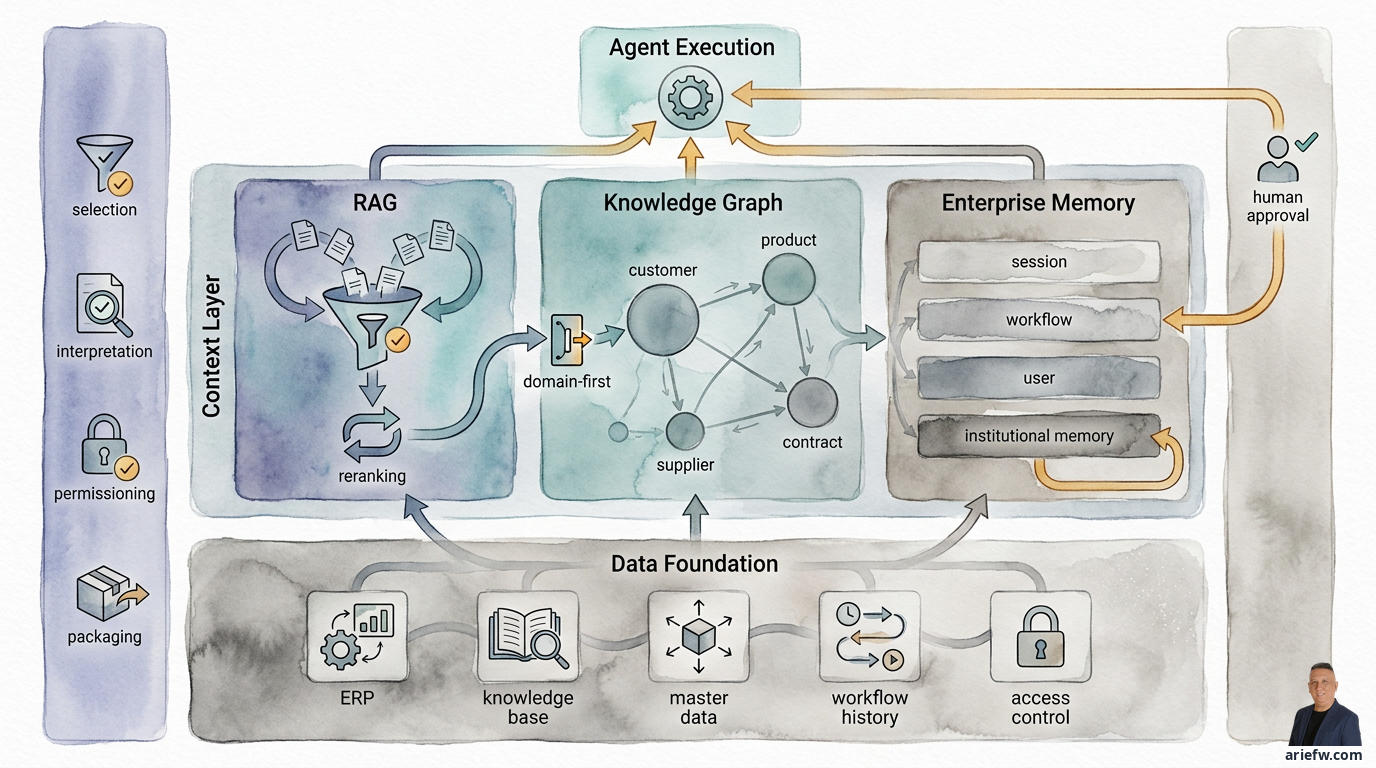
コンテキストレイヤー:RAG、ナレッジグラフ、エンタープライズメモリ
皆さんの財務チームが、月次決算のプロセスを支援するエージェントの導入を検討していると想像してください。そのエージェントはデータにアクセスできるものの、結果は不安定です。時には、すでに無効となっている会計方針を参照し、時には異なる事業体のデータを混同し、また時には特定の手順が既に完了していることを忘れてしまいます。チームは疑念を抱き始めます。このエージェントは本当に役立つのか、それともむしろ業務を増やしているだけなのか、と。
このような状況は、AIモデルの性能が低いからではありません。より根本的な問題があります。それは、エージェントに与えられるコンテキストが未加工すぎるか、広範すぎるか、あるいは制御が効いていないことです。多くのチームは、この欠点を、プロンプトを長くしたり、指示を複雑にしたり、検索をより積極的に行ったりすることで補おうとします。しかし、結果は安定しません。エージェントが賢く見えることもあれば、誤った文書を取得したり、以前の決定を忘れたり、アクセス権限を侵害したりすることもあります。
企業にとって、コンテキストとは単なる「付加情報」ではありません。コンテキストとは、エージェントが関連性が高く、安全で、説明責任を果たせる意思決定を行えるかどうかを決定づける、運用上のレイヤーなのです。
コンテキストレイヤーとは何か
エージェントが動作する際、単一のデータソースのみに依存することはほぼありません。あるケースを解決するために、エージェントはERPからの取引ステータス、ナレッジベースからのポリシー、マスターデータからのエンティティ関係、以前のワークフローからの決定履歴、そしてユーザーやプロセスのIDに基づくアクセス制限を組み合わせる必要があるかもしれません。これらすべてを未加工のまま提供することはできません。
コンテキストレイヤーとは、データとナレッジを、意思決定にすぐに利用できるコンテキストに変換するレイヤーです。その役割は4つあります。第一に、選択:特定のタスクに真に関連する情報を選別すること。第二に、解釈:情報にビジネス上の意味を与えること。例えば、アクティブなポリシーと古いドラフトを区別すること。第三に、パーミッショニング:エージェントがアクセスを許可されたコンテキストのみを参照することを保証すること。第四に、パッケージング:エージェントが効率的に利用できる形でコンテキストを提供すること。
これら4つの役割がなければ、エージェントは2つの悪いパターンに陥りがちです。第一に、すべての指示とコンテキストを一度に詰め込もうとする長大なプロンプトへの過度な依存。第二に、制御不能な検索への過度な依存であり、その結果、エージェントは情報を取得しすぎたり、逆に少なすぎたりします。
なぜコンテキストレイヤーが独立したアーキテクチャ領域となるのか
シンプルなコパイロットでは、モデルが文書を検索できればコンテキストは十分と見なされることがよくあります。しかし、エージェント型エンタープライズでは、それでは不十分です。エージェントは、現在の運用状況を理解し、適用されるルールを解釈し、既に実行された手順を記憶し、権限の範囲内で行動しなければなりません。
先の財務決算の例を見てみましょう。例外処理を支援するエージェントは、決算手順書を読むだけでは不十分です。どの事業体を処理しているのか、どの勘定科目が重要か、どのような例外がすでに発生しているか、誰が以前に決定を下したか、そして同様のケースが特定の処理方法で解決されたことがあるかどうかを知る必要もあります。
調達の例を見てみましょう。インテークから発注までのエージェントは、購買ポリシーを読むだけでは不十分です。購買カテゴリ、関連する有効な契約、承認されたサプライヤー、承認閾値、そしてその事業単位における例外の履歴を知る必要があります。
コンテキストレイヤーは、データ基盤とエージェント実行の間の橋渡し役です。この橋渡しがなければ、エージェントは適切な意思決定を行うのに不十分な情報に基づいて動作することになります。
制御されたナレッジ検索のためのRAG
