。財務エージェントは、エビデンスが不完全な場合に、捏造するのではなく、きちんと停止できるか。信頼性が重要なのは、本番環境ではデモ時のようにクリーンな入力が提供されることは稀だからである。
ビジネス適合性は、エージェントが実際のオペレーティングモデルに適合しているかを評価する。エージェントは技術的に正しく、ポリシー上安全で、十分に一貫性があっても、ビジネスプロセスに適合しなければ、依然として不適切である可能性がある。ビジネス適合性は、エスカレーション率が妥当か、エージェントの出力がレビュー担当者にとって真に役立つか、サイクルタイムが改善されたか、手戻りが減少したか、エージェントがSOP、承認キュー、チームのキャパシティに適合しているかを評価する。返金エージェントは正確かもしれないが、設計上のしきい値が保守的すぎるために80%のケースがスーパーバイザーにエスカレーションされるのであれば、ビジネス適合性は低い。問題はモデルそのものではなく、オペレーティングモデルの設計にある。
自動評価と人間によるレビューの組み合わせ
企業はスピードのために自動評価を必要とするが、そこで止まってはならない。
自動評価は、モデル、プロンプト、ツール、ポリシーの変更後の迅速なリグレッションテスト、エージェントのバージョン比較、ゴールデンセットにおけるパフォーマンス低下の検出、リリース前の初期シグナルの提供に有用である。自動評価は、エージェントが頻繁に変更される場合に特に重要である。これがなければ、すべての変更は遅く一貫性のない手動テストに依存することになる。しかし、自動評価には限界がある。自動評価は、正しいツールが呼び出されたか、エージェントが禁止シナリオを拒否したか、出力に必須フィールドが含まれているか、承認パスが正しくトリガーされたかなど、明確に定義できるパターンに適している。
特に判断が求められるエンタープライズドメインでは、人間によるレビューは依然として必須である。ドメインのレビュー担当者は、エージェントの推奨がビジネス上妥当か、エビデンスは十分か、エスカレーションは適切なポイントで発生しているか、出力が運用チームにとって真に使用可能かを評価するために必要である。財務では、コントローラーはエージェントのドラフトコメンタリーが、単に文法が正しいだけでなく、使用に値するかを評価する必要がある。購買では、バイヤーはニーズの分類と調達パスが妥当かを評価する必要がある。カスタマーオペレーションでは、スーパーバイザーはエージェントの応答がトーン、権利、紛争リスクの観点から適切かを確認する必要がある。
多くのチームが、エージェントの出力品質を評価するために別のモデルを使い始めている。これは、初期トリアージ、エラーのクラスタリング、大まかなスコアリングには有用である。しかし、クリティカルなドメインでは、LLM-as-judgeを唯一の承認基準にしてはならない。理由は単純で、言語スタイルにバイアスがかかり、ビジネスの正確性を評価できない可能性があること、内部ポリシーを理解できない可能性があること、そして運用上の説明責任を負わないことである。より健全なパターンは、迅速なリグレッションには自動評価、レビューのトリアージや優先順位付けの補助にはLLM-as-judge、重要なドメインの承認には人間の専門家によるレビュー、そして本番稼働後の実際のパフォーマンス検証には本番環境モニタリングを組み合わせることである。
ツール呼び出しのテスト:実際のリスクが顕在化する場所
エージェンティックシステムにおいて、ツール呼び出しはエージェントがエンタープライズの現実に触れ始めるポイントである。したがって、ツール使用のテストは、単にAPIが呼び出せることを確認するよりもはるかに厳格でなければならない。
重要なツールはそれぞれ、いくつかの条件下でテストされるべきである。基本フローを検証するためのモック環境、本番環境に影響を与えずにエンドツーエンドの影響を確認するためのサンドボックス取引、アクセスが拒否された場合にエージェントが安全に反応することを確認するための権限エラー、エージェントが適切にリトライ、フォールバック、またはエスカレーションするかを確認するためのタイムアウト、不完全なAPI応答に対するロバスト性をテストするための不正な形式の応答などである。
ERP購買において、ベンダーマスターAPIが失敗した場合、エージェントはベンダーのステータスを推測すべきではない。停止するか、エスカレーションすべきである。CRMカスタマーサービスにおいて、権利データが不完全な場合、エージェントは補償を約束すべきではない。IT運用において、Runbookツールが曖昧な結果を返した場合、エージェントはそれ以上のアクションを控えるべきである。
