Agentic AIのためのデータ基盤
皆さんの財務チームが、決算業務を支援するエージェントを構築したと想像してみてください。そのエージェントはERPに接続され、仕訳を読み取り、さらには調整案のドラフトを作成し始めます。デモでは、すべてが順調に進みます。しかし、実際の決算期間で使用されると、エージェントは請求書のステータスを誤って読み取り、誤った勘定科目を推奨し、実際には解決済みの例外をエスカレーションし始めます。財務チームは、すべてを最初から再確認することになります。
何が間違っていたのでしょうか?モデルではありません。エージェントがシステムに接続する方法でもありません。問題は、エージェント自体の燃料となるデータにありました。
多くの企業は、モデル、エージェントフレームワーク、プラットフォームに過度に焦点を当てています。しかし、エンタープライズの文脈では、モデルはますます購入や交換が容易になっています。模倣がはるかに難しいのは、企業のコンテキスト、すなわち、内部データ定義、プロセス構造、運用ポリシー、意思決定の履歴、ビジネスエンティティ間の関係です。これらはすべて、構造化データと非構造化データの両方に存在します。
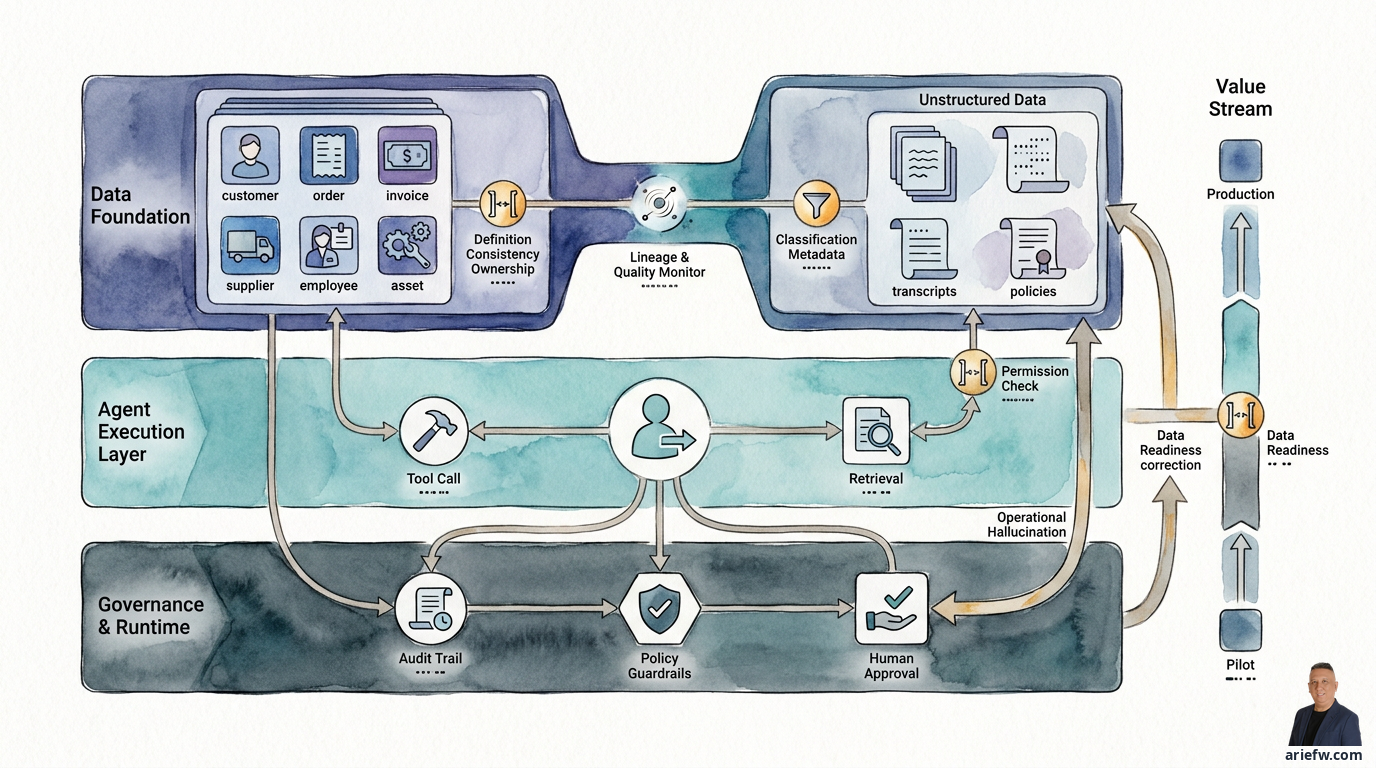
エージェンティックアーキテクチャが新しい実行エンジンであるならば、データ基盤は燃料であると同時にナビゲーションシステムでもあります。強固なデータ基盤がなければ、エージェントはもっともらしく聞こえても、運用上は誤った行動をとる可能性があります。一見もっともらしい回答を返すかもしれませんが、ベンダーを誤って選択したり、注文ステータスを誤って読み取ったり、ポリシーを誤って解釈したりするのです。
デモ用のエージェントと、実際の日々の運用に耐えうるエージェントとの違いは、通常、会話の品質ではありません。その違いは、データの readiness(準備状態)にあります。
モデルよりもデータが重要な理由
AIの議論において、モデルは最も目に見えるため、しばしば注目の的となります。人々は推論能力、レイテンシ、出力品質を比較します。これらはすべて重要です。しかし、エンタープライズにとって、モデルは単なる構成要素の一つです。真のビジネス価値は、モデルが正しい企業コンテキスト上で動作するときに現れます。
モデルは購入できるが、企業コンテキストは購入できない
企業は、フロンティアモデルへのアクセスを購入したり、オープンソースモデルを利用したり、時間の経過とともにモデルベンダーを変更したりすることができます。しかし、御社の「アクティブ顧客」の定義、特定の部門に適用される請求書不一致の許容ルール、契約、注文、出荷、およびディスピュート間の関係、財務決算時に頻繁に発生する例外の履歴を、すぐに提供してくれるベンダーは存在しません。
このコンテキストを理解していないエージェントは、最も重要なポイント、すなわち運用実行において失敗します。
調達の例を見てみましょう。エージェントは購買依頼を読み取り、処理経路を提案できるかもしれません。しかし、サプライヤマスタデータが一貫しておらず、購買カテゴリが標準化されておらず、ローカルポリシーが様々な文書に分散している場合、エージェントはリクエストを誤った経路に導く可能性があります。言語的には賢く見えますが、運用上は手戻りを生み出します。
カスタマーオペレーションの別の例です。エージェントは顧客の履歴をうまく要約できます。しかし、エンタイトルメントのステータス、SLA、契約上の例外が利用不可または同期されていない場合、エージェントは契約に沿わないサービス約束をしてしまう可能性があります。これは単なる技術的なエラーではありません。商業上および評判上の問題になり得ます。
正確なデータなしのエージェントは、運用上の幻覚(operational hallucination)を引き起こす