コンテキストレイヤーの最初の、そして最も一般的に使用されるコンポーネントは、検索拡張生成(RAG)です。その役割は明確です。エージェントが企業のナレッジベースから関連する文書や情報断片を取得し、その情報を使用して回答、推論、またはアクションの準備を行うのを支援することです。
多くのユースケースにおいて、これは合理的な出発点です。ナレッジ記事を読む必要があるサービスデスク、ポリシーに回答する必要がある人事オペレーション、SOPや契約を参照する必要がある調達、条項を比較する必要がある法務オペレーション、または会計ガイダンスを取得する必要がある財務などです。
しかし、優れたRAGは、単に文書をベクターデータベースに入力するよりもはるかに困難です。その品質は、検索モデルだけでなく、上流の設計によって決定されます。
通常、6つの要素が最も重要です。第一に、データソース。コーパスに公式ポリシー、古いドラフト、非公式な電子メール、所有者が不明なファイルが混在している場合、検索はノイズを生成します。RAGの品質は、入力されるコーパスの品質に依存します。
第二に、チャンキング。長い文書は、関連性を持って取得できる単位に分割する必要があります。チャンクが大きすぎると検索が不明瞭になります。小さすぎるとコンテキストが途切れます。エンタープライズでは、チャンキングは多くの場合、単なる文字数ではなく、ビジネス文書の構造に従う必要があります。
第三に、メタデータ。メタデータは、しばしば埋め込みよりも重要です。有効日、文書バージョン、地域、機能、機密レベル、アクティブ/非アクティブステータス、文書所有者は、検索の精度を大幅に向上させるのに役立ちます。
第四に、検索戦略。類似性検索だけでは不十分なことがよくあります。多くの実装では、セマンティック検索、キーワード検索、メタデータフィルタリング、そして時にはワークフローのコンテキストに基づくクエリ拡張を組み合わせることで、より良い結果が得られます。
第五に、再ランキング。初期の検索結果は、最も関連性が高く、最も権威のある断片が最初に表示されるように再順序付けする必要があります。これは、複数の文書が類似しているように見えても、ビジネス上のステータスが異なる場合に特に重要です。
第六に、回答の評価。RAGは「回答が良さそうに聞こえる」という理由だけで評価されるべきではありません。企業は、エージェントが正しい文書を取得しているか、有効なポリシーを引用しているか、矛盾するソースを混在させていないか、そして意思決定に真に役立つ回答を生成しているかをテストする必要があります。
最も危険な誤りの一つは、技術的にはスマートだが、パーミッションに対して無知なRAGを構築することです。エージェントは、文書が意味的に relevant であるという理由だけで文書を取得するべきではありません。エージェントは、その文書が、自身が代表するユーザーまたはワークフローによってアクセス可能かどうかもチェックする必要があります。人事エージェントは、すべての従業員に対して機密性の高い報酬文書を取得するべきではありません。調達エージェントは、通常の要求者に対して戦略的契約を開示するべきではありません。パーミッション・アウェアなRAGとは、回答が形成された後ではなく、検索が行われる時点でアクセス制御が適用されることを意味します。
文書では捉えきれないビジネス関係のためのナレッジグラフ
RAGがエージェントの「書かれていること」の発見を支援するのに対し、ナレッジグラフはエージェントの「何が何と関係しているか」の理解を支援します。ナレッジグラフは、ビジネス上のエンティティとその関係を明示的に表現します。エンティティには、顧客、製品、サプライヤー、契約、資産、場所、ポリシー、リスク、従業員、ケースなどが含まれます。関係には、顧客が特定の契約を保有している、サプライヤーが特定の製品に部品を供給している、または製品が特定のポリシーに従う、などがあります。
エンタープライズエージェントにとって、グラフが有用なのは、多くの運用上の意思決定が単一の文書や単一のテーブルから行うことができないためです。意思決定は、しばしば関係のネットワークに依存します。
