Data Products untuk AI Agents
Banyak tim yang mulai mencoba agentic AI merasa sudah siap karena data tersedia. Ada data lake, warehouse, dashboard BI, atau indeks dokumen yang besar. Untuk laporan dan analisis tradisional, itu cukup. Tapi ketika agent mulai dipakai, masalah muncul. Agent membaca data, lalu mengambil keputusan yang salah. Bukan karena modelnya buruk, tetapi karena data yang dipakai tidak dikemas dengan cara yang bisa dipahami agent secara aman dan konsisten.
Ini masalah yang sering terasa di lapangan. Sebuah tim finance ingin agent membantu proses close, tetapi data trial balance tercampur antara angka preliminary dan final. Tim procurement ingin agent memproses permintaan pembelian, tetapi definisi "approved vendor" berbeda antara sistem sourcing dan ERP. Tim customer operations ingin agent menjawab keluhan, tetapi status "active customer" tidak punya definisi yang seragam. Data tersedia, tetapi agent tidak bisa memakainya dengan benar.
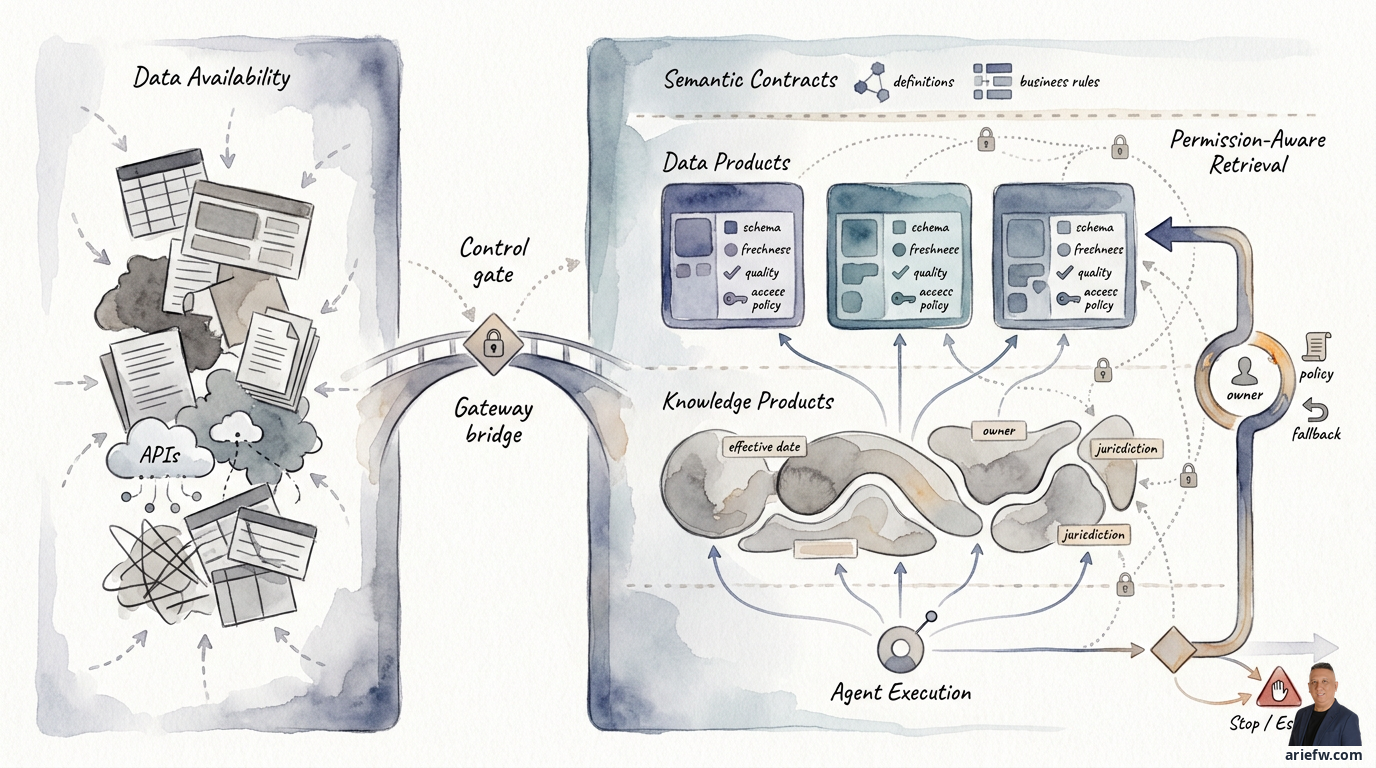
Yang dibutuhkan agent bukanlah semua data mentah. Agent membutuhkan data products dan knowledge products yang jelas maknanya, punya owner, punya kualitas terukur, punya aturan akses yang bisa dievaluasi saat runtime, dan cukup stabil untuk dipakai mengambil tindakan. Inilah pergeseran dari sekadar data availability ke agent usability.
