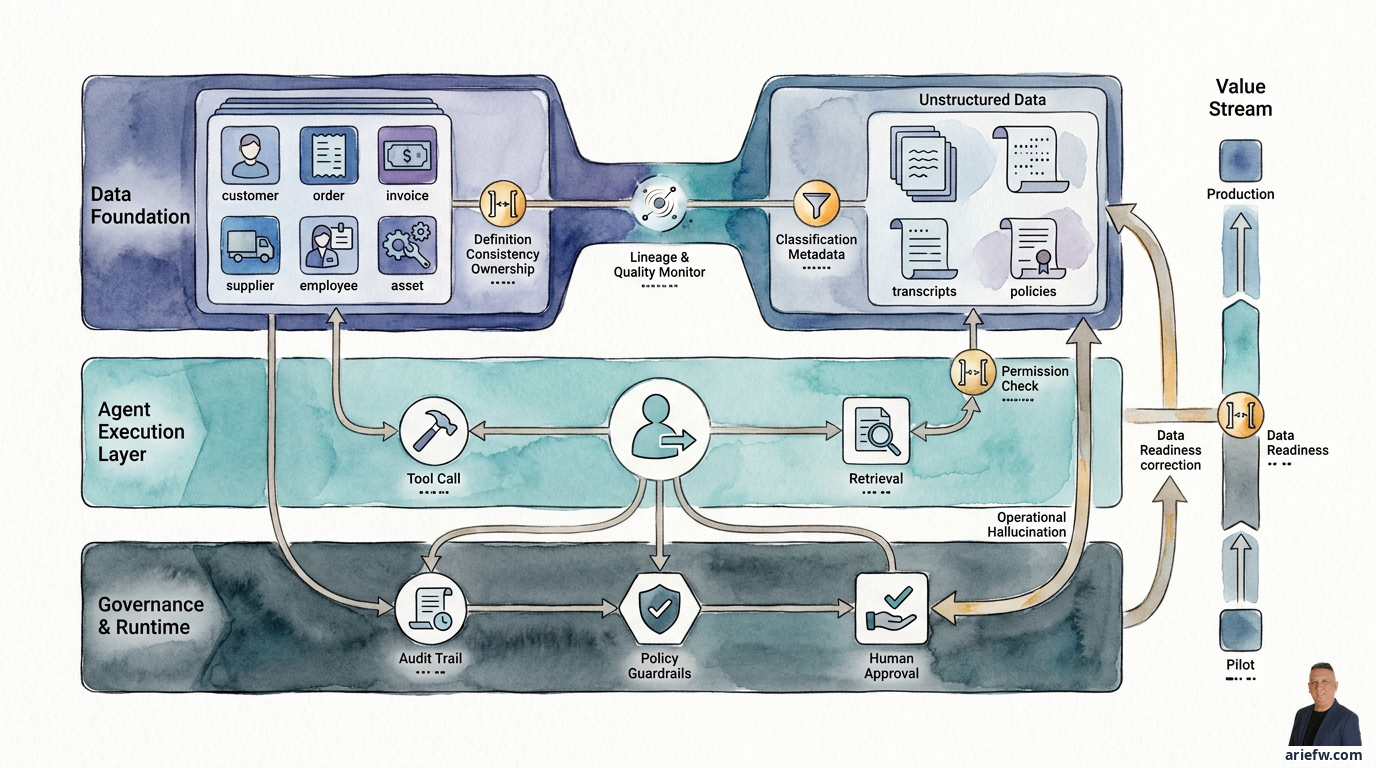
Data Foundation untuk Agentic AI
Bayangkan tim finance Anda sudah membangun agent yang bisa membantu proses tutup buku. Agent itu terhubung ke ERP, bisa membaca jurnal, dan bahkan mulai menyusun draft rekonsiliasi. Di demo, semuanya berjalan mulus. Tapi begitu dipakai untuk periode tutup yang sesungguhnya, agent mulai salah membaca status invoice, merekomendasikan akun yang salah, dan mengeskalasi exception yang sebenarnya sudah selesai. Tim finance pun kembali memeriksa semuanya dari awal.
