Agentic AI FinOps: Mengelola Cost, Latency, dan Capacity
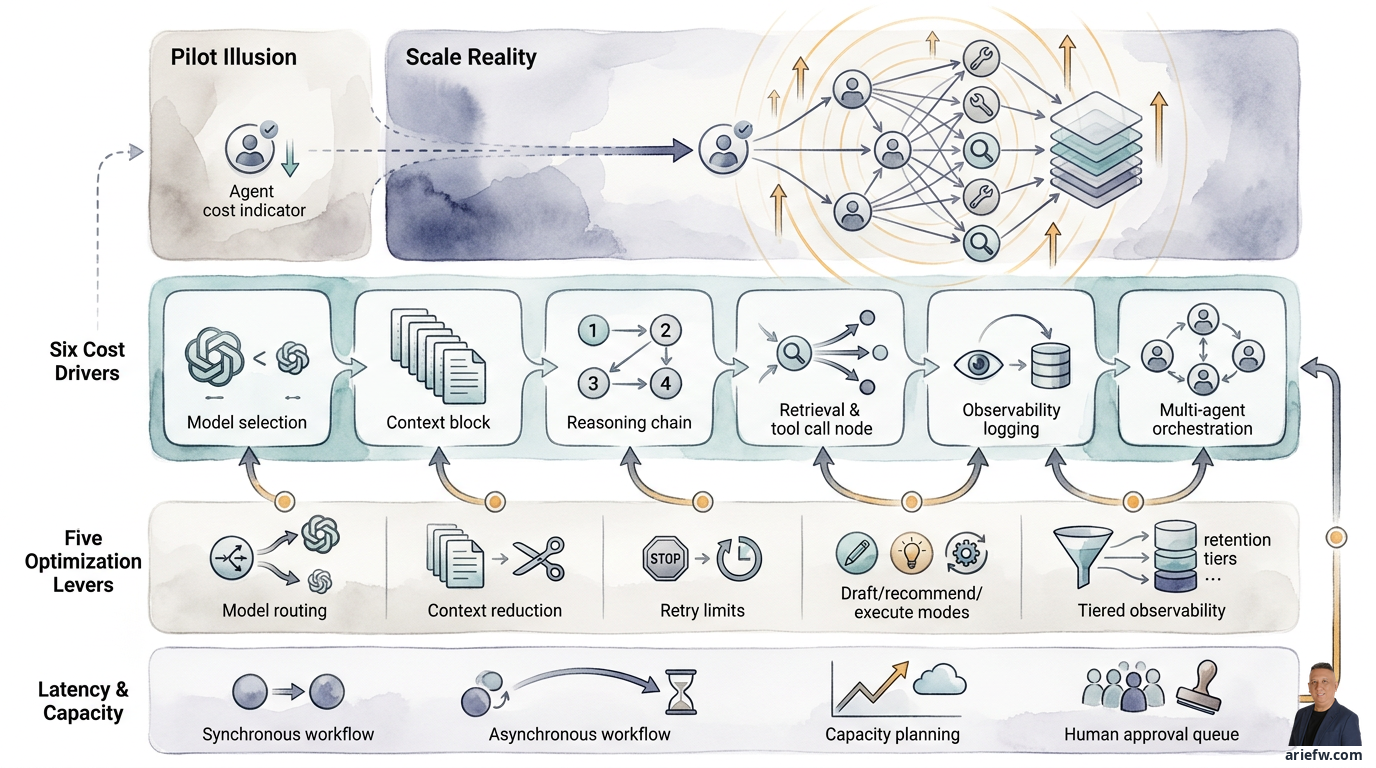
Seorang manajer shared services melihat pilot agent untuk AP exception handling berjalan mulus. Biaya per transaksi di dashboard terlihat kecil, latency masih wajar, dan tim senang karena beban kerja berkurang. Enam bulan kemudian, saat volume naik sepuluh kali lipat, tagihan cloud membengkak, pengguna mulai mengeluh lambat, dan tim IT kebingungan mengejar kapasitas. Apa yang terjadi?
Pilot yang tampak murah sering menyembunyikan biaya sesungguhnya. Agentic workflow bukan satu panggilan model sederhana. Ia bisa melibatkan beberapa langkah reasoning, retrieval ke knowledge layer, pemanggilan tool ke sistem enterprise, retries, evaluasi, logging, dan kadang koordinasi beberapa agent sekaligus. Saat pola ini dibawa ke skala enterprise, economics-nya berubah total.