幻覚(ハルシネーション)という用語は、モデルが事実をでっち上げることを説明するためによく使われます。エンタープライズにおいて、より危険な形態は「運用上の幻覚(operational hallucination)」です。つまり、出力はもっともらしく聞こえるが、ビジネスの現実に対して誤っている状態です。
例えば、財務エージェントが、ERPのステータスが既に変更されているにもかかわらず、請求書は未払いであると結論付けるケース。あるいは、HRエージェントが、更新されていない古い文書に基づいて休暇ポリシーを回答するケース。IT運用エージェントが、CMDBが不正確なために、関連性のないRunbookを推奨するケース。サプライチェーンエージェントが、実際の在庫制約を理解せずにルート変更を提案するケース。
問題は回答の正確性だけではありません。問題は、エージェントが行動、優先順位、意思決定に影響を与え始めることです。
データ readiness がパイロットと本番を分ける
多くのエージェンティックパイロットは、データが手動でクリーニングされ、スコープが絞られ、文書が一つずつ選択され、プロジェクトチームが集中的に結果を監視するため、成功しているように見えます。本番に入ると、状況は変わります。データは多数のシステムから流入し、ビジネス定義は統一されておらず、文書は乱雑で、パーミッションは複雑であり、例外ははるかに多くなります。
この時点で、企業はデータ readiness が単なる支援業務ではなく、スケーリングの前提条件であることに気づきます。
したがって、「どのモデルを使うのか?」という質問よりも重要なのは、どのビジネスデータが信頼できる唯一の情報源(source of truth)なのか、その所有者は誰か、その定義はどの程度一貫しているか、その品質はどのように監視されているか、そしてエージェントは制御を侵害せずにどのようにアクセスするか、ということです。
構造化データ:アクションエージェントの基盤
エージェントがエンタープライズシステム内で行動するのであれば、ビジネス状態の公式な表現である構造化データへのアクセスが必要です。構造化データには通常、顧客、注文、請求書、製品、従業員、サプライヤ、資産、契約、チケット、財務取引などのコアエンティティが含まれます。これらは運用上のアクションに最も近いデータです。エージェントがステータスを確認したり、条件を検証したり、アクションを準備したりするとき、ほとんどの場合、構造化データに依存します。
単なるテーブルではなく、一貫性のあるビジネスオブジェクト
よくある誤りは、企業がすでにERPやCRMを持っているため、構造化データは十分に利用可能であると考えることです。現実には、システムが存在することは、データがエージェントにとって準備できていることを自動的に意味するわけではありません。
エージェンティックAIにとって有用であるためには、構造化データは少なくとも6つの特性を備えている必要があります。
一貫性のあるビジネス定義。 「アクティブ顧客」とは何を意味するのか?注文はいつ「フルフィルメント済み」とみなされるのか?「承認済みサプライヤ」と「有効化済みサプライヤ」の違いは何か?これらの定義が機能間や国間で異なる場合、エージェントは一貫した意思決定を行うのに苦労します。記録から報告(Record-to-Report)において、例えば、機密勘定、重要性、または調整ステータスの定義は明確でなければなりません。そうでなければ、決算オーケストレーションエージェントは誤った項目を優先してしまいます。
明確なオーナーシップ。 各データドメインには、技術管理者だけでなく、ビジネスオーナーが存在しなければなりません。顧客マスタ、ベンダーマスタ、従業員データ、製品階層の品質について誰が責任を持つのかが明確でなければなりません。オーナーシップがなければ、データの問題は「システムの問題」と見なされ続けますが、その影響はエージェントの運用に直接及びます。
