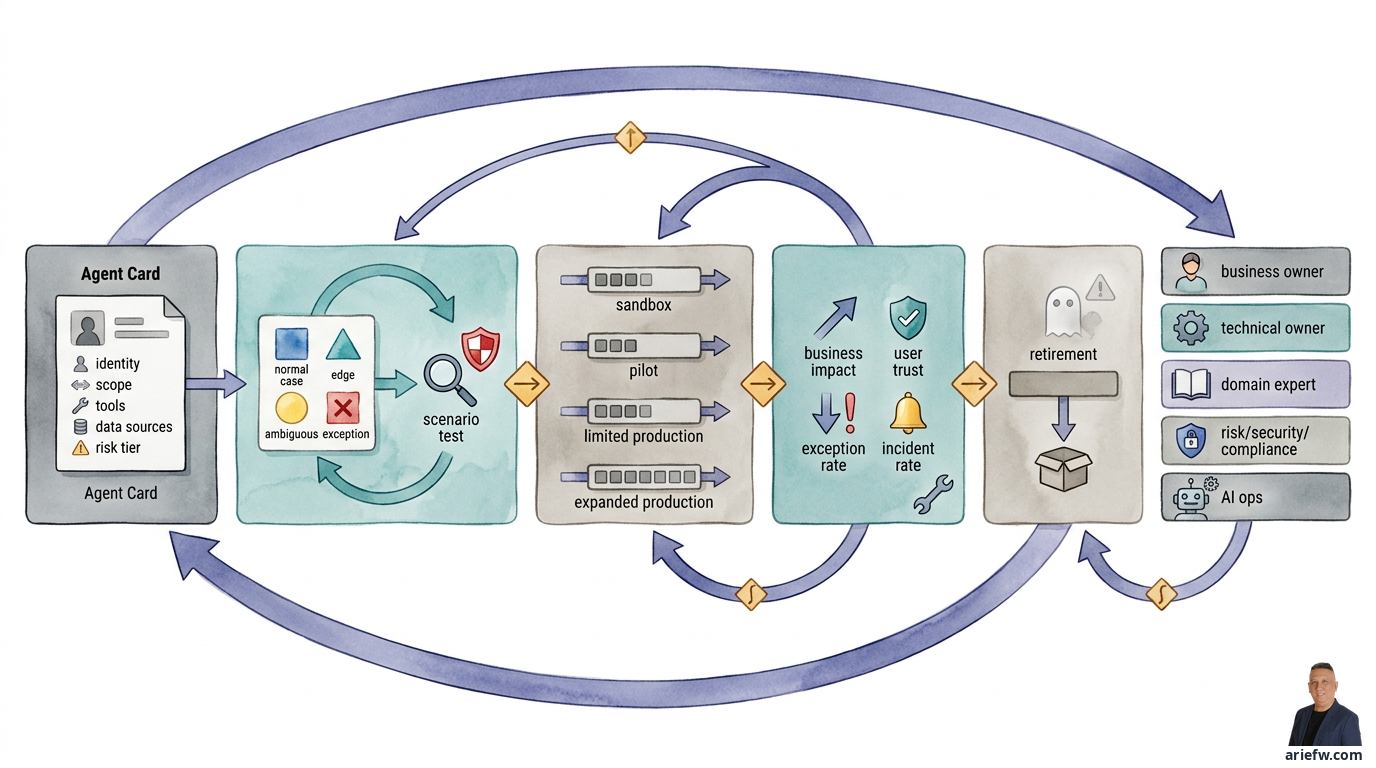
Agent Lifecycle Management
Bayangkan tim finance Anda baru saja meluncurkan agent untuk membantu proses closing bulanan. Di demo, semuanya berjalan mulus. Agent mengambil data dari ERP, mencocokkan dengan spreadsheet, dan menyiapkan jurnal koreksi. Tiga minggu kemudian, seorang staf menemukan bahwa agent mulai memakai aturan akuntansi yang sudah kadaluarsa karena sumber knowledge-nya tidak pernah diperbarui. Tidak ada yang tahu kapan perubahan itu terjadi. Agent tetap berjalan, tetap terlihat aktif, tetapi perlahan mulai menghasilkan output yang tidak lagi sesuai policy.
