AIエージェントのためのデータプロダクト
エージェンティックAIの導入を始める多くのチームは、データが利用可能であるため準備ができていると感じています。データレイク、データウェアハウス、BIダッシュボード、あるいは大規模なドキュメントインデックスが存在します。従来のレポート作成や分析には、これで十分です。しかし、エージェントを使い始めると、問題が発生します。エージェントはデータを読み取り、誤った意思決定を行います。モデルが悪いからではなく、使用するデータが、エージェントが安全かつ一貫して理解できる形でパッケージ化されていないからです。
これは現場でよく感じられる問題です。ある財務チームは、エージェントに決算処理を支援させたいと考えましたが、試算表データには暫定値と確定値が混在していました。調達チームは、エージェントに購買依頼を処理させたいと考えましたが、「承認済みベンダー」の定義が調達システムとERPで異なっていました。カスタマーオペレーションチームは、エージェントに問い合わせ対応をさせたいと考えましたが、「アクティブ顧客」のステータスに統一された定義がありませんでした。データは存在するものの、エージェントが正しく利用できないのです。
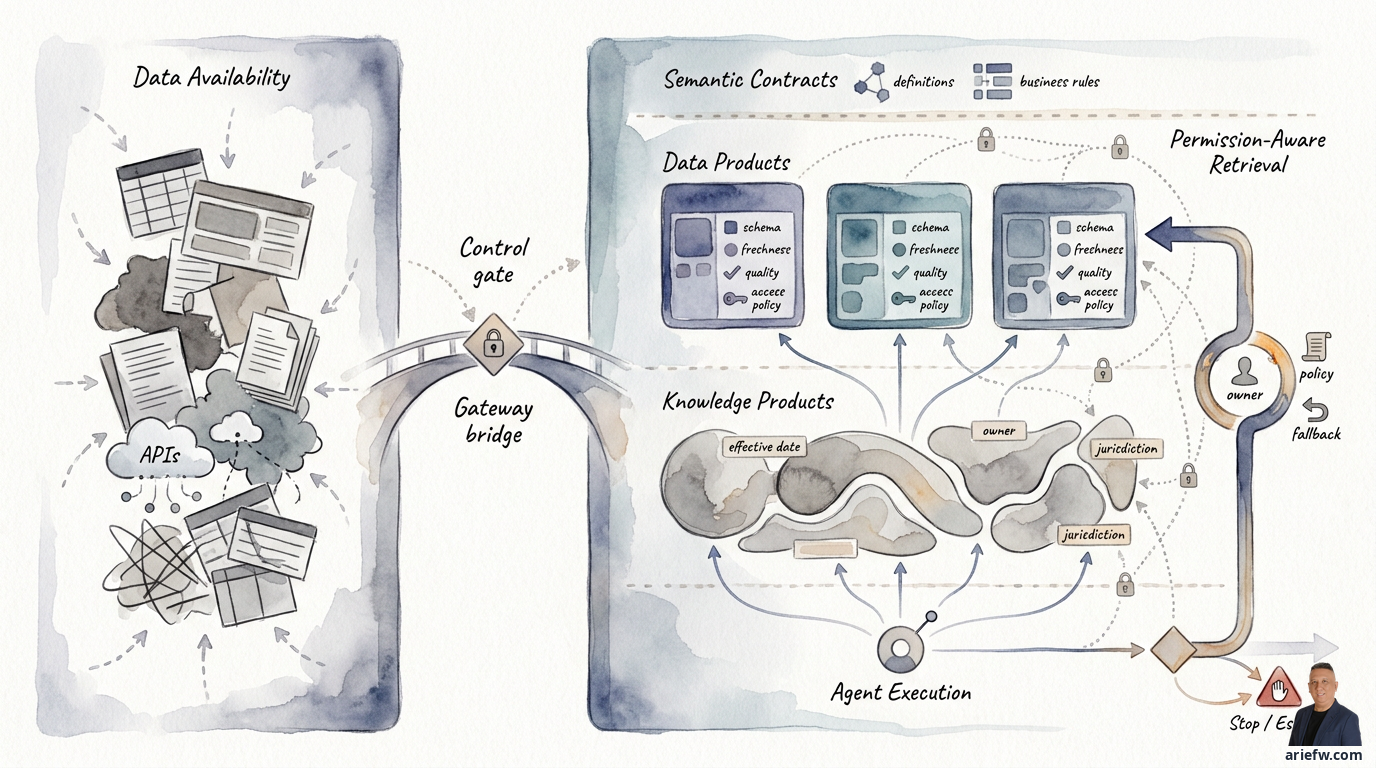
エージェントが必要とするのは、生のデータすべてではありません。エージェントが必要とするのは、意味が明確で、所有者がおり、測定可能な品質を持ち、実行時に評価可能なアクセスルールを持ち、アクションを実行するために十分に安定したデータプロダクトおよびナレッジプロダクトです。ここに、単なるデータの利用可能性(Data Availability)から、エージェントによるユーザビリティ(Agent Usability)へのパラダイムシフトがあります。
利用可能なデータから、エージェントが利用できるデータへ
これまで、モダンデータプログラムはデータの収集、保存、アクセス解放に焦点を当ててきました。このアプローチはレポート作成や分析には理にかなっています。しかし、エージェントは人間のアナリストのように機能しません。アナリストはあいまいさを許容し、複数のダッシュボードを開き、自分で文脈を解釈できます。エージェントにはそれができません。エージェントには明示的な入力が必要です。つまり、このデータは何を表すのか、どの程度新しいのか、いつ使用してよいのか、どのような目的で使用するのか、定義が変更された場合の責任者は誰か、といった情報です。
エージェント対応データプロダクト(Agent-Ready Data Product)の概念は、このニーズから生まれました。データセットがデータプロダクトとなるのは、データ自体だけでなく、それを利用可能にする運用上の契約(コントラクト)を伴う場合です。エージェントにとって、この契約はより厳格である必要があります。最低限、エージェント向けデータプロダクトには、明確で安定したスキーマ、文書化されたセマンティクス、ビジネスおよびテクニカルオーナー、フレッシュネス期待値、品質しきい値、基本的な系列(リネージ)、アクセスポリシー、そして関連する場合は許可されるアクションや使用目的が必要です。これらの要素がなければ、エージェントは意味のないフィールドの集まりを目にしているに過ぎません。
データの利用可能性とエージェントによるユーザビリティの違いは明確にされるべきです。請求書テーブルがウェアハウスに存在するかもしれません。顧客APIが稼働しているかもしれません。SOPフォルダがRAG用にインデックス化されているかもしれません。技術的には、データは利用可能です。しかし、エージェントはそれを安全かつ正確に利用できるでしょうか? 必ずしもそうとは限りません。財務決算では、試算表、調整仕訳、過去のコメントデータが利用可能です。しかし、エージェントがどの数値が暫定値でどれが確定値か、どの法人が処理中か、決算ウィンドウがいつ正式に閉じるかを知らなければ、その利用可能性は自動的にユーザビリティにはなりません。