多くのエージェントは、すべてのツールが正常に動作しているときには良好に見える。問題が発生するのは、1つのAPIが遅い、データが部分的である、応答がスキーマに準拠していない、ポリシーエンジンがアクションを拒否する、といった場合である。このような条件下での期待される動作は明示的であるべきだ。停止する、追加データを要求する、エスカレーションする、限定された回答を返す、などである。あってはならないのは、エージェントが捏造する、ツールをバイパスする、許可されていない別のパスを試みることである。
公式ツールがポリシーによって拒否された場合、エージェントは同じ結果を達成するために別のツールを使用しようとしたり、意図を偽装して通過しようとしたり、ユーザーに管理をバイパスするための手動手順を指示したりしてはならない。エージェントが新しいベンダーを作成できないのであれば、抜け道として「一時的なベンダーカテゴリを使用してください」とユーザーに提案すべきではない。それは親切に聞こえるかもしれないが、ガバナンスの観点からは危険である。
リリースゲート:すべてのエージェントを同じ基準で本番環境に入れるべきではない
評価が行われた後、企業は正式なリリースゲートを必要とする。その目的はイノベーションを遅らせることではなく、本番環境に入るエージェントがそのリスク階層に本当に適していることを確認することである。
低リスクのエージェント、例えば内部ナレッジアシスタントは、返金を実行したり、仕訳を転記したり、ITの是正措置を実行したりできるエージェントと同じプロセスを経る必要はない。実際には、リリースゲートは以下のように区別できる。
低リスクのアシスタントは、基本的な正確性、最低限の安全性、基本的な可観測性、および明確な所有者に焦点を当てる。中リスクのワークフローエージェントは、より厳格なゴールデンシナリオ合格率、ツール呼び出しテスト、正式な人間によるレビュー、ロールバックまたは無効化計画、および本番稼働後の品質モニタリングを追加する。高リスクの実行エージェントは、より広範なシナリオカバレッジ、安全性と敵対的テスト、リスク/セキュリティ/コンプライアンス部門の承認、承認ワークフローの準備状況、完全な可観測性、ロールバックとインシデント対応計画、およびスケール前の限定ロールアウトを必要とする。
本番環境に移行する前に、最低限、企業は以下のことを確認する必要がある。主要シナリオと高リスクケースがテスト済みであること、合格率がそのリスク階層の合意されたしきい値を満たしていること、主要な障害モードが特定され、その緩和策が存在すること、可観測性と監査ログが準備できていること、ビジネスオーナーとテクニカルオーナーが明確であること、ロールバックまたはキルスイッチが利用可能であること、必要に応じて関連するリスク管理機能が承認を与えていること。重要なのは、ゲートが単に「モデルは良いか?」と尋ねるのではなく、「このシステムは実行するのに安全で運用可能か?」と尋ねることである。
企業が買掛金例外トリアージエージェントをリリースしようとしていると想像してみてほしい。健全なリリースチェックリストには、通常ケース、エッジケース、ハイリスクケースを含むゴールデンシナリオセット、エージェントが分類、ルーティング、拒否、エスカレーションのテストに合格していること、ERPとケース管理へのツール呼び出しがサンドボックスでテスト済みであること、権限エラーとタイムアウト時の動作が検証済みであること、支払い関連アクションのポリシーが読み取り/推奨のみであることが確認されていること、可観測性ダッシュボードと基本アラートがアクティブであること、ビジネスオーナー(買掛金運用)とテクニカルオーナー(プラットフォーム)が任命されていること、本番稼働後に修正率やエスカレーション率が急上昇した場合のロールバック計画が用意されていること、などが含まれる。支払い実行エージェントのチェックリストは、これよりもはるかに厳格でなければならない。
結局のところ、エージェントの評価は完璧なスコアを追求することではない。その目的は、企業が、実際のプロセス、リスク、オペレーティングモデルのコンテキストにおいて、エージェントにどの程度の信頼を置くのが適切か、その限界を確実に把握することである。エンタープライズにおいて、これは、賢く見えるが本番環境に耐える準備ができていないデモよりも、はるかに価値がある。