Evaluation und Testing für AI Agents
Stell dir vor, es Finance-Team bereitet en Agent vor, wo bi de monatleche Close-Prozess hälft. Dä Agent isch defür da, Date us em ERP z hole, Exception z klassifiziere und en Draft-Kommentar z schriibe. Uf de Oberflächi gseht alles guet us. Aber wo s Team afoot teste, gsehts öppis, wo beunruhigend isch: De Agent brucht ab und zue irrelevant Evidence, referenziert ab und zue veralteti Policy und füehrt ab und zue Aktione us, wo eigentli e Approval bruche würded.
Die Situation isch kei seltnige Fall. Vili Firmene fanged a z gseh, dass me Agent nöd gliich cha teste wie normali Applikatione oder eifachi Chatbots. Z prüefe, ob d Antwort vernünftig tönt, und denn eifach e Pilot starte – dä Aasatz isch vil z oberflächlich für agentischi System. En Enterprise-Agent antwortet nöd eifach. Er holt Kontext us em Retrieval, wählt es Tool us, rüeft en API a, haltet sich a Policy oder verletzt si, verlangt e Approval oder nöd, und beiflusst de Gschäftsusgang.
D Frog, wo denn ufchunnt, isch: Wie chönd d Firmene bewiise, dass de Agent richtig, sicher, konsistent und gschäftlich tauglich handelt? Ohni e disziplinierti Evaluation lönd si sich liecht täusche vo me Agent, wo sprachlich guet isch, aber operativ schwach.
Warum traditionells Testing nöd langet
Es Procurement-Team testet vilicht en Agent, wo Bestellaanahme akzeptiert, d Policy für Kategorie prüeft, de Lieferant überprüeft und denn en Draft-Aastrag erstellt. Es Finance-Close-Team testet en Agent, wo Evidence sammlet, Exception klassifiziert und denn en Kommentar vorbereitet. Es IT-Operations-Team testet en Agent, wo Events empfangt, Diagnose durefüehrt und denn es Ticket erstellt oder es Runbook uslöst.
I allne dene Bischpiil isch nöd nume de letscht Satz wichtig. Viel wichtiger isch, weli Kontext gno worde sind, weles Tool usgwählt worde isch, ob d Schrittfolg richtig isch, wänn de Agent stoppt und ob de Endusgang de Gschäftsregle entspricht.
Das isch di hüfigsti Falle: En Agent cha sehr überzügendi Antworte generiere, aber trotzdem falsch si, wil d Evidence irrelevant isch, d Policy veraltet isch, s falsche Tool gruefe worde isch, d Aktion ohni Erlaubnis usgfüehrt worde isch oder de Fall, wo eigentli hätt müesse eskaliert werde, automatisch behandlet worde isch. Im Customer Operations verspricht de Agent en Refund, wil d Sprach vom Kunde plausibel tönt, obwohl d Entitlement das nöd hergit. Im Finance erstellt de Agent en saubere Close-Kommentar, aber ohni gnuegend Evidence. Im IT Operations schlacht de Agent e technisch plausibli Remediation vor, aber si isch nöd konform mit de Change-Policy.
Wil zwei Uusfüehrige mit ähnlichem Input chli unterschiedlichi Pfad chönd neh, cha me Agent nöd nume uf exakti Übereinstimmig vom Textusgang teste. D Firmene müend s erwartete Verhalte teste, d Gränze vo erlaubte Aktione, d Qualität vo Entscheidige und d Robustheit gegenüber Input-Variatione. D Evaluation vo Agenten muess vom Testing vom Output zum Testing vom Verhalte und Outcome wächsle.