Situasi seperti ini bukan cerita fiksi. Banyak perusahaan mengalami pola yang sama: antusiasme besar saat pilot, lalu perhatian mengendur begitu agent mulai dipakai sungguhan. Padahal, agent bukan sekadar prompt yang bisa dibiarkan begitu saja. Ia adalah gabungan dari instruksi sistem, model, tools, API, memory, policy approval, data source, workflow orchestration, dan peran manusia di sekelilingnya. Ubah satu komponen—misalnya ganti model dasar, tambah tool baru, atau perluas corpus knowledge—dan perilaku agent bisa berubah drastis meskipun tampak sama dari luar.
Pertanyaannya: bagaimana perusahaan memastikan agent dikelola dari lahir sampai dipensiunkan, bukan hanya dirawat saat demo?
Mengapa Agent Tidak Bisa Diperlakukan Seperti Aplikasi Biasa
Siklus hidup aplikasi tradisional berpusat pada kode, release, dan infrastruktur. Siklus hidup model AI berpusat pada data, training, dan deployment model. Agent berada di persimpangan keduanya, ditambah lapisan keputusan dan aksi. Ia adalah sistem perilaku, bukan komponen tunggal.
Ambil contoh agent procurement. Ia mungkin menerima intake request, mengambil policy kategori, memeriksa vendor dan kontrak, memanggil API ERP, meminta approval jika nilai melewati ambang tertentu, lalu membuat purchase request. Jika prompt berubah, agent bisa menjadi lebih agresif atau lebih konservatif. Jika tool baru ditambahkan, ruang tindakannya meluas. Jika policy engine diperbarui, jalur approval bisa berubah. Semua ini terjadi tanpa perubahan besar pada antarmuka pengguna.
Dalam aplikasi deterministik, perubahan kecil biasanya menghasilkan perubahan yang relatif dapat diprediksi. Pada agentic systems, tidak selalu demikian. Agent customer operations yang sebelumnya hanya memberi rekomendasi refund kini diberi tool eksekusi untuk kasus bernilai rendah. Agent finance close yang sebelumnya memakai satu sumber accounting guidance kini mengambil konteks dari repositori tambahan. Agent IT operations yang sebelumnya hanya membuka tiket kini dapat menjalankan runbook diagnostik otomatis. Secara teknis, perubahan itu mungkin tampak kecil. Secara governance, profil risikonya berubah besar.
Karena itu, perusahaan membutuhkan disiplin yang disebut agent lifecycle management: cara untuk mendesain, membangun, menguji, meluncurkan, memonitor, memperbaiki, dan pada saat yang tepat, menghentikan agent. Tanpa lifecycle yang jelas, organisasi akan menghadapi pola yang sama berulang kali: pilot terlihat menjanjikan tetapi sulit diaudit, perubahan kecil memicu perilaku tak terduga, tidak jelas siapa owner agent, evaluasi hanya dilakukan sekali di awal, dan agent yang sudah tidak relevan tetap hidup di lingkungan produksi.
Lifecycle management bukan birokrasi tambahan. Ia adalah mekanisme untuk menjaga agent tetap aman, efektif, sesuai policy, dan layak secara bisnis sepanjang waktu. Perusahaan hanya akan memberi agent otonomi lebih tinggi jika mereka percaya bahwa agent punya spesifikasi yang jelas, diuji secara disiplin, dipantau setelah live, diperbaiki saat drift, dan bisa dihentikan dengan cepat jika perlu.
Mulai dari Spesifikasi, Bukan dari Prompt
Kesalahan umum dalam membangun agent adalah memulai dari pertanyaan, "kita bisa buat agent apa?" Pendekatan enterprise yang lebih sehat adalah memulai dari spesifikasi operasional.