Di sinilah perusahaan perlu mulai berpikir tentang Agentic AI FinOps. Bukan sekadar menghemat token, tetapi mengelola tiga hal secara bersamaan: berapa biaya nyata untuk menghasilkan outcome yang berhasil, seberapa cepat agent memberi hasil yang masih layak dipakai, dan apakah platform, model, API, serta tim operasi mampu menangani volume dan lonjakan beban.
Mengapa Pilot Sering Menipu Ekonomi
Kesalahan paling umum adalah menghitung biaya agent hanya dari harga model per token atau per request. Dalam workflow enterprise, satu outcome bisa terdiri dari banyak komponen. Ambil contoh AP exception handling: agent menerima kasus, mengambil konteks dari ERP dan knowledge base, memanggil model untuk klasifikasi, memanggil tool untuk cek status invoice dan goods receipt, mungkin melakukan retry jika data tidak lengkap, lalu menyiapkan rekomendasi atau eskalasi. Secara kasat mata, setiap langkah tampak murah. Tetapi biaya sesungguhnya muncul dari akumulasi.
Hal yang sama terjadi di customer operations. Sebuah agent refund mungkin membaca histori pelanggan, mengecek entitlement, mengambil policy, menyusun rekomendasi, meminta approval untuk kasus tertentu, lalu mencatat hasil ke CRM. Jika volume kasus harian tinggi, biaya kecil per langkah akan menjadi material. Terlebih lagi jika agent sering melakukan loop, retry, atau memanggil model yang terlalu besar untuk tugas yang sebenarnya sederhana.
Pilot biasanya berjalan pada volume rendah, data yang relatif bersih, skenario yang sudah dipilih, dan pengawasan manusia yang tinggi. Dalam kondisi seperti itu, biaya tampak terkendali. Namun saat masuk production, variasi kasus meningkat, exception lebih banyak, pengguna mencoba lebih banyak pola interaksi, dan sistem sumber tidak selalu merespons dengan sempurna. Akibatnya, jumlah langkah per transaksi naik. Biaya yang tadinya terlihat kecil menjadi signifikan.
Karena itu, metrik yang lebih tepat bukan cost per prompt atau cost per token, melainkan cost per successful outcome. Yang perlu dihitung bukan hanya berapa biaya inferensi, tetapi berapa biaya untuk menghasilkan outcome yang benar-benar bernilai. Misalnya biaya per exception yang berhasil diklasifikasikan dan dirutekan dengan benar, biaya per refund low-risk yang selesai tanpa rework, atau biaya per incident yang berhasil ditriase dengan benar. Jika agent murah tetapi correction rate tinggi, escalation rate berlebihan, atau banyak kasus harus diulang, maka economics-nya sebenarnya buruk.
Enam Pendorong Biaya yang Sering Terlewat
Untuk mengelola economics dengan baik, perusahaan perlu memahami dari mana biaya benar-benar datang. Dalam agentic systems, ada enam pendorong utama.
Pertama, pemilihan model. Model yang lebih kuat biasanya lebih mahal dan sering lebih lambat. Masalahnya, banyak tim memakai model terbaik untuk semua langkah, termasuk tugas yang sebenarnya ringan seperti klasifikasi intent, ekstraksi field, routing sederhana, atau validasi format. Untuk procurement intake, misalnya, klasifikasi kategori belanja awal mungkin cukup ditangani model yang lebih kecil. Model yang lebih kuat baru dipakai jika kasus ambigu, melibatkan kontrak non-standar, atau menyentuh keputusan berisiko lebih tinggi.
Kedua, panjang konteks. Context length adalah pembunuh biaya yang sering tidak terlihat. Semakin banyak dokumen, transcript, histori, dan metadata yang dimasukkan ke prompt, semakin mahal dan lambat inferensinya. Masalah ini sering muncul ketika organisasi belum disiplin membangun retrieval yang presisi. Akibatnya, agent diberi terlalu banyak konteks untuk berjaga-jaga. Biaya naik, latency memburuk, dan kualitas belum tentu lebih baik karena model justru tenggelam dalam noise.
Ketiga, jumlah langkah reasoning. Agentic workflow yang multi-step memang berguna untuk tugas kompleks. Tetapi setiap langkah reasoning tambahan berarti biaya tambahan. Jika tidak dikendalikan, agent bisa menjadi terlalu rajin berpikir untuk masalah yang sebenarnya sederhana. Di IT operations, untuk incident enrichment dasar, agent tidak perlu menjalankan reasoning panjang. Jika semua insiden diperlakukan seperti investigasi kompleks, biaya dan latency akan melonjak tanpa nilai tambahan yang sepadan.