Dari Data yang Tersedia ke Data yang Bisa Dipakai Agent
Selama ini, program data modern fokus pada mengumpulkan, menyimpan, dan membuka akses ke data. Pendekatan ini masuk akal untuk reporting dan analytics. Tapi agent tidak bekerja seperti analis manusia. Analis bisa menoleransi ambiguitas, membuka beberapa dashboard, lalu menafsirkan konteks sendiri. Agent tidak bisa. Ia perlu input yang eksplisit: data ini mewakili apa, seberapa baru, kapan boleh dipakai, untuk tujuan apa, dan siapa yang bertanggung jawab jika definisinya berubah.
Konsep agent-ready data product lahir dari kebutuhan ini. Sebuah dataset menjadi data product ketika ia tidak hanya berisi data, tetapi juga kontrak operasional yang membuatnya layak dipakai. Untuk agent, kontrak ini harus lebih ketat. Minimal, data product untuk agent perlu memiliki schema yang jelas dan stabil, semantics yang terdokumentasi, owner bisnis dan teknis, freshness expectation, quality threshold, lineage dasar, access policy, dan jika relevan, allowed actions atau allowed usage. Tanpa elemen-elemen ini, agent hanya melihat sekumpulan field tanpa makna.
Perbedaan antara data availability dan agent usability perlu ditegaskan. Sebuah tabel invoice mungkin tersedia di warehouse. Sebuah API customer mungkin aktif. Sebuah folder SOP mungkin sudah diindeks untuk RAG. Secara teknis, data tersedia. Tapi apakah agent bisa memakainya dengan aman dan benar? Belum tentu. Di finance close, data trial balance, jurnal adjustment, dan commentary historis tersedia. Namun jika agent tidak tahu mana angka preliminary dan mana final, mana entitas legal yang sedang diproses, atau kapan close window dianggap resmi, maka availability itu tidak otomatis menjadi usability.
Untuk workflow agentic, data product biasanya lebih berguna jika dikemas dalam salah satu dari tiga bentuk. Pertama, domain API atau service yang sudah dibatasi, seperti customer_entitlement_summary atau approved_vendor_profile. Bentuk ini cocok ketika agent perlu data operasional yang terstruktur dan sering dipakai. Kedua, curated analytical view, seperti view aging invoice dengan definisi overdue yang sudah dibakukan. Bentuk ini cocok ketika agent perlu reasoning atas metrik atau status bisnis. Ketiga, event-backed product, seperti shipment delay event atau failed payment event. Bentuk ini cocok untuk agent yang bekerja secara event-driven.
Semakin terkurasi data product, semakin tinggi usability dan governance, tetapi fleksibilitas eksplorasi menurun. Untuk agent production, trade-off ini biasanya layak diambil. Agent tidak membutuhkan kebebasan eksplorasi sebesar analis manusia. Agent membutuhkan kejelasan dan keandalan.
Semantic Contracts: Menyamakan Arti, Bukan Hanya Format
Banyak organisasi sudah punya schema registry atau dokumentasi API. Itu penting, tetapi belum cukup. Agent tidak hanya perlu tahu bahwa ada field bernama revenue, margin, atau customer_status. Agent perlu tahu apa arti bisnisnya.
Semantic contract adalah lapisan yang menjelaskan arti setiap field atau objek, business rule yang melandasinya, allowed usage, asumsi dan keterbatasan, serta kondisi ketika data tidak boleh dipakai untuk keputusan tertentu. Semantic contract menjawab pertanyaan yang biasanya hidup di kepala domain expert, bukan di schema teknis.
