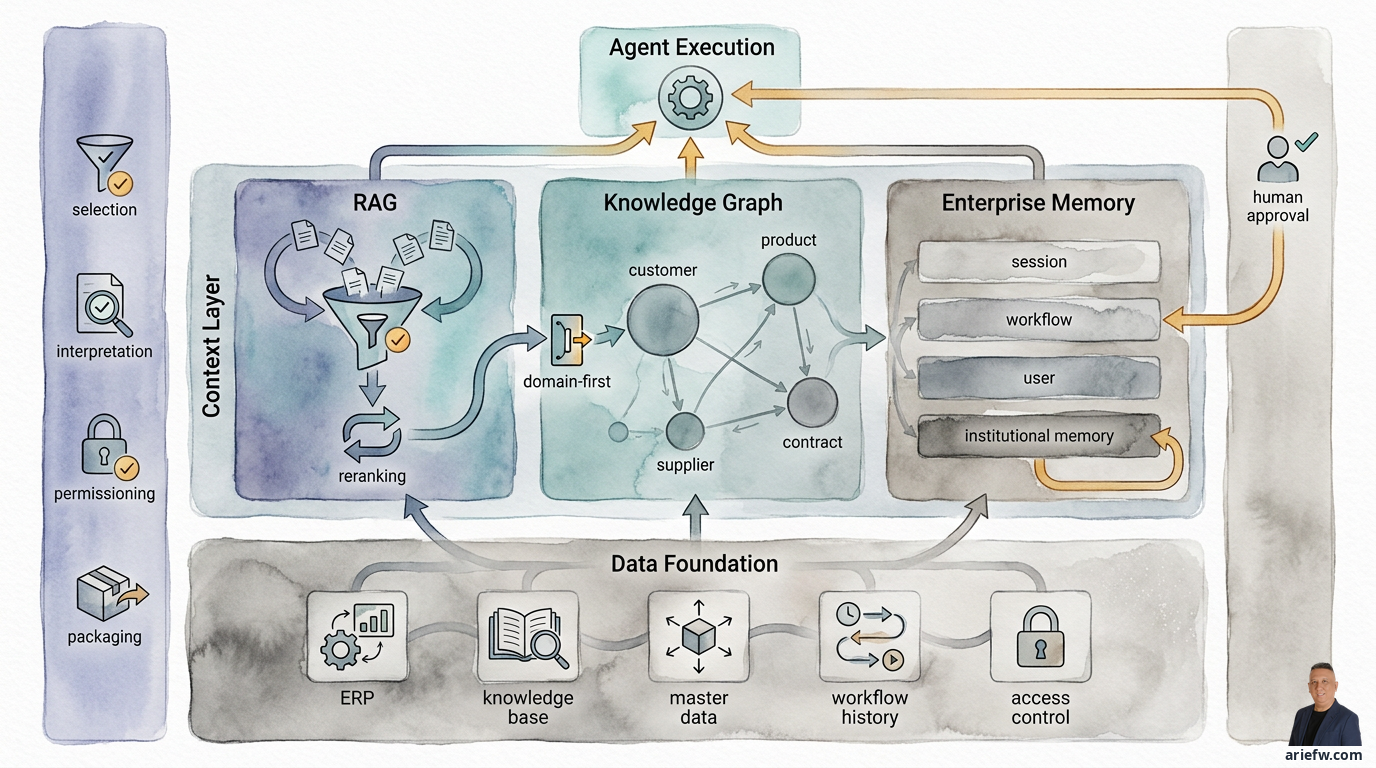
Context Layer: RAG, Knowledge Graph, dan Enterprise Memory
Bayangkan tim finance Anda sedang mencoba menggunakan agent untuk membantu proses penutupan buku bulanan. Agent itu bisa mengakses data, tetapi hasilnya aneh: kadang ia mengambil kebijakan akuntansi yang sudah tidak berlaku, kadang ia mencampur data entitas yang berbeda, dan kadang ia lupa bahwa langkah tertentu sudah dilakukan. Tim Anda mulai ragu—apakah agent ini benar-benar bisa membantu, atau malah menambah pekerjaan?
Situasi seperti ini bukan karena model AI-nya lemah. Masalahnya lebih mendasar: konteks yang diberikan ke agent terlalu mentah, terlalu luas, atau tidak terkontrol. Banyak tim mencoba menambal kekurangan ini dengan prompt yang makin panjang, instruksi yang makin rumit, atau retrieval yang makin agresif. Hasilnya tidak stabil. Kadang agent terlihat pintar, kadang salah mengambil dokumen, kadang lupa keputusan sebelumnya, dan kadang melanggar batas akses.
Untuk perusahaan, konteks bukan sekadar "tambahan informasi". Konteks adalah lapisan operasional yang menentukan apakah agent bisa mengambil keputusan yang relevan, aman, dan dapat dipertanggungjawabkan.