Apa yang salah? Bukan modelnya. Bukan juga cara agent terhubung ke sistem. Masalahnya ada pada data yang menjadi bahan bakar agent itu sendiri.
Banyak perusahaan terlalu fokus pada model, framework agent, atau platform. Padahal dalam konteks enterprise, model semakin mudah dibeli atau diganti. Yang jauh lebih sulit ditiru adalah konteks perusahaan: definisi data internal, struktur proses, kebijakan operasional, histori keputusan, dan hubungan antar-entitas bisnis. Semua itu hidup di data, baik yang terstruktur maupun tidak.
Jika arsitektur agentic adalah mesin eksekusi baru, maka data foundation adalah bahan bakar sekaligus sistem navigasinya. Tanpa fondasi data yang kuat, agent bisa terdengar meyakinkan tetapi salah secara operasional. Ia bisa memberi jawaban yang tampak masuk akal, namun salah memilih vendor, salah membaca status order, atau salah menafsirkan policy.
Perbedaan antara demo agent dan agent yang layak dipakai di operasi harian biasanya bukan pada kualitas percakapan. Perbedaannya ada pada data readiness.
Mengapa Data Lebih Penting dari Model
Dalam diskusi AI, model sering menjadi pusat perhatian karena paling terlihat. Orang membandingkan kemampuan reasoning, latency, atau kualitas output. Semua itu penting. Tetapi untuk enterprise, model hanyalah satu komponen. Nilai bisnis yang nyata muncul ketika model bekerja di atas konteks perusahaan yang benar.
Model bisa dibeli, konteks perusahaan tidak
Perusahaan dapat membeli akses ke model frontier, memakai model open-source, atau mengganti vendor model seiring waktu. Namun tidak ada vendor yang bisa langsung menyediakan definisi "customer aktif" versi perusahaan Anda, aturan toleransi invoice mismatch yang berlaku di unit tertentu, relasi antara kontrak, order, shipment, dan dispute, atau histori exception yang biasa muncul saat finance close.
Agent yang tidak memahami konteks ini akan gagal pada titik yang paling penting: eksekusi operasional.
Contohnya di procurement. Sebuah agent mungkin mampu membaca permintaan pembelian dan menyarankan jalur proses. Tetapi jika master data supplier tidak konsisten, kategori belanja tidak standar, dan policy lokal tersebar di berbagai dokumen, agent bisa mengarahkan request ke jalur yang salah. Secara bahasa ia tampak pintar. Secara operasi ia menciptakan rework.
Contoh lain di customer operations. Agent dapat merangkum histori pelanggan dengan baik. Namun jika status entitlement, SLA, dan pengecualian kontrak tidak tersedia atau tidak sinkron, agent bisa memberi janji layanan yang tidak sesuai kontrak. Ini bukan sekadar error teknis; ini bisa menjadi masalah komersial dan reputasi.
Agent tanpa data akurat menghasilkan operational hallucination
Istilah halusinasi sering dipakai untuk menggambarkan model yang mengarang fakta. Dalam enterprise, bentuk yang lebih berbahaya adalah operational hallucination: output terdengar kredibel, tetapi salah terhadap realitas bisnis.
Misalnya agent finance menyimpulkan invoice belum dibayar padahal status di ERP sudah berubah. Atau agent HR menjawab kebijakan cuti berdasarkan dokumen lama yang belum diperbarui. Atau agent IT operations merekomendasikan runbook yang tidak relevan karena CMDB tidak akurat. Atau agent supply chain menyarankan rerouting tanpa memahami constraint stok aktual.
Masalahnya bukan hanya akurasi jawaban. Masalahnya adalah agent mulai memengaruhi tindakan, prioritas, dan keputusan.
Data readiness adalah pembeda antara pilot dan production
Banyak pilot agentic terlihat berhasil karena data dibersihkan manual, scope dipersempit, dokumen dipilih satu per satu, dan tim proyek mengawasi hasilnya secara intensif. Begitu masuk produksi, kondisi berubah. Data datang dari banyak sistem, definisi bisnis tidak seragam, dokumen berantakan, permission kompleks, dan exception jauh lebih banyak.