Keempat, retrieval calls dan tool calls. Setiap retrieval ke vector store, knowledge graph, atau data product punya biaya komputasi dan latency. Setiap tool call ke ERP, CRM, HRIS, atau ITSM juga punya biaya, baik langsung maupun tidak langsung: konsumsi API, beban middleware, pemrosesan event, dan kadang biaya lisensi atau platform. Dalam enterprise, tool call sering lebih mahal secara operasional daripada yang terlihat di level aplikasi AI.
Kelima, frekuensi evaluasi dan observability. Logging, tracing, audit storage, dan evaluasi pasca-produksi juga punya biaya: storage untuk transcript dan trace, pemrosesan telemetry, dashboard dan alerting, sampling review, regression testing berkala. Semakin matang governance, semakin besar pula biaya kontrol. Ini bukan alasan untuk mengurangi observability, tetapi alasan untuk memasukkannya ke model biaya sejak awal.
Keenam, multi-agent orchestration. Arsitektur multi-agent bisa meningkatkan modularitas, tetapi juga bisa memperburuk economics. Jika satu request harus melewati orchestrator, lalu dua atau tiga task agent, maka biaya per outcome naik cepat. Pola ini layak jika memang memberi kualitas atau kontrol yang lebih baik. Tetapi untuk use case sederhana, multi-agent sering menjadi kemewahan arsitektural yang tidak ekonomis.
Lima Lever Optimasi Tanpa Merusak Outcome
FinOps yang sehat bukan berarti selalu memilih opsi termurah. Tujuannya adalah menemukan kombinasi biaya, kualitas, dan risiko yang paling masuk akal untuk use case tertentu.
Model routing adalah leverage paling penting. Gunakan model kecil untuk tugas sederhana dan model lebih kuat hanya untuk reasoning kompleks, kasus ambigu, keputusan high-risk, atau synthesis lintas banyak sumber. Di finance close, misalnya, model ringan untuk ekstraksi variance driver dari data terstruktur, model lebih kuat untuk menyusun draft commentary yang menggabungkan angka, policy, dan narasi bisnis. Trade-off-nya jelas: routing menambah kompleksitas arsitektur dan evaluasi. Tetapi tanpa routing, biaya akan cepat tidak terkendali.
Kurangi context bloat. Banyak biaya agentic AI sebenarnya adalah biaya konteks yang berlebihan. Tiga teknik paling praktis: retrieval yang lebih presisi, summarization sebelum reasoning utama, dan caching konteks yang sering dipakai. Di customer operations, agent tidak perlu selalu membawa seluruh histori pelanggan ke prompt. Cukup ringkasan yang relevan untuk kasus aktif, ditambah akses on-demand jika perlu detail tambahan. Namun summarization dan caching juga punya risiko. Ringkasan bisa menghilangkan nuansa penting, dan cache bisa menjadi basi. Teknik ini lebih cocok untuk domain dengan pola informasi yang relatif stabil dan risiko rendah sampai menengah.
Batasi retries dan loop. Agent yang terus mencoba sampai berhasil adalah resep biaya meledak. Setiap workflow perlu punya stopping criteria yang eksplisit, batas retry, batas jumlah tool call, dan kondisi eskalasi ke manusia. Di shared services, jika data invoice tetap tidak lengkap setelah satu atau dua percobaan validasi, agent seharusnya berhenti dan membuka case manual, bukan terus memanggil model dan tool yang sama.
Bedakan mode draft, recommend, dan execute. Tidak semua use case perlu reasoning mendalam di setiap langkah. Untuk banyak proses, agent cukup menyiapkan draft, memberi rekomendasi, atau melakukan pre-processing sebelum manusia mengambil keputusan. Ini sering lebih ekonomis daripada memaksa agent menyelesaikan seluruh workflow secara otonom. Terutama pada fase awal scale-up, mode draft sering memberi economics yang lebih sehat sambil menjaga trust.
Optimalkan observability, bukan mematikannya. Logging penuh untuk semua interaksi bisa mahal. Tetapi mematikan observability demi hemat biaya adalah keputusan buruk. Pendekatan yang lebih sehat: logging penuh untuk high-risk workflow, sampling atau ringkasan untuk low-risk workflow, retention policy yang berbeda menurut risk tier, dan pemisahan antara audit log wajib dan debug log sementara. Dengan begitu, perusahaan tetap punya akuntabilitas tanpa membiarkan biaya telemetry tumbuh liar.