Apa yang Dimaksud dengan Context Layer
Ketika sebuah agent bekerja, ia hampir tidak pernah hanya bergantung pada satu sumber data. Untuk menyelesaikan satu kasus, agent mungkin perlu menggabungkan status transaksi dari ERP, policy dari knowledge base, relasi entitas dari master data, histori keputusan dari workflow sebelumnya, dan batas akses berdasarkan identitas user atau proses. Semua ini tidak bisa diberikan secara mentah.
Context layer adalah lapisan yang mengubah data dan knowledge menjadi konteks yang siap dipakai untuk keputusan. Pekerjaannya mencakup empat hal. Pertama, seleksi: memilih informasi yang benar-benar relevan untuk tugas tertentu. Kedua, interpretasi: memberi makna bisnis pada informasi, misalnya membedakan policy aktif dari draft lama. Ketiga, permissioning: memastikan agent hanya melihat konteks yang memang boleh diakses. Keempat, packaging: menyajikan konteks dalam bentuk yang bisa dipakai agent secara efisien.
Tanpa keempat pekerjaan ini, agent cenderung jatuh ke dua pola buruk. Pertama, terlalu bergantung pada prompt panjang yang berusaha menjejalkan semua instruksi dan konteks sekaligus. Kedua, terlalu bergantung pada retrieval yang tidak terkontrol, sehingga agent mengambil terlalu banyak atau terlalu sedikit informasi.
Mengapa Context Layer Menjadi Lapangan Arsitektur Tersendiri
Dalam copilot sederhana, konteks sering dianggap cukup jika model bisa mencari dokumen. Dalam agentic enterprise, itu tidak cukup. Agent harus memahami situasi operasional saat ini, menafsirkan aturan yang berlaku, mengingat langkah yang sudah dilakukan, dan bertindak sesuai batas kewenangan.
Lihat contoh di finance close. Agent yang membantu penyelesaian exception tidak cukup hanya membaca SOP close. Ia juga perlu tahu entitas mana yang sedang diproses, akun mana yang material, exception apa yang sudah dibuka, siapa yang memberi keputusan sebelumnya, dan apakah kasus serupa pernah diselesaikan dengan treatment tertentu.
Contoh di procurement. Agent intake-to-PO tidak cukup hanya membaca policy pembelian. Ia perlu tahu kategori belanja, kontrak aktif yang relevan, supplier yang disetujui, threshold approval, dan histori pengecualian untuk unit bisnis tersebut.
Context layer adalah jembatan antara data foundation dan agent execution. Tanpa jembatan ini, agent bekerja di atas informasi yang tidak cukup untuk mengambil keputusan yang baik.
RAG untuk Knowledge Retrieval yang Terkendali
Komponen pertama dari context layer yang paling sering dipakai adalah retrieval-augmented generation, atau RAG. Perannya cukup jelas: membantu agent mengambil dokumen atau potongan informasi yang relevan dari knowledge base perusahaan, lalu menggunakan informasi itu untuk menjawab, menalar, atau menyiapkan tindakan.
Untuk banyak use case, ini adalah titik masuk yang masuk akal. Service desk yang perlu membaca knowledge article, HR operations yang perlu menjawab policy, procurement yang perlu merujuk SOP dan kontrak, legal ops yang perlu membandingkan klausul, atau finance yang perlu mengambil accounting guidance.
Namun RAG yang baik jauh lebih sulit daripada sekadar memasukkan dokumen ke vector database. Kualitasnya ditentukan oleh desain hulu, bukan hanya model pencarian.
Enam faktor biasanya paling menentukan. Pertama, sumber data. Jika corpus berisi campuran policy resmi, draft lama, email informal, dan file yang tidak jelas pemiliknya, retrieval akan menghasilkan noise. RAG hanya sebaik kualitas corpus yang dimasukkan.
Kedua, chunking. Dokumen panjang harus dipecah menjadi unit yang bisa diambil secara relevan. Chunk yang terlalu besar membuat retrieval kabur. Chunk yang terlalu kecil membuat konteks terputus. Untuk enterprise, chunking sering perlu mengikuti struktur dokumen bisnis, bukan sekadar jumlah karakter.
Ketiga, metadata. Metadata sering lebih penting daripada embedding. Tanggal berlaku, versi dokumen, wilayah, fungsi, tingkat kerahasiaan, status aktif atau nonaktif, dan pemilik dokumen membantu retrieval menjadi jauh lebih presisi.
Keempat, search strategy. Similarity search saja sering tidak cukup. Banyak implementasi yang lebih baik menggabungkan pencarian semantik, keyword, filter metadata, dan kadang query expansion berdasarkan konteks workflow.