エージェンティックワークフローにおいては、データプロダクトは通常、以下の3つの形式のいずれかでパッケージ化されるとより有用です。第一に、customer_entitlement_summary や approved_vendor_profile のような、スコープが限定されたドメインAPIまたはサービスです。この形式は、エージェントが構造化された運用データを頻繁に必要とする場合に適しています。第二に、延滞の定義が標準化されたエイジング請求書ビューのような、キュレーションされた分析ビューです。この形式は、エージェントがメトリクスやビジネスステータスに基づいて推論する必要がある場合に適しています。第三に、出荷遅延イベントや支払い失敗イベントのような、イベントベースのプロダクトです。この形式は、イベント駆動型で動作するエージェントに適しています。
データプロダクトがよりキュレーションされるほど、ユーザビリティとガバナンスは向上しますが、探索の柔軟性は低下します。本番環境のエージェントにとっては、このトレードオフは通常、受け入れる価値があります。エージェントは、人間のアナリストほど探索の自由を必要としません。エージェントが必要とするのは、明確さと信頼性です。
セマンティックコントラクト:形式だけでなく、意味を統一する
多くの組織は、すでにスキーマレジストリやAPIドキュメントを持っています。これらは重要ですが、十分ではありません。エージェントは、revenue、margin、customer_status という名前のフィールドが存在することを知るだけでなく、そのビジネス上の意味を知る必要があります。
セマンティックコントラクトは、各フィールドやオブジェクトのビジネス上の意味、その根拠となるビジネスルール、許可される使用目的、前提条件と制限事項、および特定の意思決定にデータを使用すべきでない条件を説明するレイヤーです。セマンティックコントラクトは、通常はドメインエキスパートの頭の中にあり、技術スキーマにはない質問に答えます。
セマンティックコントラクトがなければ、エージェントは一見単純な用語を誤って解釈しやすくなります。Revenue は、ブッキング revenue、請求 revenue、認識 revenue、またはネット revenue を意味する可能性があります。Margin は、粗利、貢献利益、または特定の配賦後の利益を意味する可能性があります。Active Customer は、特定の期間内に取引があった、有効な契約がある、または正式にチャーンしていない、のいずれかを意味する可能性があります。Overdue Invoice は、カレンダーの期日を過ぎている、猶予期間を過ぎている、または異議申し立てステータスがアクティブでない場合にのみ該当する、のいずれかを意味する可能性があります。経験豊富な人間のアナリストは、通常、組織の文脈からこれらの違いを理解します。エージェントはそうではありません。セマンティックコントラクトが明示的でなければ、エージェントはそのギャップを推論で埋めようとし、その推論はもっともらしく見えても、運用上は誤っていることがよくあります。
エンタープライズにおいて、セマンティックコントラクトは理想的には、BIや分析、運用アプリケーション、AIエージェント、ビジネスユーザーの間で言語を統一するセマンティックレイヤーの一部となるべきです。これは、データに関する多くのコンフリクトが、実際には技術的な品質問題ではなく、定義の問題であるため、重要です。共有サービス財務部門では、コントローラーシップチーム、FP&Aチーム、決算支援エージェントが、セマンティックレイヤーが標準化されていなければ、「重要な差異(material variance)」という用語を異なる意味で使用する可能性があります。サプライチェーンでは、「利用可能在庫(available inventory)」は、手持ち在庫、受注可能在庫、または安全在庫後の在庫を意味する可能性があります。補充エージェントが正しい定義を知らなければ、その推奨は誤ったものになります。
セマンティックコントラクトは、特に以下のデータプロダクトに対して最も厳格である必要があります。すなわち、部門横断的な意思決定に使用されるもの、取引や承認に影響を与えるもの、エージェントがアクションを実行するために使用するもの、または人事、財務、法務、顧客データなどの規制対象ドメインにあるものです。探索的なユースケースやリスクの低い内部アシスタントの場合、セマンティックコントラクトはより軽量で構いません。しかし、エージェントが実際のワークフローに影響を与え始めたら、セマンティックコントラクトはオプションのドキュメントではなく、コントロールの一部として扱われるべきです。