トレーサブルな系列(Lineage)。 エージェントは、出自が明確なデータ上で動作する必要があります。ダッシュボードのフィールドが、適切な系列なしに多層的な変換から派生したものである場合、エージェントが正しいビジネス状態を読んでいるのか、それとも遅延した派生データを読んでいるのかを確認するのは困難です。これは、単なるインサイトではなく、運用上の意思決定に触れるユースケースにとって特に重要です。
監視された品質。 データ品質は仮定できません。企業は、完全性、一意性、一貫性、適時性、妥当性を監視する必要があります。買掛金の例では、ベンダーマスタが重複していたり、税IDが不完全だったりすると、請求書解決エージェントはケースを誤って関連付けることが多くなります。HRオペレーションの例では、組織構造が最新でない場合、オンボーディングエージェントが承認や通知を誤った方向に導く可能性があります。
十分に強力なセマンティクス。 エージェントのための構造化データは、「保存されている」だけでは不十分です。システム間で理解可能な意味を持たなければなりません。ここで、エンタープライズデータモデル、カノニカルモデル、マスタデータ管理が重要になります。より成熟した組織では、エージェントの意思決定がソースシステムに依存して変わらないように、一貫性のあるエンタープライズデータモデルを重視し始めています。
安全なアクセスインターフェース。 エージェントはコアテーブルを無制限に読み取るべきではありません。構造化データへのアクセスは、パーミッション、監査証跡、安定したスキーマ、ポリシー適用を維持するインターフェースを通じて行われるべきです。言い換えれば、エージェントのための構造化データは、技術的なショートカットとしてではなく、エンタープライズ機能としてアクセスされるべきです。
エンタープライズの例:財務、調達、シェアードサービス
財務決算では、決算を支援するエージェントは、調整ステータス、未処理仕訳、経年例外、決算カレンダー、勘定科目マッピングなどのデータを必要とします。これらのデータが一貫性を持ち、明確な系列を持っていれば、エージェントは例外を優先順位付けし、コメンタリーを準備し、フォローアップをオーケストレーションできます。そうでなければ、エージェントはノイズを増やすだけです。
調達では、購買依頼から発注(intake-to-PO)までのエージェントは、サプライヤマスタ、購買カテゴリ、有効契約、予算ステータス、購買履歴を必要とします。サプライヤマスタが混乱していたり、カテゴリが標準化されていなかったりすると、エージェントは誤った購買経路を選択することが多くなります。この領域では、マスタデータの品質がモデルの高度さよりも重要であることがよくあります。
シェアードサービスでは、構造化データは機能間で分散していることがよくあります。ケース管理エージェントは、チケットデータ、SLA、トランザクションステータス、インタラクション履歴を組み合わせる必要があるかもしれません。システム間で識別子が同期していない場合、エージェントはケースの全体像を構築するのに苦労します。
構造化データだけでは不十分な場合
構造化データはアクションにとって非常に重要です。しかし、エンタープライズのコンテキストの多くは、トランザクションテーブルには存在しません。ポリシー、契約、電子メール、通話記録、SOP、ケースノートが、意思決定の決定要因となることがよくあります。ここで非構造化データの出番となります。
非構造化データ:真のコンテキストが潜む場所
多くの組織は、エージェントの構築を始めたときに初めて非構造化データの価値に気づきます。これまで、文書やコミュニケーションは受動的なアーカイブとして扱われることがよくありました。エージェンティックAIにおいて、これらの情報源は能動的なコンテキスト層へと変わります。