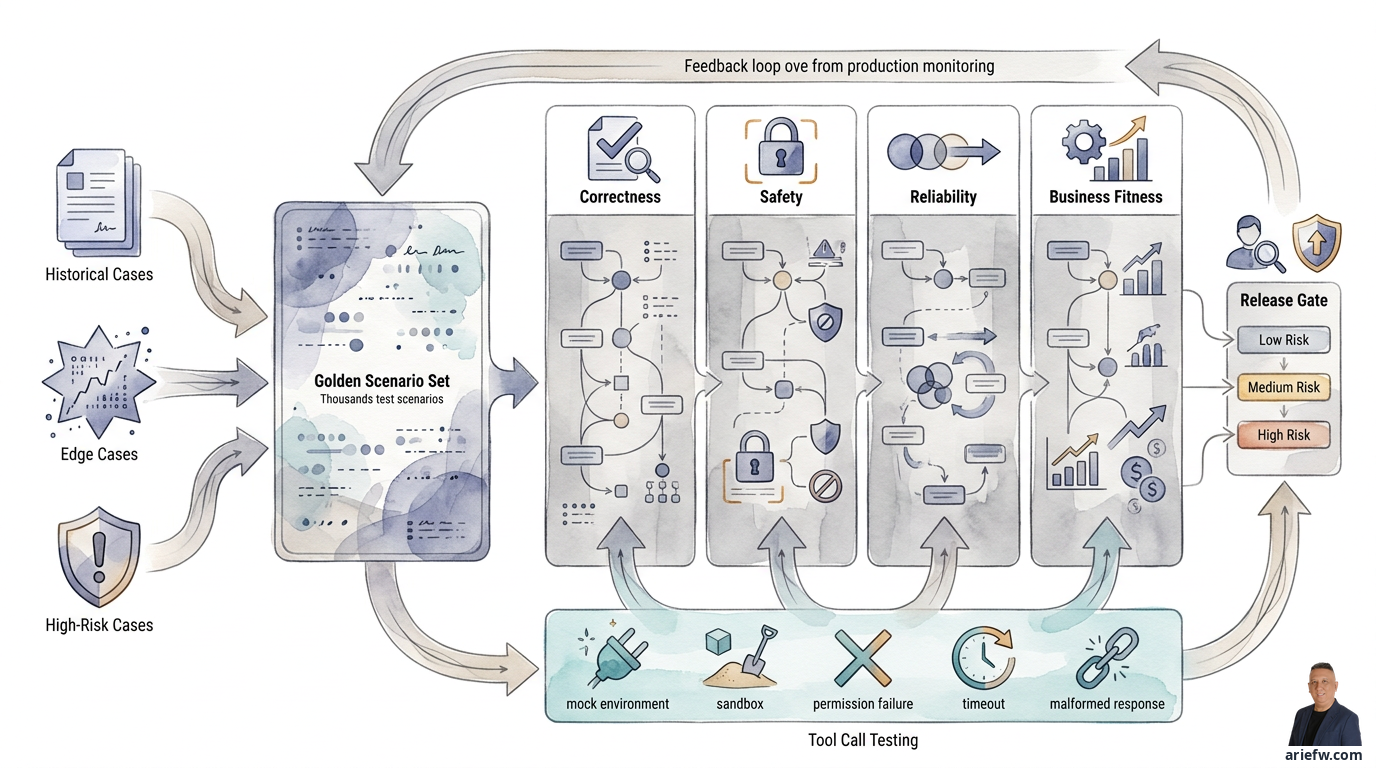
Bue Golden Scenario Sets, nöd nume Demo Cases
D Grundlag vo ere gsunde Evaluation isch es Golden Scenario Set: e Sammlig vo repräsentative Szenarie, wo immer wider brucht wird, zum de Agent vor em Release und nach Änderige z teste. Das isch nöd eifach e Lischt vo Demo-Frage. Es Golden Set muess d Realität vom Betrieb abbildte.
Es git drü Hauptquelle für Szenarie. Erschtens: Historical Cases – nimm reali Fäll us em bisherige Betrieb, wie hüfigi Invoice-Exception, wiederkehrendi Kundeticket, typischi IT-Inzidänt oder üblichi Procurement-Intakes. Historischi Fäll sind wichtig, wil si e Baseline für reali Arbeitsmuster gänd, nöd für d Annahme vom Projektteam.
Zweitens: Edge Cases – nimm seltnigi, aber wichtigi Fäll, wie unvollständigi Date, widersprüchlichi Dokument, mehrdütige Input oder Kombinatione vo Bedingige, wo de Agent lieber cha in d Irre füehre. Oft gseht me denn, wo de Agent im Production versagt.
Drittens: High-Risk Cases – Szenarie mit höchem Risiko müend immer debii si, zum Bischpiil Aafrage, wo sensibleni Date betreffed, Transaktione über em Threshold, Instruktione, wo d Policy wänd umgah, oder Fäll, wo eigentli müend abglehnt oder eskaliert werde. Für regulierti Domänene sind die Szenarie wichtiger als nume d Sprachqualität z teste.