パーミッションアウェア検索:アクセスはコンテキストに従うべき
エージェントは、データがインデックス、レイク、ベクターストアに存在するという理由だけで、データを取得すべきではありません。アクセスは、元のユーザーまたはプリンシパル、ロールと委任された権限、実行中のワークフロー、使用目的、データの機密性に従うべきです。これがパーミッションアウェア検索(Permission-Aware Retrieval)の核心です。
多くのRAGや内部検索の実装は、単純なパターンから始まります。すべてのドキュメントをインデックス化し、意味的に最も関連性の高いものを取得するというものです。エンタープライズでは、これは危険です。最も関連性の高いドキュメントが、最もアクセスを許可されるべきドキュメントであるとは限りません。人事オペレーションでは、オンボーディングエージェントが休暇や福利厚生に関するポリシーを検索するかもしれません。検索が意味的な類似性のみに基づいている場合、エージェントは報酬に関するドキュメントや、本来見えるべきでない他の従業員のケースを引き出す可能性があります。法務では、契約アシスタントエージェントが内容は非常に関連性の高い契約を発見するかもしれませんが、それが別の法域、事業部門、または特権が制限された案件に属している場合があります。カスタマーサービスでは、エージェントがパターン的に類似した他の顧客の履歴を引き出す可能性がありますが、ユーザーのコンテキストは特定の1つのアカウントのみを表示する権限しかありません。
よくある誤りは、データのインデックス作成時のみにアクセス制御を適用することです。しかし、アクセス権は、エージェントを呼び出すユーザー、使用されるチャネル、ワークフローの段階、または使用目的によって変化する可能性があります。そのため、パーミッションアウェア検索は実行時に評価される必要があります。実務的には、これはデータプロダクトまたはナレッジプロダクトが、機密性分類、所有者、事業部門、法域、許可されたオーディエンス、使用ルールなどのメタデータを保持する必要があることを意味します。そして、ランタイムエージェントは、現在のコンテキストがそのデータを取得するための条件を満たしているかどうかを評価する必要があります。
エージェンティックシステムでは、ロールベースのアクセス(RBAC)だけでは粗すぎることがよくあります。同じロールを持つ2人の人物が、同じ目的でデータを使用できるとは限りません。マネージャーは、業績レビューのためにチームのデータを見ることができますが、報酬調査のために自動的に見ることができるわけではありません。財務エージェントは、例外処理のために請求書の詳細を読むことはできますが、適切な権限なしに法人横断的なベンダーサマリーを作成することはできません。パーミッションアウェア検索は、理想的には、ロールやアイデンティティに加えて、目的(パーパス)も考慮する必要があります。
パーミッションアウェア検索は複雑さを増します。メタデータはよりリッチである必要があり、IAMおよびポリシーエンジンとの統合はより緊密である必要があり、レイテンシーが増加する可能性があり、インデックスの設計はより複雑になります。しかし、人事、財務、法務、顧客データ、規制対象業務などのドメインでは、このトレードオフは追加の選択肢ではありません。これは、エージェントが新たなデータ漏洩経路やコントロール違反の経路とならないための最低条件です。
品質とフレッシュネス:エージェントはデータが使用に適さないタイミングを知るべき
エージェンティックAIにおける最も現実的なリスクの一つは、モデルが幻覚を見ることではなく、エージェントが古くなった、不完全な、同期が取れていない、または過渡的なステータスにあるデータに基づいて行動することです。エンタープライズワークフローでは、これは非常に有害となり得ます。
調達では、エージェントがデューデリジェンスシステムからまだ同期されていない承認ステータスに基づいてベンダー推奨を行います。財務では、決算支援エージェントが暫定値に基づいてコメントを作成しますが、確定値はすでに変更されています。カスタマーオペレーションでは、エージェントがまだ更新されていない注文ステータスに基づいて返金を約束します。ITオペレーションでは、インシデントトリアージエージェントがもはや正確ではないCMDBを使用し、誤ったシステムへの是正措置を指示します。これらすべてのケースにおいて、問題はモデルではありません。問題は、データプロダクトが十分な品質とフレッシュネスのシグナルを伝えていないことです。