非構造化データには通常、ポリシー文書、SOP、契約書、電子メール、通話記録、チャット履歴、画像や文書のスキャン、議事録、ナレッジ記事、ケース処理記録などが含まれます。多くのエンタープライズワークフローにおいて、意思決定の背後にある理由はまさにここにあります。
カスタマーオペレーションでは、チケットのステータスはCRMにあるかもしれませんが、顧客の感情、これまでに行われた約束、根本的な問題のコンテキストは、多くの場合、トランスクリプトや会話履歴にあります。調達では、サプライヤマスタはシステムにありますが、商業条件や契約上の例外は文書にあります。HRでは、従業員データはHRISにありますが、ローカルポリシー、FAQ、プログラムの例外は、ポータル、PDF、電子メールに存在することがよくあります。IT運用では、アラートは可観測性プラットフォームにありますが、Runbook、ポストモーテム、過去の回避策は、Wiki、チケットノート、チャットチャネルに分散していることがよくあります。
エージェンティックAIは、非構造化データから新たな価値を引き出します。なぜなら、エージェントは単に「文書を検索する」だけでなく、複数の情報源を同時に読み取り、文書の内容を比較し、過去のコンテキストをトランザクションの状態に結び付け、そのコンテキストに基づいて行動したりエスカレーションしたりできるからです。
非構造化データには、単なる文書アップロードではなく、パイプラインが必要
多くの初期実装は、「文書をベクターストアにアップロードする」で止まっています。エンタープライズにとって、これはあまりにも浅はかです。非構造化データは、規律あるパイプラインを通じて管理される必要があります。
インジェスト。 文書は、明確な情報源(公式リポジトリ、メールアーカイブ、コンタクトセンタープラットフォーム、契約管理システム、ナレッジベース、キュレーションされたファイル共有など)から取り込まれる必要があります。インジェストが制御されていないと、エージェントは権威のない情報源からコンテキストを引き出してしまいます。
分類。 すべての文書が同じ重みを持つわけではありません。企業は、公式ポリシー、ドラフト、期限切れ文書、有効契約、非公式コミュニケーション、参考資料を区別する必要があります。分類がなければ、エージェントは古い文書をあたかもまだ有効であるかのように引用する可能性があります。
チャンキングとエンリッチメント。 長い文書は、関連性を持って取得可能な単位に分割する必要があります。しかし、チャンキングは盲目的に行うべきではありません。文書の所有者、有効日、バージョン、地域、機能、機密レベル、アクティブ/非アクティブステータスなどのメタデータは、埋め込み自体よりも重要であることがよくあります。
埋め込みと検索。 埋め込みはセマンティック検索を支援しますが、エンタープライズ検索は単なる類似性検索以上のものでなければなりません。メタデータ、パーミッション、ワークフローのコンテキストを考慮する必要があります。インドネシアのHRポリシーは、言語が類似しているという理由だけで、他国の従業員のケースに表示されるべきではありません。
保持とライフサイクル。 非構造化データにも有効期限があります。古いメール、機密性の高いトランスクリプト、または終了した契約は、ルールなしにアクティブなコンテキストであり続けるべきではありません。エージェントがもはや関連性のないはずの記憶に基づいて意思決定を構築しないように、保持ポリシーを適用する必要があります。
非構造化データに関する重要なトレードオフ
すべての文書をエージェンティックシステムに取り込みたいという誘惑があります。これは賢明ではありません。キュレーションなしに多くの文書を取り込むほど、ノイズが増え、検索エラーのリスクが高まり、パーミッションの維持が難しくなり、処理コストが高くなります。