Tanpa semantic contract, agent mudah salah menafsirkan istilah yang tampak sederhana. Revenue bisa berarti booked revenue, billed revenue, recognized revenue, atau net revenue. Margin bisa berarti gross margin, contribution margin, atau margin setelah alokasi tertentu. Active customer bisa berarti pernah transaksi dalam periode tertentu, masih punya kontrak aktif, atau belum churn secara formal. Overdue invoice bisa berarti melewati due date kalender, melewati grace period, atau hanya berlaku jika dispute status tidak aktif. Analis manusia berpengalaman biasanya tahu perbedaan ini dari konteks organisasi. Agent tidak. Jika semantic contract tidak eksplisit, agent akan mengisi kekosongan itu dengan inferensi yang sering terlihat masuk akal, tetapi salah secara operasional.
Dalam enterprise, semantic contract idealnya menjadi bagian dari semantic layer yang menyamakan bahasa antara BI dan analytics, aplikasi operasional, AI agents, dan pengguna bisnis. Ini penting karena banyak konflik data sebenarnya bukan masalah kualitas teknis, melainkan masalah definisi. Di shared services finance, tim controllership, tim FP&A, dan agent close assistant bisa memakai istilah "material variance" dengan arti berbeda jika semantic layer tidak dibakukan. Di supply chain, "available inventory" bisa berarti on-hand, available-to-promise, atau stock setelah safety reserve. Jika agent replenishment tidak tahu definisi yang benar, rekomendasinya akan salah.
Semantic contract perlu paling ketat pada data product yang dipakai untuk keputusan lintas fungsi, menyentuh transaksi atau approval, dipakai agent untuk mengeksekusi tindakan, atau berada di domain regulated seperti HR, finance, legal, dan customer data. Untuk use case eksploratif atau assistant internal berisiko rendah, semantic contract bisa lebih ringan. Tetapi begitu agent mulai memengaruhi workflow nyata, kontrak semantik harus diperlakukan sebagai bagian dari kontrol, bukan dokumentasi opsional.
Permission-Aware Retrieval: Akses Harus Mengikuti Konteks
Agent tidak boleh mengambil data hanya karena data ada di index, lake, atau vector store. Akses harus mengikuti siapa user atau principal asal, role dan delegated authority, workflow yang sedang berjalan, tujuan penggunaan, dan sensitivitas data. Inilah inti dari permission-aware retrieval.
Banyak implementasi RAG atau search internal dimulai dengan pola sederhana: indeks semua dokumen, lalu ambil yang paling relevan secara semantik. Untuk enterprise, ini berbahaya. Dokumen yang paling relevan belum tentu dokumen yang paling boleh diakses. Di HR operations, agent onboarding mungkin mencari policy cuti atau benefit. Jika retrieval hanya berbasis kemiripan semantik, agent bisa menarik dokumen kompensasi atau kasus karyawan lain yang seharusnya tidak terlihat. Di legal, agent contract assistant bisa menemukan kontrak yang sangat relevan secara isi, tetapi berada di yurisdiksi lain, business unit lain, atau matter yang dibatasi privilege. Di customer service, agent bisa menarik histori pelanggan lain yang mirip secara pola, padahal konteks user hanya berhak melihat satu account tertentu.
Kesalahan umum adalah menerapkan kontrol akses hanya saat data diindeks. Padahal hak akses bisa berubah tergantung user yang memanggil agent, channel yang dipakai, tahap workflow, atau tujuan penggunaan. Karena itu, permission-aware retrieval harus dievaluasi saat runtime. Secara praktis, ini berarti data product atau knowledge product perlu membawa metadata seperti klasifikasi sensitivitas, owner, business unit, jurisdiction, audience yang diizinkan, dan aturan penggunaan. Lalu runtime agent harus mengevaluasi apakah konteks saat ini memenuhi syarat untuk mengambil data tersebut.
Untuk agentic systems, role-based access saja sering terlalu kasar. Dua orang dengan role sama belum tentu boleh memakai data untuk tujuan yang sama. Seorang manager boleh melihat data timnya untuk review kinerja, tetapi tidak otomatis untuk investigasi kompensasi. Agent finance boleh membaca detail invoice untuk exception handling, tetapi tidak untuk menyusun ringkasan vendor lintas entitas tanpa mandat yang tepat. Permission-aware retrieval idealnya mempertimbangkan purpose selain role dan identity.