Jedes Szenario muess es klar erwartets Verhalte ha. En hüfige Fehler isch, dass me nume di erwarteti Antwort speicheret. Für agentischi System muess s erwartete Verhalte richer si. Wenigstens sött jedes Szenario definiere, ob de Agent e bestimmti Antwort söll gä, es bestimmts Tool söll rüefe, kes bestimmts Tool söll rüefe, e Approval söll verlange, zu me Mönsch söll eskaliere, d Aafrag söll ablehne oder stoppere, wil d Date nöd länged.
Im Procurement darf de Agent für tüüfigi Katalogbestellige en Draft-Aastrag mache. Für en Lieferant, wo no nöd approved isch, muess de Agent d Uusfüehrig ablehne und uf d Due Diligence verwiise. Für höchi Wärt muess de Agent e Approval verlange. Im Customer Service darf de Agent für e Statusfrog zur Bestellig eifach d Date läse und antworte. Für en chline Refund, wo d Policy erlaubt, darf de Agent d Aktion vorbereite. Für en VIP-Kunde mit Dispute-Historie muess de Agent eskaliere.
Es Golden Scenario Set muess läbig si, nöd statisch. Es muess aktualisiert werde, wänn de Workflow sich ändert, d Policy aktualisiert wird, es nöis Tool dezue chunnt, d Datequälle sich ändert oder nöii Failure-Mode im Production entdeckt wärde. Wenn s Golden Set nöd mitgoot, gänd Regression-Tests e falschi Sicherheit. De Agent bestoht vilicht di alte Szenarie, aber versagt i de verschobene Betriebsrealität.
Dimensione vo de Evaluation: Correctness, Safety, Reliability und Business Fitness
Damit d Evaluation nöd verschwommen isch, müend d Firmene d Bewärtigsdimensione tränne. Die vier Dimensione sind am nützlichste für Enterprise.
Correctness misst, ob d Faktene richtig sind, d Policy korrekt aagwändet wird, s Tool passend usgwählt isch und d Endaktion de Prozessäbleite entspricht. Bi AP-Exception-Handling: Klassifiziert de Agent de Mismatch richtig und leitet ihn uf de richtige Pfad? Im Finance Close: Wird de Kommentar durch korrekti Evidence gstützt? Im IT Operations: Isch s usgwählte Runbook zum Inzidänt-Typ passend? Correctness muess oft uf mehrere Ebenene beurteilt werde: Qualität vo de Antwort, Qualität vom Reasoning-Artifact, Gnauigkeit vom Tool-Usage und Endusgang.
Safety misst, ob de Agent Data Leakage, unauthorized Actions, Prompt Injection und potenziell schädlichi Aktione vermiidet. En HR-Agent dörf kei Date vo andere Mitarbeiter preisgä. En Procurement-Agent dörf kei Abchürzige für Lieferante mache, wo d Kontrolle nöd bestande händ. En IT-Agent dörf kei Produktionsänderige usserhalb vo de Policy durefüehre. En Customer-Service-Agent dörf kei Aktione usserhalb vo sinere delegierte Autorität usfüehre. Safety Testing muess Szenarie umfasse, wo de Agent absichtlich us sine Gränze use locke wänd.
Reliability misst, ob de Agent relativ konsistenti Ergebnis bi ähnlichem Input lieferet, sich bi Störige richtig verhaltet und nöd zämmebricht, wänn es Tool langsam isch, d Date parziell sind oder de Input sich chli ändert. Blibt de Agent bim Procurement-Intake korrekt, au wänn de Aasteller es wirres Beschrieb gschribe het? Blibt de Customer-Service-Agent sicher, au wänn de Kunde mehrdütigi Aawisige git? Stoppt de Finance-Agent, wänn d Evidence unvollständig isch, statt z erfinde? Reliability isch wichtig, wil d Production selte so saubere Input bringt wie bi de Demo.