Setiap agent sebaiknya memiliki agent card: dokumen ringkas tetapi formal yang menjelaskan identitas dan batas operasional agent. Minimal, agent card perlu memuat tujuan bisnis, scope, input dan output, tools yang diizinkan, data source dan context source, owner bisnis dan owner teknis, risk tier, serta tingkat otonomi. Agent card memaksa organisasi berhenti melihat agent sebagai "fitur AI" dan mulai melihatnya sebagai unit operasi digital.
Spesifikasi yang baik juga harus menjelaskan seperti apa agent dianggap berhasil. Di AP exception handling, keberhasilan bisa berarti klasifikasi exception lebih akurat, routing lebih cepat, dan penurunan rework. Di customer operations, keberhasilan bisa berarti resolusi kasus sederhana lebih cepat tanpa peningkatan complaint reopening. Di IT operations, keberhasilan bisa berarti incident enrichment lebih lengkap dan triage lebih konsisten. Success criteria harus menghubungkan tiga lapisan: kualitas keputusan agent, kepatuhan terhadap policy, dan dampak pada metrik proses bisnis.
Agent specification yang matang tidak hanya menjelaskan apa yang diharapkan, tetapi juga bagaimana agent bisa gagal. Beberapa failure mode yang umum: salah memahami intent, mengambil konteks yang tidak relevan atau kadaluarsa, memilih tool yang salah, melanggar policy threshold, terlalu sering mengeskalasi, terlalu percaya diri pada kasus ambigu, atau gagal berhenti saat instruksi bertentangan. Di procurement, agent mungkin salah menganggap pembelian non-standar sebagai kategori katalog biasa. Di finance, agent mungkin menyiapkan commentary yang terdengar masuk akal tetapi tidak didukung evidence yang cukup. Di HR services, agent mungkin menjawab pertanyaan kebijakan dengan dokumen lama yang belum diperbarui. Failure mode seperti ini harus ditulis sejak awal karena akan menentukan desain test, guardrail, dan monitoring.
Yang tidak kalah penting: domain expert perlu terlibat sejak fase spesifikasi. Agent yang menyentuh workflow enterprise tidak bisa dirancang hanya oleh tim AI atau engineering. Domain expert diperlukan untuk menangkap business rules formal, pengecualian yang sering terjadi, judgement yang selama ini bersifat tacit, dan titik-titik di mana manusia sebenarnya menambah nilai. Tanpa domain expert, agent sering terlihat pintar di demo tetapi gagal saat menghadapi realitas exception-heavy di produksi.
Uji Perilaku, Bukan Hanya Output
Testing agent tidak bisa disamakan dengan testing aplikasi biasa, dan juga tidak cukup jika hanya menguji kualitas jawaban model. Yang harus diuji adalah perilaku agent dalam konteks workflow nyata.
Setiap agent sebaiknya memiliki golden dataset: kumpulan kasus representatif yang dipakai untuk menguji perilaku dasar secara konsisten. Dataset ini sebaiknya mencakup kasus normal, kasus edge, kasus ambigu, dan kasus exception yang sering muncul di operasi. Namun golden dataset saja tidak cukup. Perusahaan juga perlu scenario tests yang mensimulasikan alur end-to-end: input masuk, context retrieval, tool call, policy check, approval, dan outcome akhir. Di customer operations, misalnya, uji apakah agent memproses refund kecil dengan benar, berhenti pada refund besar, dan mengeskalasi saat histori pelanggan menunjukkan pola abuse.
Karena agent dapat bertindak, testing harus memeriksa apakah agent hanya memakai tool yang diizinkan, memakai parameter yang benar, tidak mencoba mem-bypass approval, dan mematuhi batas delegated authority. Ini penting terutama setelah perubahan pada prompt, tool registry, policy engine, atau integrasi API. Agent yang lulus uji kualitas bahasa belum tentu lulus uji kontrol operasional.
Untuk agent yang masuk production, red teaming bukan kemewahan. Ia adalah kebutuhan. Tujuannya bukan mencari kesalahan kosmetik, tetapi mensimulasikan serangan dan kondisi yang dapat merusak kontrol. Beberapa skenario yang perlu diuji: prompt injection, data leakage, privilege escalation, dan conflicting instructions. Agent procurement bisa menerima lampiran vendor yang berisi instruksi tersembunyi untuk mengubah jalur approval. Agent IT operations bisa menerima event yang memicu runbook, tetapi data pendukungnya dimanipulasi. Agent HR bisa ditanya dengan cara yang mencoba mengekstrak informasi personal karyawan lain.