Di titik ini, perusahaan menyadari bahwa kesiapan data bukan pekerjaan pendukung. Ia adalah prasyarat scaling.
Karena itu, pertanyaan yang lebih penting dari "model apa yang dipakai?" sering kali adalah data bisnis mana yang menjadi sumber kebenaran, siapa pemiliknya, seberapa konsisten definisinya, bagaimana kualitasnya dimonitor, dan bagaimana agent mengaksesnya tanpa melanggar kontrol.
Structured Data: Fondasi untuk Action Agent
Jika agent akan bertindak di sistem enterprise, maka ia membutuhkan akses ke structured data yang menjadi representasi resmi state bisnis. Structured data biasanya mencakup entitas inti seperti customer, order, invoice, product, employee, supplier, asset, contract, ticket, dan transaksi keuangan. Inilah data yang paling dekat dengan tindakan operasional. Ketika agent mengecek status, memvalidasi kondisi, atau menyiapkan action, hampir selalu ia bergantung pada structured data.
Bukan sekadar tabel, tetapi objek bisnis yang harus konsisten
Kesalahan umum adalah menganggap structured data cukup tersedia karena perusahaan sudah punya ERP atau CRM. Kenyataannya, keberadaan sistem tidak otomatis berarti data siap untuk agent.
Agar berguna untuk agentic AI, structured data perlu memiliki setidaknya enam karakteristik.
Definisi bisnis yang konsisten. Apa arti "customer aktif"? Kapan sebuah order dianggap "fulfilled"? Apa beda "supplier approved" dan "supplier enabled"? Jika definisi ini berbeda antar-fungsi atau antar-negara, agent akan kesulitan mengambil keputusan yang konsisten. Dalam record-to-report, misalnya, definisi akun sensitif, materialitas, atau status rekonsiliasi harus jelas. Jika tidak, agent close orchestration akan memprioritaskan item yang salah.
Ownership yang jelas. Setiap domain data harus punya pemilik bisnis, bukan hanya administrator teknis. Harus jelas siapa yang bertanggung jawab atas kualitas customer master, vendor master, employee data, atau product hierarchy. Tanpa ownership, masalah data akan terus dianggap "isu sistem", padahal dampaknya langsung ke operasi agent.
Lineage yang dapat ditelusuri. Agent perlu bekerja di atas data yang asal-usulnya jelas. Jika sebuah field di dashboard berasal dari transformasi berlapis tanpa lineage yang baik, sulit memastikan apakah agent sedang membaca state bisnis yang benar atau hanya turunan yang sudah terlambat. Ini penting terutama untuk use case yang menyentuh keputusan operasional, bukan sekadar insight.
Kualitas yang termonitor. Data quality tidak bisa diasumsikan. Perusahaan perlu memonitor kelengkapan, keunikan, konsistensi, ketepatan waktu, dan validitas. Contoh di accounts payable: jika vendor master duplikat atau tax ID tidak lengkap, agent invoice resolution akan sering salah mengaitkan kasus. Contoh di HR operations: jika struktur organisasi tidak mutakhir, agent onboarding bisa salah mengarahkan approval atau notifikasi.
Semantik yang cukup kuat. Structured data untuk agent tidak cukup hanya "tersimpan". Ia harus punya makna yang bisa dipahami lintas sistem. Di sinilah model data enterprise, canonical model, atau master data management menjadi relevan. Beberapa organisasi yang lebih matang juga mulai menekankan enterprise data model yang konsisten agar keputusan agent tidak berubah-ubah tergantung sistem sumber.
Interface akses yang aman. Agent sebaiknya tidak membaca tabel inti secara liar. Akses ke structured data harus melalui interface yang menjaga permission, audit trail, schema yang stabil, dan policy enforcement. Dengan kata lain, structured data untuk agent harus diakses seperti capability enterprise, bukan seperti shortcut teknis.