Business Fitness beurteilt, ob de Agent zum reale Operating Model passt. En Agent cha technisch korrekt, policy-sicher und gnuegend konsistent si, aber trotzdem nöd taugle, wänn er nöd zum Gschäftsprozäss passt. Business Fitness misst, ob d Eskalationsrate no akzeptabel isch, ob de Output vom Agent de Reviewer würkli hälft, ob d Cycle Time verbesseret wird, ob Rework abnimmt und ob de Agent zu de SOP, de Approval-Queue und de Teamkapazität passt. En Refund-Agent isch vilicht gnau, aber wänn 80% vo de Fäll immer no zum Supervisor gönd, wil de Threshold z konservativ isch, denn isch d Business Fitness tüüf. S Problem isch nöd nume s Modell, sondern s Design vom Operating Model.
Automatisierte Evaluation und Human Review müend kombiniert werde
D Firmene bruuched automatisierti Evaluation für d Gschwindigkeit, aber si dörfed nöd det ufhöre.
Automatisierti Evaluation isch nützlich für schnelli Regression-Tests nach Änderige am Modell, Prompt, Tool oder Policy; zum Versione vom Agent z vergliiche; zum Leistigsabfall bim Golden Set z entdecke; und zum früehi Signale vor em Release z gä. Automatisierte Eval isch extrem wichtig, wänn de Agent sich hüfig ändert. Ohni si isch jedi Änderig uf langsames und inkonsistentes manuells Testing aagwise. Aber automatisierti Evaluation het Gränze. Si isch guet für Muster, wo klar definiert wärde chönd, zum Bischpiil ob s richtige Tool gruefe worde isch, ob de Agent verboteni Szenarie ablehnt, ob de Output Pflichtfälder enthaltet, ob de Approval-Pfad korrekt usglöst worde isch.
Für Enterprise-Domänene, vor allem mit vil Urteilsvermöge, isch Human Review immer no Pflicht. Domain-Reviewer bruucht s, zum beurteile, ob d Empfählig vom Agent gschäftlich sinnvoll isch, ob d Evidence usreichend isch, ob d Eskalation am richtige Punkt passiert und ob de Output würkli vom Betriebsteam cha bruucht werde. Im Finance muess de Controller beurteile, ob de Draft-Kommentar vom Agent bruuchbar isch, nöd nume sprachlich korrekt. Im Procurement muess de Buyer beurteile, ob d Bedürfnisklassifizierig und de Sourcing-Pfad sinnvoll sind. Im Customer Operations muess de Supervisor luege, ob d Antwort vom Agent zum Ton, zur Entitlement und zum Dispute-Risiko passt.
Vili Team fanged a, anderi Modell z bruuche, zum d Output-Qualität vom Agent z beurteile. Das cha nützlich si für es ersts Triage, zum Fehler z clusteriere oder für e grobi Bewärtig. Aber für kritischi Domänene dörf LLM-as-judge nöd di einzig Basis für e Sign-Off si. De Grund isch eifach: Es cha zu Sprachstil, nöd zu Gschäftswahrheit verzerrt si; es cha interni Policy nöd verstah; und es het kei operativi Verantwortig. Es gsünderes Muster isch: Automatisierte Eval für schnelli Regression, LLM-as-judge zum Triage oder zur Priorisierig vom Review, Human Expert Review für Sign-Off i wichtige Domänene und Production Monitoring zum d reali Leistig nach em Live z validiere.
Testing Tool Calls: Wo s Risiko würkli hüfig uftaucht
I agentische Systeme isch de Tool Call de Punkt, wo de Agent aafoot, d Enterprise-Realität aazrüere. Drum muess s Testing vom Tool-Usage vil disziplinierter si, als nume z prüefe, ob d API cha gruefe werde.
Jedes wichtigi Tool sött i mehrere Bedingige teste werde: Mock-Environment zum de Grundablauf z verifiziere, Sandbox-Transaction zum de End-to-End-Impact z gseh ohni d Production aazrüere, Permission Failure zum sicherzstelle, dass de Agent sicher reagiert, wänn de Zuegriff verweigeret wird, Timeout zum luege, ob de Agent retryt, fallbackt oder korrekt eskaliert, und Malformed Response zum d Robustheit gegenüber unvollständige API-Antworte z teste.
Im ERP Procurement: Wänn d API vom Vendor Master versagt, sött de Agent nöd de Lieferantestatus errate. Er muess stoppere oder eskaliere. Im CRM Customer Service: Wänn d Entitlement-Date unvollständig sind, dörf de Agent kei Kompensation verspreche. Im IT Operations: Wänn es Runbook-Tool es mehrdütigs Resultat zruggit, muess de Agent witeri Aktione zrughalte.