したがって、より健全な戦略は、権威があり価値の高いコーパスから始めることです。例えば、シェアードサービス向けの公式SOP、調達向けの有効契約、サービスデスク向けの検証済みナレッジ記事、キュレーションされたHRポリシーなどです。会社がこれまでに作成したすべてのファイルではありません。
エージェントのためのデータガバナンス:ポリシーからランタイムへ
この段階で、多くの企業はすでにデータガバナンスを持っていると感じています。データ分類、アクセスポリシー、データオーナー、保持ポリシーがあります。問題は、従来のガバナンスは、文書、委員会、手動による制御で止まっていることが多いことです。エージェンティックAIにとって、ガバナンスはランタイムに変換されなければなりません。
重要な質問は、「誰がこのデータにアクセスできるか?」だけではありません。誰がエージェントを通じて、どのような目的で、どのワークフローで、どの程度の自律性でこのデータにアクセスでき、そのアクセスがアクションを生み出すのか、それとも単なるインサイトなのか、ということです。
パーミッションは検索時とツールコール時に適用されなければならない
これは非常に重要なポイントです。エージェントが文書や構造化データからコンテキストを取得する場合、パーミッションは回答が出力された後ではなく、検索時にチェックされなければなりません。
HRエージェントは、ユーザーに権限がない場合、報酬データを引き出すべきではありません。調達エージェントは、一般の要求者に対して戦略的契約を開示すべきではありません。財務エージェントは、ユーザーのスコープ外の特定のエンティティのデータを表示すべきではありません。カスタマーサービスエージェントは、適切な本人確認なしに機密性の高い履歴にアクセスすべきではありません。
同じことがツールコールにも当てはまります。注文ステータスを読み取る権限は、注文を変更する権限とは異なります。ベンダーを表示する権限は、ベンダーマスタを変更する権限とは異なります。
エージェントのためのガバナンスには目的のコンテキストが必要
エンタープライズにおいて、データアクセスは単にアイデンティティの問題ではなく、目的の問題でもあります。エージェントがAPの例外を解決するために請求書データを読み取ることは正当かもしれませんが、同じデータを使用して、関係のない関係者と共有するためのサマリーを作成することは正当ではないかもしれません。
したがって、エージェンティックガバナンスは、エージェントのアイデンティティ、代理されるユーザーまたはプロセスのアイデンティティ、ビジネス目的、および実行中のワークフローを結び付ける必要があります。これは従来のアプリケーションアクセスモデルよりも複雑ですが、より現実的でもあります。
監査証跡は意思決定のコンテキストを説明できなければならない
エージェントにとって、優れた監査証跡は「アクセスが発生した」と記録するだけでは不十分です。どのデータが、どの情報源から、どのパーミッションに基づいて、どのワークフローで取得され、そのデータがどのように意思決定やアクションに影響を与えたかを説明できなければなりません。これは、リスク、コンプライアンス、そして運用改善にとって重要です。エージェントが誤った推奨を行った場合、企業は問題がデータ品質、誤った検索、メタデータの不足、または適用されていないポリシーのいずれにあるのかを追跡できなければなりません。
データガバナンスがエージェントに対応できていない兆候
よく見られる兆候としては、データオーナーが自分のデータがエージェントによって使用されていることを知らない、公式文書とドラフトが明確なバージョンなしに混在している、ナレッジレイヤーのパーミッションがソースシステムよりも緩い、有効日やポリシーの地域に関するメタデータがない、エージェントが汎用サービスアカウントのためにデータにアクセスできる、インシデント発生時に特定のコーパスやデータソースを簡単に無効化する方法がない、などがあります。