Permission-aware retrieval menambah kompleksitas. Metadata harus lebih kaya, integrasi IAM dan policy engine harus lebih rapat, latency bisa bertambah, dan desain indeks menjadi lebih rumit. Tetapi untuk domain seperti HR, finance, legal, customer data, dan regulated operations, trade-off ini bukan pilihan tambahan. Ini syarat minimum agar agent tidak menjadi jalur baru kebocoran data atau pelanggaran kontrol.
Quality dan Freshness: Agent Harus Tahu Kapan Data Tidak Layak Dipakai
Salah satu risiko paling praktis dalam agentic AI bukanlah model berhalusinasi, melainkan agent bertindak berdasarkan data yang basi, tidak lengkap, tidak sinkron, atau sedang berada di status transisi. Untuk workflow enterprise, ini bisa sangat merusak.
Di procurement, agent membuat rekomendasi vendor berdasarkan status approved yang belum tersinkron dari sistem due diligence. Di finance, agent close assistant menyusun commentary dari angka preliminary, padahal angka final sudah berubah. Di customer operations, agent menjanjikan refund berdasarkan status order yang belum diperbarui. Di IT operations, agent incident triage memakai CMDB yang sudah tidak akurat, lalu mengarahkan remediasi ke sistem yang salah. Dalam semua kasus ini, masalahnya bukan model. Masalahnya adalah data product tidak membawa sinyal kualitas dan freshness yang cukup.
Data product untuk agent sebaiknya memiliki setidaknya empat mekanisme. Pertama, quality checks: validasi dasar seperti field wajib terisi, schema sesuai, referential integrity minimum, dan distribusi nilai tidak menyimpang ekstrem. Kedua, freshness indicator: agent perlu tahu kapan data terakhir diperbarui, expected refresh cycle, dan apakah data masih dalam jendela layak pakai. Ketiga, anomaly detection: jika ada lonjakan atau pola yang tidak biasa, agent sebaiknya tidak langsung menganggap data valid. Keempat, fallback behavior: jika kualitas atau freshness tidak memenuhi threshold, agent harus tahu apa yang dilakukan—berhenti, meminta data tambahan, memakai sumber alternatif, atau mengeskalasi ke manusia.
Kemampuan yang sering diabaikan adalah agent harus bisa mengatakan "data tidak cukup". Banyak tim terlalu fokus membuat agent selalu menjawab. Padahal dalam enterprise, perilaku yang benar sering kali adalah berhenti. Agent AP exception tidak boleh mengklasifikasikan mismatch jika goods receipt belum masuk. Agent HR tidak boleh menjawab status benefit jika data eligibility belum final. Agent supply chain tidak boleh merekomendasikan rerouting jika feed shipment belum diperbarui. Secara governance, agent yang tahu kapan berhenti lebih berharga daripada agent yang selalu terlihat percaya diri.
Semakin ketat threshold kualitas dan freshness, semakin aman keputusan agent, tetapi semakin banyak kasus yang akan jatuh ke jalur manual atau eskalasi. Sebaliknya, threshold yang terlalu longgar meningkatkan automation rate, tetapi juga meningkatkan risiko keputusan salah. Threshold harus ditentukan per use case. Knowledge assistant internal bisa menoleransi freshness yang lebih longgar. Refund, payment, HR action, atau production remediation membutuhkan threshold yang jauh lebih ketat.
Knowledge Product untuk Unstructured Data
Tidak semua konteks agent berasal dari tabel dan API. Dalam banyak workflow enterprise, sumber paling penting justru datang dari SOP, policy document, kontrak, email archive, knowledge article, runbook, dan memo internal. Masalahnya, banyak organisasi memperlakukan semua ini sebagai dokumen untuk diindeks. Untuk agentic systems, itu tidak cukup. Dokumen-dokumen ini perlu diperlakukan sebagai knowledge products.
Knowledge product adalah kumpulan konten tidak terstruktur yang dikurasi agar bisa dipakai agent secara aman dan andal, lengkap dengan metadata, ownership, dan aturan penggunaan. Jika data product menjawab pertanyaan "apa angka atau statusnya", knowledge product membantu menjawab "aturan, prosedur, atau konteks apa yang berlaku".