Contoh enterprise: finance, procurement, dan shared services
Di finance close, agent yang membantu close membutuhkan data seperti status rekonsiliasi, jurnal terbuka, aging exception, close calendar, dan mapping akun. Jika data ini konsisten dan punya lineage jelas, agent bisa memprioritaskan exception, menyiapkan commentary, dan mengorkestrasi follow-up. Jika tidak, agent hanya menambah noise.
Di procurement, agent intake-to-PO membutuhkan supplier master, kategori belanja, kontrak aktif, budget status, dan histori pembelian. Jika supplier master kacau atau kategori tidak standar, agent akan sering salah memilih jalur pembelian. Dalam domain ini, kualitas master data sering lebih menentukan daripada kecanggihan model.
Di shared services, structured data sering tersebar lintas fungsi. Agent case management mungkin perlu menggabungkan data tiket, SLA, status transaksi, dan histori interaksi. Jika identifier antar-sistem tidak sinkron, agent akan kesulitan membangun satu pandangan kasus yang utuh.
Kapan structured data belum cukup
Structured data sangat penting untuk action. Tetapi banyak konteks enterprise justru tidak hidup di tabel transaksi. Policy, kontrak, email, call transcript, SOP, dan catatan kasus sering menjadi penentu keputusan. Di sinilah unstructured data masuk.
Unstructured Data: Tempat Konteks Nyata Sering Bersembunyi
Banyak organisasi baru menyadari nilai unstructured data ketika mulai membangun agent. Selama ini, dokumen dan komunikasi sering diperlakukan sebagai arsip pasif. Dalam agentic AI, sumber-sumber ini berubah menjadi lapisan konteks aktif.
Unstructured data biasanya mencakup dokumen kebijakan, SOP, kontrak, email, call transcript, chat history, image atau scan dokumen, notulen, knowledge article, dan catatan penanganan kasus. Untuk banyak workflow enterprise, justru di sinilah alasan di balik keputusan berada.
Dalam customer operations, status tiket mungkin ada di CRM, tetapi konteks emosi pelanggan, janji yang pernah diberikan, atau akar masalah sering ada di transcript dan histori percakapan. Dalam procurement, supplier master ada di sistem, tetapi syarat komersial dan pengecualian kontrak ada di dokumen. Dalam HR, data karyawan ada di HRIS, tetapi kebijakan lokal, FAQ, dan pengecualian program sering hidup di portal, PDF, atau email. Dalam IT operations, alert ada di observability platform, tetapi runbook, postmortem, dan workaround historis sering tersebar di wiki, ticket notes, dan chat channel.
Agentic AI membuka nilai baru dari unstructured data karena agent tidak hanya "mencari dokumen". Ia bisa membaca beberapa sumber sekaligus, membandingkan isi dokumen, menghubungkan konteks historis dengan state transaksi, lalu bertindak atau mengeskalasi berdasarkan konteks tersebut.
Unstructured data membutuhkan pipeline, bukan sekadar upload dokumen
Banyak implementasi awal berhenti pada "unggah dokumen ke vector store". Untuk enterprise, itu terlalu dangkal. Unstructured data perlu dikelola melalui pipeline yang disiplin.
Ingestion. Dokumen harus masuk dari sumber yang jelas: repository resmi, email archive, call center platform, contract management system, knowledge base, atau file share yang telah dikurasi. Jika ingestion tidak terkontrol, agent akan menarik konteks dari sumber yang tidak otoritatif.
Classification. Tidak semua dokumen punya bobot yang sama. Perusahaan perlu membedakan policy resmi, draft, dokumen kadaluarsa, kontrak aktif, komunikasi informal, dan materi referensi. Tanpa klasifikasi, agent bisa mengutip dokumen lama seolah masih berlaku.
Chunking dan enrichment. Dokumen panjang perlu dipecah menjadi unit yang bisa diambil secara relevan. Tetapi chunking tidak boleh buta. Metadata seperti pemilik dokumen, tanggal berlaku, versi, wilayah, fungsi, tingkat kerahasiaan, dan status aktif atau nonaktif sering lebih penting daripada embedding itu sendiri.