Kelima, reranking. Hasil retrieval awal perlu diurutkan ulang agar potongan yang paling relevan dan paling otoritatif muncul lebih dulu. Ini penting terutama ketika beberapa dokumen tampak mirip tetapi status bisnisnya berbeda.
Keenam, evaluasi jawaban. RAG tidak boleh dinilai hanya dari "jawaban terdengar bagus". Perusahaan perlu menguji apakah agent mengambil dokumen yang benar, mengutip policy yang masih berlaku, tidak mencampur sumber yang bertentangan, dan menghasilkan jawaban yang benar-benar membantu keputusan.
Salah satu kesalahan paling berbahaya adalah membangun RAG yang pintar secara teknis tetapi buta terhadap permission. Agent tidak boleh mengambil dokumen hanya karena dokumen itu relevan secara semantik. Agent juga harus memeriksa apakah dokumen itu boleh diakses oleh user atau workflow yang diwakilinya. Agent HR tidak boleh menarik dokumen kompensasi sensitif untuk semua karyawan. Agent procurement tidak boleh membuka kontrak strategis ke requester biasa. Permission-aware RAG berarti kontrol akses diterapkan saat retrieval terjadi, bukan setelah jawaban dibentuk.
Knowledge Graph untuk Relasi Bisnis yang Tidak Tertangkap oleh Dokumen
Jika RAG membantu agent menemukan apa yang tertulis, maka knowledge graph membantu agent memahami apa yang berhubungan dengan apa. Knowledge graph merepresentasikan entitas dan relasi bisnis secara eksplisit. Entitas itu bisa berupa customer, product, supplier, contract, asset, location, policy, risk, employee, atau case. Relasinya bisa berupa customer memiliki kontrak tertentu, supplier memasok komponen untuk product tertentu, atau product tunduk pada policy tertentu.
Untuk agent enterprise, graph berguna karena banyak keputusan operasional tidak bisa dibuat hanya dari satu dokumen atau satu tabel. Keputusan sering bergantung pada jaringan relasi.
Contoh paling jelas ada pada supply chain control tower. Ketika ada keterlambatan pengiriman, agent perlu memahami shipment ini terkait order pelanggan mana, order itu berisi product apa, product itu bergantung pada supplier mana, pelanggan tersebut punya SLA atau prioritas apa, lokasi mana yang terdampak, dan apakah ada kontrak atau kebijakan eskalasi tertentu. Semua itu lebih mudah dimodelkan sebagai graph daripada sebagai tumpukan dokumen.
Contoh lain di compliance review. Agent perlu menilai apakah transaksi, vendor, kontrak, dan policy tertentu saling terkait dengan kategori risiko tertentu. Jika relasi ini tidak eksplisit, agent akan kesulitan melakukan reasoning yang konsisten.
Banyak organisasi menghindari knowledge graph karena membayangkan proyek enterprise-wide yang besar, mahal, dan lama. Itu tidak perlu. Pendekatan yang lebih realistis adalah mulai dari domain graph untuk use case prioritas. Graph untuk relasi vendor–kontrak–kategori–policy di procurement, graph untuk customer–product–ticket–SLA di customer service, atau graph untuk entity–account–journal–control di finance close.
Pendekatan domain-first memberi tiga keuntungan: lebih cepat menghasilkan nilai, lebih mudah divalidasi oleh business owner, dan lebih mudah di-govern daripada mencoba memetakan seluruh perusahaan sekaligus.
Graph sangat berguna, tetapi tidak selalu perlu. Graph biasanya layak ketika relasi antar-entitas benar-benar memengaruhi keputusan, workflow bersifat lintas domain, dan reasoning tidak cukup jika hanya mengandalkan dokumen. Graph mungkin belum layak jika use case masih sederhana dan berbasis dokumen, entitas bisnis belum stabil, atau organisasi belum punya ownership data yang cukup jelas.
Enterprise Memory: Mengingat Tanpa Menyimpan Kekeliruan sebagai Kebenaran
Komponen ketiga dari context layer adalah memory. Memory memungkinkan agent mengingat konteks yang tidak selalu tersedia di satu prompt atau satu query. Ini penting karena banyak pekerjaan enterprise berlangsung lintas langkah, lintas hari, bahkan lintas tim.
Namun memory di enterprise harus dipahami dengan disiplin. Bukan semua hal perlu diingat, dan tidak semua ingatan boleh diperlakukan sama.
Ada empat jenis memory yang perlu dibedakan. Pertama, session memory: konteks percakapan atau interaksi dalam satu sesi. Misalnya agent masih ingat bahwa user sedang membahas invoice tertentu. Session memory berguna untuk menjaga percakapan tetap koheren, tetapi biasanya tidak perlu disimpan lama.