Latency: Akurat Saja Tidak Cukup
Banyak tim terlalu fokus pada kualitas jawaban dan lupa bahwa agent yang terlalu lambat tidak akan dipakai. Dalam enterprise, latency memengaruhi adopsi pengguna, SLA proses, produktivitas tim, dan persepsi trust terhadap agent. Sebuah agent customer service yang sangat akurat tetapi lambat akan membuat agen manusia kembali ke cara lama. Sebuah agent procurement yang butuh terlalu lama untuk memberi intake recommendation akan dianggap menghambat proses.
Keputusan desain yang paling penting adalah membedakan synchronous dan asynchronous workflow. Mode synchronous cocok untuk interaksi yang membutuhkan respons cepat di depan pengguna, seperti tanya jawab internal, klasifikasi awal, draft singkat, atau rekomendasi sederhana. Untuk mode ini, workflow harus ringan: konteks terbatas, tool call minimum, dan fallback jelas jika proses terlalu lama.
Mode asynchronous cocok untuk pekerjaan yang memang lebih berat, seperti analisis exception kompleks, penyusunan laporan, investigasi insiden, rekonsiliasi multi-sumber, atau batch processing di shared services. Untuk mode ini, pengguna tidak perlu menunggu di layar. Yang lebih penting adalah status yang jelas, notifikasi saat selesai, dan hasil yang bisa ditinjau.
Banyak masalah latency muncul karena organisasi memaksa workflow yang seharusnya asynchronous menjadi synchronous demi pengalaman chat-like. Jika workflow memang butuh waktu, UX harus jujur dan membantu. Sistem perlu memberi status progress, indikasi langkah yang sedang berjalan, intermediate result jika memungkinkan, dan fallback jika proses gagal atau terlalu lama. Di finance close, agent yang sedang mengumpulkan evidence dan menyusun commentary sebaiknya memberi status seperti "mengambil data variance", "memeriksa policy terkait", lalu "menyiapkan draft". Ini jauh lebih baik daripada layar diam yang membuat pengguna mengira sistem macet.
Capacity: Jangan Tunggu Sampai Bottleneck Terjadi
Selain biaya dan latency, FinOps agentic AI juga harus memikirkan capacity. Pertanyaannya bukan hanya berapa biaya per transaksi, tetapi juga apakah model gateway mampu menangani lonjakan beban, apakah API core systems sanggup menerima tool call tambahan, apakah vector store dan retrieval layer tetap responsif, dan apakah approval queue manusia menjadi bottleneck.
Di month-end finance close atau peak season customer operations, volume bisa melonjak pada waktu tertentu. Jika capacity planning tidak dilakukan, perusahaan akan melihat latency naik tajam, timeout meningkat, retry bertambah, biaya ikut melonjak, dan pengalaman pengguna memburuk. Capacity planning untuk agentic systems harus mencakup seluruh rantai: model inference, retrieval, integration layer, workflow engine, dan human approval capacity.
Siapa yang Bertanggung Jawab atas Ekonomi Ini?
FinOps agentic AI tidak akan jalan jika dianggap sekadar dashboard teknis. Setiap agent production seharusnya memiliki business owner, technical owner, budget atau spending envelope, cost alert, usage analytics, dan target outcome yang jelas. Tanpa owner yang jelas, biaya akan menjadi "biaya platform bersama" yang tidak pernah benar-benar dipertanggungjawabkan.
Review portofolio agent tidak boleh berhenti pada volume penggunaan. Yang perlu dibandingkan adalah biaya total, cost per successful outcome, latency, correction rate, escalation rate, dan nilai bisnis yang terbukti. Agent yang populer belum tentu ekonomis. Sebaliknya, agent dengan volume sedang bisa sangat bernilai jika outcome-nya kuat dan biaya per hasilnya sehat.
Ada beberapa sinyal bahwa sebuah agent belum layak diperluas: biaya per successful outcome terlalu tinggi, latency membuat pengguna kembali ke proses manual, retry dan loop terlalu sering, observability menunjukkan tool call berlebihan, approval queue menjadi bottleneck, atau nilai bisnis belum terbukti cukup untuk menutup biaya operasi dan oversight. Dalam kondisi seperti ini, jawaban yang benar bukan selalu "optimalkan model". Kadang jawabannya adalah sederhanakan workflow, turunkan tingkat otonomi, ubah UX menjadi asynchronous, atau hentikan use case tersebut.
Pada akhirnya, FinOps untuk agentic AI bukan soal menekan biaya serendah mungkin. Tujuannya adalah memastikan perusahaan bisa menskalakan agent tanpa merusak economics, pengalaman pengguna, dan kontrol operasional. Di enterprise, itu adalah syarat agar agentic transformation benar-benar bisa bertahan, bukan hanya terlihat impresif di fase pilot.