Embeddings dan retrieval. Embeddings membantu pencarian semantik, tetapi retrieval enterprise harus lebih dari sekadar similarity search. Ia perlu mempertimbangkan metadata, permission, dan konteks workflow. Policy HR untuk Indonesia tidak boleh muncul untuk kasus karyawan di negara lain hanya karena bahasanya mirip.
Retention dan lifecycle. Unstructured data juga punya umur. Email lama, transcript sensitif, atau kontrak yang sudah berakhir tidak boleh dibiarkan terus menjadi konteks aktif tanpa aturan. Retention policy harus diterapkan agar agent tidak membangun keputusan dari memori yang seharusnya sudah tidak relevan.
Trade-off penting pada unstructured data
Ada godaan untuk memasukkan semua dokumen ke sistem agentic. Ini jarang bijak. Semakin banyak dokumen yang dimasukkan tanpa kurasi, semakin tinggi noise, semakin besar risiko retrieval salah, semakin sulit menjaga permission, dan semakin mahal biaya pemrosesan.
Karena itu, strategi yang lebih sehat adalah memulai dari corpus yang otoritatif dan bernilai tinggi. Misalnya SOP resmi untuk shared services, kontrak aktif untuk procurement, knowledge article terverifikasi untuk service desk, atau policy HR yang sudah dikurasi. Bukan semua file yang pernah dibuat perusahaan.
Data Governance untuk Agents: Dari Kebijakan ke Runtime
Pada tahap ini, banyak perusahaan merasa sudah punya data governance: ada klasifikasi data, ada kebijakan akses, ada data owner, ada retention policy. Masalahnya, governance tradisional sering berhenti di dokumen, komite, atau kontrol manual. Untuk agentic AI, governance harus diterjemahkan ke runtime.
Pertanyaan kuncinya bukan hanya "siapa boleh mengakses data ini?" tetapi siapa boleh mengakses data ini melalui agent, untuk tujuan apa, dalam workflow apa, dengan tingkat otonomi apa, dan apakah akses itu menghasilkan tindakan atau hanya insight.
Permission harus berlaku saat retrieval dan tool call
Ini titik yang sangat penting. Jika agent mengambil konteks dari dokumen atau structured data, permission harus diperiksa saat retrieval terjadi, bukan setelah jawaban keluar.
Agent HR tidak boleh menarik data kompensasi jika user tidak berhak. Agent procurement tidak boleh membuka kontrak strategis ke requester biasa. Agent finance tidak boleh menampilkan data entitas tertentu di luar scope pengguna. Agent customer service tidak boleh mengakses histori sensitif tanpa verifikasi identitas yang tepat.
Hal yang sama berlaku untuk tool call. Hak membaca status order berbeda dengan hak mengubah order. Hak melihat vendor berbeda dengan hak mengubah vendor master.
Governance untuk agents membutuhkan konteks tujuan
Dalam enterprise, akses data tidak hanya soal identitas, tetapi juga soal purpose. Seorang agent mungkin sah membaca data invoice untuk menyelesaikan exception AP, tetapi tidak sah menggunakan data yang sama untuk membuat ringkasan yang dibagikan ke pihak yang tidak relevan.
Karena itu, governance agentic perlu menghubungkan identitas agent, identitas user atau proses yang diwakili, tujuan bisnis, dan workflow yang sedang berjalan. Ini lebih kompleks daripada model akses aplikasi tradisional, tetapi juga lebih realistis.
Audit trail harus menjelaskan konteks keputusan
Untuk agent, audit trail yang baik tidak cukup mencatat "akses terjadi". Ia harus bisa menjelaskan data apa yang diambil, dari sumber mana, berdasarkan permission apa, dalam workflow apa, dan bagaimana data itu memengaruhi keputusan atau tindakan. Ini penting untuk risk, compliance, dan juga untuk perbaikan operasional. Jika agent salah memberi rekomendasi, perusahaan harus bisa menelusuri apakah masalahnya ada pada kualitas data, retrieval yang salah, metadata yang kurang, atau policy yang tidak diterapkan.