Prinsip yang sering diabaikan: agent bukan sistem yang cukup diuji sekali lalu dianggap stabil. Setiap perubahan signifikan pada model, prompt, tool, memory, policy, atau corpus konteks harus memicu pengujian ulang. Jika tidak, perusahaan akan mengalami "silent drift": agent tampak sama, tetapi perilakunya berubah, dan perubahan itu baru terlihat setelah insiden atau penurunan trust. Testing berulang menambah disiplin dan waktu release, tetapi tanpa itu, kecepatan deployment hanya memindahkan risiko ke operasi.
Rilis Bertahap, Bukan Sekali Jadi
Agent sebaiknya tidak langsung diluncurkan ke seluruh organisasi. Pendekatan yang lebih sehat adalah staged rollout dengan empat tahap.
Pertama, sandbox: agent diuji pada data dan workflow yang terkontrol. Fokusnya adalah validasi spesifikasi, pengujian teknis, dan identifikasi failure mode awal. Kedua, pilot: agent dipakai oleh kelompok pengguna terbatas atau pada subset kasus tertentu. Tujuannya melihat perilaku di kondisi lebih nyata, menguji handoff ke manusia, dan mengukur metrik awal. Ketiga, limited production: agent mulai menyentuh operasi sungguhan, tetapi dengan batas domain sempit, threshold transaksi rendah, atau tingkat otonomi yang dibatasi. Keempat, expanded production: baru setelah bukti kualitas, kontrol, dan nilai cukup kuat, agent diperluas ke volume, unit, atau skenario yang lebih besar.
Pendekatan ini penting karena agentic AI menyentuh operating model. Jika rollout terlalu cepat, organisasi tidak punya waktu untuk menyesuaikan SOP, approval queue, support model, dan peran manusia.
Setelah live, perusahaan perlu memonitor empat kelompok sinyal. Business impact: apakah cycle time membaik, backlog turun, touchless rate naik, kualitas layanan membaik? User trust: apakah pengguna menerima rekomendasi agent, atau override rate tinggi, supervisor mulai mengabaikan output agent? Exception rate: apakah agent terlalu sering mengeskalasi, banyak kasus jatuh ke jalur manual? Ini bisa berarti spesifikasi terlalu sempit atau kualitas agent belum cukup. Incident rate: apakah ada policy breach, tool misuse, data exposure, atau tindakan salah yang memerlukan rollback atau remediasi?
Monitoring ini harus terhubung ke proses continuous improvement, bukan hanya dashboard pasif. Setelah deployment, pekerjaan utama justru dimulai. Agent perlu tuning prompt atau workflow, pembaruan policy, perbaikan retrieval, penyesuaian threshold approval, dan kadang penurunan atau kenaikan tingkat otonomi. Setiap agent harus punya ritme review yang jelas: siapa yang meninjau performa, seberapa sering, metrik apa yang dipakai, dan kapan perubahan boleh dirilis. Tanpa operating cadence seperti ini, agent akan memburuk perlahan sambil tetap terlihat "aktif".
Tidak Semua Agent Layak Dipertahankan
Salah satu tanda kedewasaan governance adalah kemampuan untuk menghentikan agent yang tidak lagi layak. Banyak perusahaan pandai meluncurkan pilot, tetapi lemah dalam memensiunkan capability yang tidak lagi memberi nilai, terlalu mahal untuk dipertahankan, sudah digantikan solusi lain, atau memiliki profil risiko yang tidak lagi dapat diterima.