これらの兆候がある場合、エージェンティックAIをスケーリングすると、価値よりもリスクが急速に拡大します。
スケーリング前のデータ基盤強化
データ基盤の重要性を理解したところで、今すぐ取るべきいくつかの決定があります。第一に、最初のエージェンティックユースケースのための優先データドメインを決定します。「すべての企業データ」から始めてはいけません。顧客、請求書、サプライヤ、従業員、チケットなど、優先バリューストリームに最も近いドメインを選択します。第二に、構造化データの信頼できる情報源と、非構造化データの権威あるコーパスを決定します。エージェントがあいまいなデータランドスケープから自分で選択できるようにしてはいけません。第三に、データとワークフローにわたるオーナーシップを確立します。ビジネスデータの所有者、ナレッジコーパスの所有者、パーミッションと品質監視の責任者が明確でなければなりません。第四に、ドキュメントガバナンスだけでなく、ランタイムガバナンスを構築します。パーミッション、メタデータ、保持、ポリシーは、検索時とツールコール時に適用されなければなりません。第五に、非構造化データのキュレーション戦略を選択します。価値が高く公式なコーパスから始めます。カバレッジだけを目的としてすべての文書を取り込んではいけません。
企業の準備状況を評価するには、優先ユースケースの主要な構造化データドメインが特定されているか、重要なエンティティのビジネス定義が機能間で十分に一貫しているか、顧客、サプライヤ、従業員、注文、請求書、またはその他の関連ドメインに明確なオーナーがいるか、主要データの品質が少なくとも完全性、一貫性、適時性について監視されているか、エージェントがパーミッションと監査証跡を維持するインターフェースを通じて構造化データにアクセスしているか、エージェントが使用する非構造化データコーパスがキュレーションされ、ドラフトや期限切れ文書と区別されているか、バージョン、有効日、地域、機密分類などの重要なメタデータが利用可能か、検索がソースシステムと一貫性のあるパーミッションを適用しているか、文書、トランスクリプト、インタラクション履歴の保持ポリシーが考慮されているか、エージェントが推奨やアクションを生成する際に使用したデータを追跡するための十分なログ記録があるか、を確認します。
このトピックがスケーリングの準備ができていないという危険信号に注意してください。AIチームが「データは後でクリーンアップする」と言う場合、コアマスタデータが機能間でまだ議論されている場合、エージェントが公式ステータスが不明確な文書から回答を取得している場合、ポリシーにバージョンや有効日のメタデータがない場合、エージェントのサービスアカウントがドメイン間のデータに対して広範なアクセス権を持っている場合、ナレッジベースからの検索がユーザーのパーミッションを尊重していない場合、重要なフィールドに十分なデータ系列がない場合、ビジネスがエージェントが使用するコンテキストの品質に責任を持つオーナーをまだ指名していない場合、スケーリングはリスクを拡大します。
エージェンティックAIを拡大する前に、正直に自問してください。私たちの会社は、ビジネスの仕組みを真に理解するエージェントを構築しているのか、それとも、まだ信頼する準備ができていないデータの上に、単にスマートなインターフェースを構築しているだけなのか?もし答えが後者であれば、次の優先事項は新しいエージェントを追加することではありません。既存のエージェントが信頼され、監査され、スケーリングされるに値するものとなるよう、データ基盤を強化することです。