Untuk agent, metadata pada dokumen sering sama pentingnya dengan isi dokumen itu sendiri. Metadata yang sangat penting meliputi effective date, owner, business unit, jurisdiction, document type, classification atau sensitivity, superseded status, approval status, dan source of truth. Tanpa metadata ini, retrieval bisa mengambil dokumen yang benar secara topik tetapi salah secara konteks. Di legal dan procurement, template kontrak yang relevan secara isi belum tentu berlaku untuk negara atau unit bisnis yang sedang diproses. Di HR, policy benefit lama bisa sangat mirip dengan policy baru, tetapi sudah superseded. Di IT operations, runbook lama mungkin masih relevan secara teknis, tetapi tidak lagi sesuai arsitektur produksi saat ini.
Anti-pattern yang cukup umum adalah mengindeks semua email dan berharap hasilnya baik. Organisasi mengindeks email archive, shared drive, dan dokumen lama, lalu berharap agent akan menemukan jawaban terbaik. Hasilnya sering buruk: retrieval penuh noise, dokumen usang ikut muncul, konteks saling bertentangan, dan agent sulit membedakan policy resmi dari diskusi informal. Untuk enterprise, knowledge product harus dikurasi. Tidak semua dokumen layak menjadi konteks agent. Kadang keputusan terbaik justru adalah tidak memasukkan sebagian besar arsip ke retrieval layer.
Di finance close, knowledge product yang baik bisa berisi accounting policy yang berlaku, close calendar, SOP exception handling, template commentary resmi, dan FAQ internal yang sudah divalidasi. Di customer operations, knowledge product bisa berisi refund policy, entitlement rules, escalation playbook, approved response guidance, dan product issue bulletin yang masih aktif. Di IT operations, knowledge product bisa berisi runbook resmi, postmortem yang sudah dikurasi, service dependency notes yang masih berlaku, dan change policy yang relevan.
Implikasi Arsitektur dan Governance
Begitu data dan knowledge diperlakukan sebagai produk untuk agent, beberapa implikasi langsung muncul.
Pertama, ownership harus jelas. Setiap data product dan knowledge product perlu business owner untuk definisi dan allowed usage, technical owner untuk delivery, schema, dan kualitas, dan jika perlu risk atau compliance owner untuk domain sensitif. Tanpa owner, agent akan memakai data yang tersedia, tetapi tidak ada yang benar-benar bertanggung jawab saat definisi berubah atau kualitas turun.
Kedua, katalog harus menjadi bagian dari control plane. Perusahaan perlu katalog yang tidak hanya mencatat keberadaan data product, tetapi juga semantic contract, freshness expectation, quality status, access policy, dan risk tier. Dengan begitu, agent platform dapat memperlakukan data product sebagai dependency yang governable, bukan koneksi ad hoc.
Ketiga, evaluasi agent harus menguji data product juga. Jika agent gagal, jangan selalu menyalahkan model. Sering kali akar masalahnya ada pada semantic ambiguity, metadata yang kurang, freshness yang buruk, atau permission yang tidak ikut saat runtime. Evaluation untuk agent sebaiknya mencakup pertanyaan: apakah data product yang dipakai memang tepat, apakah semantic contract cukup jelas, apakah fallback berjalan saat kualitas turun, dan apakah retrieval mematuhi policy.
Langkah Selanjutnya
Setelah membaca ini, ada beberapa pertanyaan yang bisa dibawa ke tim. Workflow mana yang paling sering mengalami masalah karena data tidak dikemas dengan baik? Data product apa yang paling kritis untuk agent pertama yang akan dijalankan? Siapa yang akan menjadi owner untuk data product tersebut? Apakah semantic contract untuk metric dan status bisnis sudah didokumentasikan? Bagaimana cara memastikan agent tidak mengambil data yang tidak boleh diakses? Dan yang paling penting, apakah agent tahu kapan harus berhenti karena data tidak cukup andal?
Membangun agentic enterprise bukan hanya soal model, orchestration, atau tool calling. Ia juga soal mengemas data enterprise menjadi produk yang bisa dipakai agent dengan disiplin yang sama seperti mengemas API, workflow, dan kontrol keamanan. Perusahaan yang memahami ini akan lebih cepat bergerak dari demo yang impresif ke operasi yang benar-benar dapat dipercaya.