最も明確な例は、サプライチェーン・コントロールタワーにあります。配送遅延が発生した場合、エージェントは、この出荷がどの顧客注文に関連しているか、その注文にはどの製品が含まれているか、その製品はどのサプライヤーに依存しているか、その顧客にはどのようなSLAや優先順位があるか、どの場所が影響を受けるか、そして特定のエスカレーションに関する契約やポリシーがあるかどうかを理解する必要があります。これらはすべて、文書の山よりもグラフとしてモデル化する方が簡単です。
コンプライアンスレビューの別の例を見てみましょう。エージェントは、特定の取引、ベンダー、契約、ポリシーが特定のリスクカテゴリと相互に関連しているかどうかを評価する必要があります。これらの関係が明示的でない場合、エージェントは一貫した推論を行うのに苦労するでしょう。
多くの組織は、大規模で、高コストで、時間のかかる全社的なプロジェクトを想像して、ナレッジグラフを避けています。それは必要ありません。より現実的なアプローチは、優先度の高いユースケースのためにドメイングラフから始めることです。調達におけるベンダー・契約・カテゴリ・ポリシーの関係のグラフ、カスタマーサービスにおける顧客・製品・チケット・SLAのグラフ、または財務決算におけるエンティティ・勘定科目・仕訳・コントロールのグラフなどです。
ドメインファーストのアプローチには3つの利点があります。価値をより早く生み出せること、ビジネスオーナーによる検証が容易であること、そして一度に全社をマッピングしようとするよりもガバナンスが効きやすいことです。
グラフは非常に有用ですが、常に必要というわけではありません。グラフは通常、エンティティ間の関係が実際に意思決定に影響を与える場合、ワークフローがクロスドメインである場合、そして文書のみに依存した推論では不十分な場合に価値があります。ユースケースが依然として単純で文書ベースである場合、ビジネスエンティティがまだ安定していない場合、または組織がデータオーナーシップを十分に明確にしていない場合、グラフはまだ適切ではないかもしれません。
エンタープライズメモリ:誤りを真実として保存せずに記憶する
コンテキストレイヤーの3つ目のコンポーネントはメモリです。メモリにより、エージェントは単一のプロンプトや単一のクエリでは常に利用できるとは限らないコンテキストを記憶することができます。これは、多くのエンタープライズ業務が複数のステップ、複数日にわたって、さらにはチームをまたいで行われるため、重要です。
しかし、エンタープライズにおけるメモリは、規律を持って理解されなければなりません。すべてを記憶する必要はなく、すべての記憶が同じように扱われるべきではありません。
区別すべき4つのタイプのメモリがあります。第一に、セッションメモリ:1回のセッションにおける会話やインタラクションのコンテキストです。例えば、エージェントがユーザーが特定の請求書について話し合っていることを覚えていることなどです。セッションメモリは会話の一貫性を保つのに役立ちますが、通常は長期間保存する必要はありません。
第二に、ワークフローメモリ:進行中の作業のステータスに関する記憶です。どのステップが実行されたか、どの文書がチェックされたか、どのような決定が下されたか、誰が承認したか、どのような例外がまだ未解決かなどです。これは、財務決算、調達ケース管理、インシデント対応などのワークフローにとって非常に重要です。
第三に、ユーザーメモリ:特定のユーザーの好みやコンテキストです。例えば、好みのレポート形式や特定の作業パターンなどです。ユーザーメモリはエクスペリエンスを向上させることができますが、プライバシーや公平性に関わるため、慎重に管理する必要があります。
第四に、インスティテューショナルメモリ:より長期間持続する組織の学習です。頻繁に発生する例外のパターン、過去に成功した処理方法、エージェントの推奨に対する人間からのフィードバック、繰り返し発生する運用上の知識などです。インスティテューショナルメモリは継続的改善にとって最も価値がありますが、キュレーションされない場合には最もリスクも高くなります。