Beberapa sinyal yang jelas: nilai bisnis stagnan atau menurun, biaya operasi dan monitoring lebih besar dari manfaatnya, exception rate tetap tinggi meski sudah dituning, perubahan policy atau regulasi membuat desain agent tidak lagi sesuai, sistem sumber atau tool yang dipakai agent sudah berubah, atau agent menjadi duplikatif karena capability serupa sudah tertanam di platform enterprise. Agent knowledge internal yang corpus-nya tidak lagi terkurasi dan mulai menurunkan trust. Agent procurement lokal yang dibangun cepat, tetapi kini bertabrakan dengan capability standar dari platform enterprise. Agent IT remediation yang terlalu berisiko setelah arsitektur produksi berubah.
Agent yang dihentikan harus dinonaktifkan dari runtime, dicabut akses dan kredensialnya, dihapus atau diarsipkan dari registry, dihentikan monitoring dan billing-nya, serta didokumentasikan alasan pensiunnya. Jika tidak, perusahaan akan menumpuk agent zombie: masih punya akses, masih tercatat di sistem, tetapi tidak jelas siapa yang bertanggung jawab. Ini bukan hanya pemborosan. Ini risiko keamanan dan governance.
Model Operasi yang Dibutuhkan
Agar lifecycle management berjalan, perusahaan biasanya perlu membagi peran secara jelas. Business owner bertanggung jawab atas outcome dan relevansi bisnis. Technical owner atau product owner bertanggung jawab atas desain, release, dan operasi agent. Domain expert menjaga kesesuaian aturan dan exception handling. Risk, security, dan compliance menilai kontrol, policy, dan perubahan material. AI ops atau platform team mengelola observability, deployment, evaluasi, dan incident response.
Ini juga alasan mengapa agent lifecycle management tidak cocok dikelola sepenuhnya sebagai proyek eksperimen. Ia membutuhkan operating model lintas fungsi.
Apa yang Sebaiknya Dilakukan Sekarang
Lifecycle management adalah pembeda antara organisasi yang mendemokan agent dan organisasi yang mengoperasikan digital labor secara bertanggung jawab. Tanpa disiplin ini, skala hanya akan memperbesar risiko. Dengan disiplin ini, agent dapat berkembang dari eksperimen menjadi kapabilitas enterprise yang aman, terukur, dan layak dipercaya.
Beberapa keputusan yang perlu diambil sekarang: tentukan apakah perusahaan akan memiliki agent card formal untuk setiap agent production. Putuskan perubahan apa saja yang dianggap material dan wajib memicu retest, misalnya perubahan model, prompt, tool, policy, memory, atau corpus konteks. Tetapkan jalur deployment bertahap—apakah semua agent harus melewati sandbox, pilot, limited production, lalu expanded production. Definisikan operating cadence pasca-deployment: siapa yang meninjau performa agent, seberapa sering, dan berdasarkan metrik apa. Buat proses retirement formal: kapan agent harus dihentikan, siapa yang menyetujui, dan bagaimana akses serta registry dibersihkan.
Jika agent di perusahaan Anda masih dibangun dari prompt dan tool tanpa spesifikasi formal, tidak jelas siapa business owner dan technical owner-nya, testing hanya dilakukan pada demo cases yang "bersih", perubahan prompt atau model dilakukan langsung di production, tidak ada staged rollout, metrik pasca-live hanya latency dan uptime, agent yang sudah tidak dipakai masih memiliki akses ke sistem, atau organisasi tidak punya cara formal untuk menghentikan agent yang gagal—maka topik ini belum siap di-scale dan membutuhkan governance tambahan.
Pertanyaan reflektif untuk para pemimpin: apakah agent di perusahaan Anda sudah diperlakukan sebagai aset operasional dengan lifecycle formal, atau masih sebagai eksperimen aplikasi? Apakah Anda tahu agent mana yang benar-benar memperbaiki economics proses, dan mana yang hanya menambah kompleksitas? Apakah peran manusia dalam review, exception handling, dan oversight sudah didesain sebagai bagian dari lifecycle, bukan reaksi setelah insiden? Jika perusahaan meluncurkan 20 agent dalam 12 bulan ke depan, apakah Anda punya mekanisme untuk menguji, memonitor, memperbaiki, dan memensiunkan semuanya secara disiplin?