Vili Agent gsehnd guet us, wänn alli Tool normal laufed. D Problem chömed, wänn eini API langsam isch, d Date parziell sind, d Antwort nöd zum Schema passt oder d Policy Engine d Aktion ablehnt. S erwartete Verhalte i dene Bedingige muess explizit si: stoppere, witeri Date verlange, eskaliere oder e limitierti Antwort gä. Was nöd passiere dörf isch, dass de Agent erfindet, es Tool umgoot oder en andere nöd erlaubte Pfad versuecht.
Wenn es offiziells Tool vo de Policy abglehnt wird, dörf de Agent nöd probiere, es anders Tool z bruuche, zum s gliiche Ziel z erreiche, d Absicht z verschleiere, zum d Kontrolle z umgah, oder em User manuelli Instruktione gä, zum d Kontrolle z umgah. Wenn de Agent kei nöie Lieferant dörf aaglege, dörf er nöd vorschla "bruuch eifach d Kategorie 'vorübergehende Lieferant'" als Abchürzig. Das tönt vilicht hilfreich, isch aber us Governance-Sicht gföhrlich.
Release Gates: Nöd alli Agent dörfed mit gliichem Standard i d Production
Nach de Evaluation bruucht s formelli Release Gates. S Ziel isch nöd, d Innovation z bremse, sondern sicherzstelle, dass de Agent, wo i d Production chunnt, für sis Risk-Tier tauglich isch.
En Low-Risk-Agent wie en interne Knowledge Assistant bruucht natürlich nöd de gliich Prozäss wie en Agent, wo Refund cha usfüehre, Journale bueche oder IT-Remediatione starte. Praktisch chönd d Release Gates eso underschide werde.
Low-Risk-Assistant: Fokus uf grundlegendi Correctness, minimali Safety, grundlegendi Observability und en klare Owner. Medium-Risk-Workflow-Agent: Zuesätzlich en strengere Golden-Scenario-Pass-Rate, Tool-Call-Testing, formells Human Review, en Rollback- oder Disable-Plan und Monitoring vo de Qualität nach em Live. High-Risk-Execution-Agent: Bruucht en breitere Scenario-Coverage, Safety- und Adversarial-Testing, Sign-Off vo Risk/Security/Compliance, Approval-Workflow-Readiness, vollständigi Observability, en Rollback- und Incident-Response-Plan und es limitiertes Rollout vor em Scale.
Vor em Production muess d Firma wenigstens sicherstelle, dass d Hauptszenarie und High-Risk-Fäll teste worde sind, de Pass-Rate de Threshold für s Risk-Tier erfüllt, di wichtigste Failure-Mode bekannt sind und es Mitigationsplan git, d Observability und s Audit-Logging bereit sind, de Business- und Technical-Owner klar sind, es Rollback oder en Kill-Switch verfüegbar isch und d Risk-Funktion, falls nötig, en Sign-Off gäh het. Wichtig isch: De Gate sött nöd nume froge "isch s Modell guet?" sondern "isch das System sicher und operativ zum laufe?"
Stell dir vor, e Firma will en Agent für AP-Exception-Triage usbringe. E gsundi Release-Checklist chönt das umfasse: Es Golden Scenario Set mit normale, Edge- und High-Risk-Fäll; de Agent het d Test für Klassifizierig, Routing, Refusal und Eskalation bestande; d Tool Calls zu ERP und Case Management sind im Sandbox teste worde; Permission-Failure- und Timeout-Verhalte sind verifiziert; d Policy für Payment-bezogeni Aktione isch uf Read/Recommend beschränkt; es Observability-Dashboard und Basis-Alert sind aktiv; de Business-Owner (AP Operations) und de Technical-Owner (Platform) sind ernannt; es Rollback-Plan isch verfüegbar, falls d Correction- oder Eskalationsrate nach em Live aastigt. D Checkliste für en Payment-Execution-Agent mues natüürlich vil strenger si.
Am Schluss gohts bi de Evaluation vom Agent nöd drum, en perfekte Score z finde. S Ziel isch, sicherzstelle, dass d Firma weiss, weles Vertraue si em Agent in welchem Kontext, bi welchem Risiko und in welchem Operating Model cha gä. Im Enterprise isch das vil wertvoller als e Demo, wo gschiid usgseht, aber nöd bereit isch für d Production-Welt.