メモリがなければ、エージェントは運用上の記憶喪失のように動作する傾向があります。ケースが開かれるたびに、エージェントはゼロから始めなければなりません。セッション間の引き継ぎは不十分で、以前の決定は考慮されず、人間からのフィードバックは失われ、長いワークフローは脆弱になります。
IT運用において、繰り返し発生するインシデントを処理するエージェントは、どのランブックが過去に成功したか、関連する承認者は誰か、根本原因となることが多いシステム依存関係は何かを記憶できるべきです。債権回収において、エージェントは過去の支払い約束、顧客の応答、および既に実行されたフォローアップアクションを記憶し、矛盾する連絡を送らないようにするべきです。
エンタープライズにおいて、メモリはルールのない自由なメモ帳のように扱われるべきではありません。最低限の4つの規律があります。保持期間:何を、どのくらいの期間保存し、いつ削除するかを明確にしなければなりません。プライバシー:メモリには機密データが含まれる可能性があるため、その保存と使用は厳格なプライバシーおよびアクセスポリシーに従わなければなりません。監査:企業は、エージェントが特定の推奨やアクションを生成するためにどのメモリを使用したかを説明できなければなりません。修正:メモリには修正メカニズムがなければなりません。エージェントが誤った結論を保存した場合、人間からのフィードバックによってそのメモリを修正またはフラグ付けできなければなりません。
メモリのタイプを明確に区別できていない、保持ポリシーがない、人間からのフィードバックが修正メカニズムに組み込まれていない、またはエージェントが分類なしにあまりにも多くのコンテキストを保存している場合、メモリをスケールする準備はまだ整っていません。
RAG、グラフ、メモリを単一のコンテキストレイヤーに統合する
これら3つのコンポーネントは互いに置き換わるものではありません。それらは互いに補完し合います。RAGは、エージェントが文書やエンタープライズコーパスから関連するナレッジを取得するのを支援します。ナレッジグラフは、エージェントがビジネスエンティティ間の関係を理解するのを支援します。メモリは、エージェントがセッション、ワークフロー、および運用学習をまたいでコンテキストの継続性を維持するのを支援します。
成熟したエンタープライズワークフローでは、これら3つはしばしば連携して動作します。調達例外処理では、RAGが関連する購買ポリシーと契約条項を取得し、グラフが要求者、カテゴリ、サプライヤー、契約、承認パス間の関係を示し、メモリが同様のケースが過去に特定の書類不備で却下されたことを記憶します。財務決算では、RAGが会計ガイダンスと決算SOPを取得し、グラフがエンティティ、勘定科目、仕訳、コントロール間の関係をマッピングし、メモリが例外の履歴と過去の管理者の決定を保存します。
ここにおいて、コンテキストレイヤーは、単なる検索レイヤーではなく、真に実行のレイヤーとなるのです。
実務的な含意
コンテキストレイヤーは、1週間で完了できるテクノロジープロジェクトではありません。これは、エージェントが運用上の意思決定を任せられるかどうかを決定する、アーキテクチャ上の決定です。
CIOにとっての問いは、自社がガバナンス可能なコンテキストレイヤーを既に持っているのか、それとも依然としてプロンプトエンジニアリングやアドホックな検索に依存しているのか、です。COOにとっては、優先度の高いワークフローにおいて、エージェントが関連性が高く安全な意思決定を行うために真に必要とするコンテキストは何か、です。CHROにとっては、エージェントがユーザーメモリやインスティテューショナルメモリの保存を開始する場合、プライバシー、公平性、修正に関するポリシーは既に整っているか、です。変革リーダーにとっては、エージェント型ユースケースが、信頼できるエンタープライズコンテキストの上に構築されているのか、それとも印象的に見えるデモレベルの検索の上に構築されているのか、です。
これらの問いに対する答えがまだ不明確であるならば、次の優先事項は新しいエージェントを追加することではありません。優先事項は、正確で、関連性が高く、安全なコンテキストレイヤーを構築することです。なぜなら、エージェントに対する運用上の信頼は、まさにそこで形成されるからです。