Sinyal bahwa governance data belum siap untuk agents
Beberapa gejala yang sering muncul adalah data owner tidak tahu bahwa datanya dipakai agent, dokumen resmi dan draft bercampur tanpa versi yang jelas, permission di knowledge layer lebih longgar daripada di sistem sumber, tidak ada metadata tentang tanggal berlaku atau wilayah kebijakan, agent bisa mengakses data karena service account generik, dan tidak ada cara mudah untuk menonaktifkan corpus atau sumber data tertentu saat terjadi insiden.
Jika gejala ini ada, scaling agentic AI akan memperbesar risiko lebih cepat daripada nilai.
Memperkuat Data Foundation Sebelum Scaling
Setelah memahami pentingnya data foundation, ada beberapa keputusan yang perlu diambil sekarang. Pertama, tentukan domain data prioritas untuk use case agentic pertama. Jangan mulai dari "semua data perusahaan". Pilih domain yang paling dekat dengan value stream prioritas, misalnya customer, invoice, supplier, employee, atau ticket. Kedua, putuskan sumber kebenaran untuk structured data dan corpus otoritatif untuk unstructured data. Agent tidak boleh dibiarkan memilih sendiri dari lanskap data yang ambigu. Ketiga, tetapkan ownership lintas data dan workflow. Harus jelas siapa pemilik business data, siapa pemilik knowledge corpus, dan siapa yang bertanggung jawab atas permission serta quality monitoring. Keempat, bangun governance runtime, bukan hanya governance dokumen. Permission, metadata, retention, dan policy harus berlaku saat retrieval dan tool call terjadi. Kelima, pilih strategi kurasi unstructured data. Mulai dari corpus bernilai tinggi dan resmi; jangan memasukkan semua dokumen hanya demi cakupan.
Untuk menilai kesiapan perusahaan, perhatikan apakah domain structured data utama untuk use case prioritas sudah diidentifikasi, definisi bisnis untuk entitas penting cukup konsisten lintas fungsi, ada owner yang jelas untuk customer, supplier, employee, order, invoice, atau domain lain yang relevan, kualitas data utama dimonitor minimal untuk kelengkapan, konsistensi, dan ketepatan waktu, agent mengakses structured data melalui interface yang menjaga permission dan audit trail, corpus unstructured data yang akan dipakai agent sudah dikurasi dan dibedakan dari dokumen draft atau kadaluarsa, metadata penting seperti versi, tanggal berlaku, wilayah, dan klasifikasi kerahasiaan tersedia, retrieval menerapkan permission yang konsisten dengan sistem sumber, retention policy untuk dokumen, transcript, dan histori interaksi sudah dipertimbangkan, serta ada logging yang cukup untuk menelusuri data apa yang dipakai agent dalam menghasilkan rekomendasi atau tindakan.
Waspadai sinyal bahaya bahwa topik ini belum siap di-scale. Jika tim AI berkata "nanti data dibersihkan belakangan", jika master data inti masih diperdebatkan antar-fungsi, jika agent mengambil jawaban dari dokumen yang tidak jelas status resminya, jika tidak ada metadata versi atau tanggal berlaku pada policy, jika service account agent memiliki akses terlalu luas ke data lintas domain, jika retrieval dari knowledge base tidak menghormati permission pengguna, jika tidak ada data lineage yang memadai untuk field penting, dan jika bisnis belum menunjuk owner yang bertanggung jawab atas kualitas konteks yang dipakai agent, maka scaling akan memperbesar risiko.
Sebelum memperluas agentic AI, tanyakan secara jujur: apakah perusahaan kita sedang membangun agent yang benar-benar memahami cara kerja bisnis, atau hanya membangun antarmuka cerdas di atas data yang belum siap dipercaya? Jika jawabannya yang kedua, prioritas berikutnya bukan menambah agent baru. Prioritasnya adalah memperkuat data foundation agar agent yang sudah ada layak dipercaya, diaudit, dan diskalakan.