エージェント向けデータプロダクトには、少なくとも4つのメカニズムがあるべきです。第一に、品質チェック:必須フィールドの入力、スキーマ準拠、最小限の参照整合性、極端な値の分布の逸脱がないことなどの基本的な検証。第二に、フレッシュネスインジケーター:エージェントは、データが最後に更新された時期、期待される更新サイクル、およびデータがまだ使用可能な期間内にあるかどうかを知る必要があります。第三に、異常検知:異常な急増やパターンがある場合、エージェントはデータをすぐに有効と見なすべきではありません。第四に、フォールバック動作:品質やフレッシュネスがしきい値を満たさない場合、エージェントは何をすべきか(停止する、追加データを要求する、代替ソースを使用する、人間にエスカレーションする)を知っている必要があります。
しばしば見落とされる能力は、エージェントが「データが不十分である」と言えることです。多くのチームは、エージェントが常に回答するようにすることに集中しすぎています。しかし、エンタープライズでは、正しい振る舞いはしばしば停止することです。買掛金(AP)例外処理エージェントは、入庫がまだ行われていない場合、不一致を分類すべきではありません。人事エージェントは、資格データがまだ確定していない場合、福利厚生ステータスに関する質問に答えるべきではありません。サプライチェーンエージェントは、出荷フィードがまだ更新されていない場合、ルート変更を推奨すべきではありません。ガバナンスの観点からは、いつ停止すべきかを知っているエージェントは、常に自信満々に見えるエージェントよりも価値があります。
品質とフレッシュネスのしきい値が厳しくなるほど、エージェントの意思決定は安全になりますが、手動処理やエスカレーションに回るケースも増えます。逆に、しきい値が緩すぎると、自動化率は向上しますが、誤った意思決定のリスクも高まります。しきい値はユースケースごとに決定されるべきです。内部ナレッジアシスタントは、より緩やかなフレッシュネスを許容できます。返金、支払い、人事アクション、または本番環境の是正措置には、はるかに厳格なしきい値が必要です。
非構造化データのためのナレッジプロダクト
エージェントのコンテキストのすべてがテーブルやAPIから得られるわけではありません。多くのエンタープライズワークフローでは、最も重要な情報源は、SOP、ポリシードキュメント、契約書、メールアーカイブ、ナレッジ記事、ラン�ブック、内部メモなどです。問題は、多くの組織がこれらすべてをインデックス化するための単なるドキュメントとして扱っていることです。エージェンティックシステムにとっては、それでは不十分です。これらのドキュメントは、ナレッジプロダクト(Knowledge Product)として扱われる必要があります。
ナレッジプロダクトとは、エージェントが安全かつ確実に使用できるようにキュレーションされた非構造化コンテンツの集合であり、メタデータ、所有権、使用ルールを備えています。データプロダクトが「数値やステータスは何か」という質問に答えるのに対し、ナレッジプロダクトは「どのようなルール、手順、またはコンテキストが適用されるか」という質問に答えるのに役立ちます。
エージェントにとって、ドキュメントのメタデータは、ドキュメントの内容そのものと同じくらい重要であることがよくあります。特に重要なメタデータには、発効日、所有者、事業部門、法域、ドキュメントタイプ、分類または機密性、置き換えステータス、承認ステータス、信頼できる情報源(Source of Truth)が含まれます。これらのメタデータがなければ、検索はトピック的には正しいが、コンテキスト的には間違ったドキュメントを取得する可能性があります。法務や調達では、内容的に関連する契約テンプレートでも、処理中の国や事業部門には適用されない場合があります。人事では、古い福利厚生ポリシーが新しいポリシーと非常に似ている場合がありますが、すでに置き換えられています。ITオペレーションでは、古いラン�ブックが技術的にはまだ関連性があるかもしれませんが、現在の本番アーキテクチャには適合しなくなっています。