Kedua, workflow memory: memori tentang status pekerjaan yang sedang berjalan. Langkah apa yang sudah dilakukan, dokumen apa yang sudah diperiksa, keputusan apa yang sudah diambil, siapa yang sudah memberi approval, dan exception apa yang masih terbuka. Ini sangat penting untuk workflow seperti finance close, procurement case management, atau incident response.
Ketiga, user memory: preferensi atau konteks spesifik pengguna, misalnya format laporan yang disukai atau pola kerja tertentu. User memory bisa meningkatkan pengalaman, tetapi harus dikelola hati-hati karena menyentuh privasi dan fairness.
Keempat, institutional memory: pembelajaran organisasi yang lebih tahan lama. Pola exception yang sering terjadi, treatment yang pernah berhasil, feedback manusia terhadap rekomendasi agent, dan pengetahuan operasional yang berulang. Institutional memory paling bernilai untuk continuous improvement, tetapi juga paling berisiko jika tidak dikurasi.
Tanpa memory, agent cenderung bekerja seperti amnesia operasional. Setiap kali kasus dibuka, agent harus mulai dari nol. Handoff antar-sesi buruk, keputusan sebelumnya tidak dipertimbangkan, feedback manusia hilang, dan workflow panjang menjadi rapuh.
Di IT operations, agent yang menangani insiden berulang seharusnya bisa mengingat runbook mana yang pernah berhasil, siapa approver yang relevan, dan dependency sistem apa yang sering menjadi akar masalah. Di collections, agent seharusnya mengingat promise-to-pay sebelumnya, respons pelanggan, dan tindakan follow-up yang sudah dilakukan agar tidak mengirim komunikasi yang kontradiktif.
Di enterprise, memory tidak boleh diperlakukan seperti catatan bebas tanpa aturan. Ada empat disiplin minimum. Retention: harus jelas apa yang disimpan, berapa lama, dan kapan dihapus. Privacy: memory bisa berisi data sensitif, sehingga penyimpanan dan penggunaannya harus tunduk pada kebijakan privasi dan akses yang ketat. Audit: perusahaan harus bisa menjelaskan memory apa yang dipakai agent untuk menghasilkan rekomendasi atau tindakan tertentu. Correction: memory harus punya mekanisme koreksi. Jika agent menyimpan kesimpulan yang salah, feedback manusia harus bisa memperbaiki atau menandai memori itu.
Memory belum layak di-scale jika organisasi belum jelas membedakan jenis memory, tidak ada retention policy, feedback manusia tidak masuk ke mekanisme koreksi, atau agent menyimpan terlalu banyak konteks tanpa klasifikasi.
Menyatukan RAG, Graph, dan Memory dalam Satu Context Layer
Ketiga komponen ini tidak saling menggantikan. Mereka saling melengkapi. RAG membantu agent mengambil knowledge yang relevan dari dokumen dan corpus enterprise. Knowledge graph membantu agent memahami relasi antar-entitas bisnis. Memory membantu agent menjaga kesinambungan konteks lintas sesi, workflow, dan pembelajaran operasional.
Dalam workflow enterprise yang matang, ketiganya sering bekerja bersama. Di procurement exception, RAG mengambil policy pembelian dan klausul kontrak yang relevan, graph menunjukkan relasi antara requester, kategori, supplier, kontrak, dan approval path, memory mengingat bahwa kasus serupa sebelumnya pernah ditolak karena dokumen tertentu tidak lengkap. Di finance close, RAG mengambil accounting guidance dan SOP close, graph memetakan relasi antara entitas, akun, jurnal, dan kontrol, memory menyimpan histori exception dan keputusan controller sebelumnya.
Di sinilah context layer benar-benar menjadi lapisan eksekusi, bukan sekadar lapisan pencarian.
Implikasi Praktis
Context layer bukan proyek teknologi yang bisa diselesaikan dalam seminggu. Ia adalah keputusan arsitektur yang menentukan apakah agent bisa dipercaya untuk mengambil keputusan operasional.
Untuk CIO, pertanyaannya adalah apakah perusahaan sudah punya context layer yang bisa di-govern, atau masih mengandalkan prompt engineering dan retrieval ad hoc. Untuk COO, pada workflow prioritas, konteks apa yang benar-benar dibutuhkan agent untuk mengambil keputusan yang relevan dan aman. Untuk CHRO, jika agent mulai menyimpan user memory atau institutional memory, apakah kebijakan privasi, fairness, dan koreksi sudah siap. Untuk transformation leader, apakah use case agentic dibangun di atas konteks enterprise yang dapat dipercaya, atau baru di atas demo retrieval yang terlihat meyakinkan.
Jika jawaban atas pertanyaan-pertanyaan ini masih kabur, prioritas berikutnya bukan menambah agent baru. Prioritasnya adalah membangun context layer yang akurat, relevan, dan aman. Karena di situlah kepercayaan operasional terhadap agent benar-benar dibentuk.