かなり一般的なアンチパターンは、すべてのメールをインデックス化し、良い結果を期待することです。組織はメールアーカイブ、共有ドライブ、古いドキュメントをインデックス化し、エージェントが最適な回答を見つけてくれることを期待します。結果はしばしば悪いものです。検索結果はノイズだらけで、古いドキュメントが表示され、コンテキストが互いに矛盾し、エージェントは公式ポリシーと非公式な議論を区別するのに苦労します。エンタープライズでは、ナレッジプロダクトはキュレーションされるべきです。すべてのドキュメントがエージェントのコンテキストとして適しているわけではありません。時には、アーカイブの大部分を検索レイヤーに含めないことが最善の判断であることもあります。
財務決算では、優れたナレッジプロダクトには、適用される会計ポリシー、決算カレンダー、例外処理のSOP、公式のコメントテンプレート、検証済みの内部FAQが含まれます。カスタマーオペレーションでは、ナレッジプロダクトには、返金ポリシー、権利ルール、エスカレーションプレイブック、承認済みの応答ガイダンス、現在有効な製品問題に関する速報が含まれます。ITオペレーションでは、ナレッジプロダクトには、公式のラン�ブック、キュレーションされたポストモーテム、現在有効なサービス依存関係メモ、関連する変更ポリシーが含まれます。
アーキテクチャとガバナンスへの影響
データとナレッジがエージェントのためのプロダクトとして扱われるようになると、いくつかの直接的な影響が生じます。
第一に、所有権が明確でなければなりません。各データプロダクトおよびナレッジプロダクトには、定義と許可される使用目的に関するビジネスオーナー、デリバリー、スキーマ、品質に関するテクニカルオーナー、そして機密性の高いドメインには必要に応じてリスクまたはコンプライアンスオーナーが必要です。オーナーがいなければ、エージェントは利用可能なデータを使用しますが、定義が変更されたり品質が低下したりした場合に責任を負う者はいません。
第二に、カタログはコントロールプレーンの一部となるべきです。企業は、データプロダクトの存在を記録するだけでなく、セマンティックコントラクト、フレッシュネス期待値、品質ステータス、アクセスポリシー、リスク階層も記録するカタログを必要とします。これにより、エージェントプラットフォームはデータプロダクトを、アドホックな接続ではなく、ガバナンス可能な依存関係として扱うことができます。
第三に、エージェントの評価ではデータプロダクトもテストする必要があります。エージェントが失敗した場合、常にモデルを責めるべきではありません。多くの場合、根本原因は、セマンティックのあいまいさ、メタデータの不足、フレッシュネスの低下、または実行時にパーミッションが適用されていないことにあります。エージェントの評価には、以下の質問を含めるべきです。使用されたデータプロダクトは本当に適切だったか、セマンティックコントラクトは十分に明確だったか、品質低下時にフォールバックは機能したか、検索はポリシーに準拠していたか。
次のステップ
この記事を読んだ後、チームに持ち帰るべきいくつかの質問があります。データが適切にパッケージ化されていないために最も頻繁に問題が発生するワークフローはどれか? 最初に実行するエージェントにとって最も重要なデータプロダクトは何か? そのデータプロダクトのオーナーは誰になるのか? メトリクスやビジネスステータスに関するセマンティックコントラクトは文書化されているか? エージェントがアクセスすべきでないデータを取得しないようにするにはどうすればよいか? そして最も重要なこととして、データが十分に信頼できない場合に、エージェントはいつ停止すべきかを知っているか?
エージェンティックエンタープライズを構築することは、モデル、オーケストレーション、ツール呼び出しだけの問題ではありません。それはまた、エンタープライズデータを、API、ワークフロー、セキュリティコントロールをパッケージ化するのと同じ規律で、エージェントが使用できるプロダクトにパッケージ化することでもあります。これを理解している企業は、印象的なデモから、真に信頼できる運用へとより迅速に移行できるでしょう。