Observability untuk Agentic Systems
Bayangkan sebuah tim finance yang baru saja menempatkan agent untuk membantu proses close bulanan. Agent ini bisa mengambil data dari ERP, membaca spreadsheet yang dikirim via email, dan menyusun draft commentary untuk tiap akun. Di permukaan, semuanya berjalan lancar. Tidak ada error, tidak ada crash, tidak ada API yang timeout. Tapi setelah beberapa siklus, controller mulai menemukan anomali: ada beberapa akun yang commentary-nya menggunakan angka dari versi data yang sudah kadaluarsa. Agent tidak salah memanggil tool, tidak gagal secara teknis, tetapi keputusannya salah secara operasional.
Situasi seperti ini adalah masalah yang nyata. Begitu agent masuk ke production, pertanyaan yang muncul bukan lagi "apakah sistem berjalan?", tetapi "apa yang sebenarnya dilakukan agent, mengapa ia melakukannya, apakah hasilnya baik, dan kapan harus dihentikan?" Tanpa kemampuan menjawab pertanyaan-pertanyaan ini, perusahaan tidak punya akuntabilitas. Dan tanpa akuntabilitas, otonomi yang dibatasi akan cepat berubah menjadi risiko yang tidak terkendali.
Dalam aplikasi enterprise tradisional, observability biasanya berfokus pada kesehatan teknis: apakah service hidup, latency naik atau turun, error meningkat, database lambat, atau API gagal. Pada agentic systems, itu hanya sebagian kecil dari persoalan. Agent tidak hanya menjalankan kode deterministik. Ia menalar, memilih tool, mengambil konteks, memanggil sistem, menyimpan atau memakai memory, lalu menghasilkan output yang probabilistik. Dua eksekusi dengan input yang mirip bisa menghasilkan jalur keputusan yang berbeda. Karena itu, observability untuk agentic systems harus menjawab tiga lapisan sekaligus: apa yang terjadi secara teknis, apa yang diputuskan agent, dan apa dampaknya terhadap outcome bisnis serta kepatuhan policy.
Mengapa Observability untuk Agentic Systems Jauh Lebih Sulit
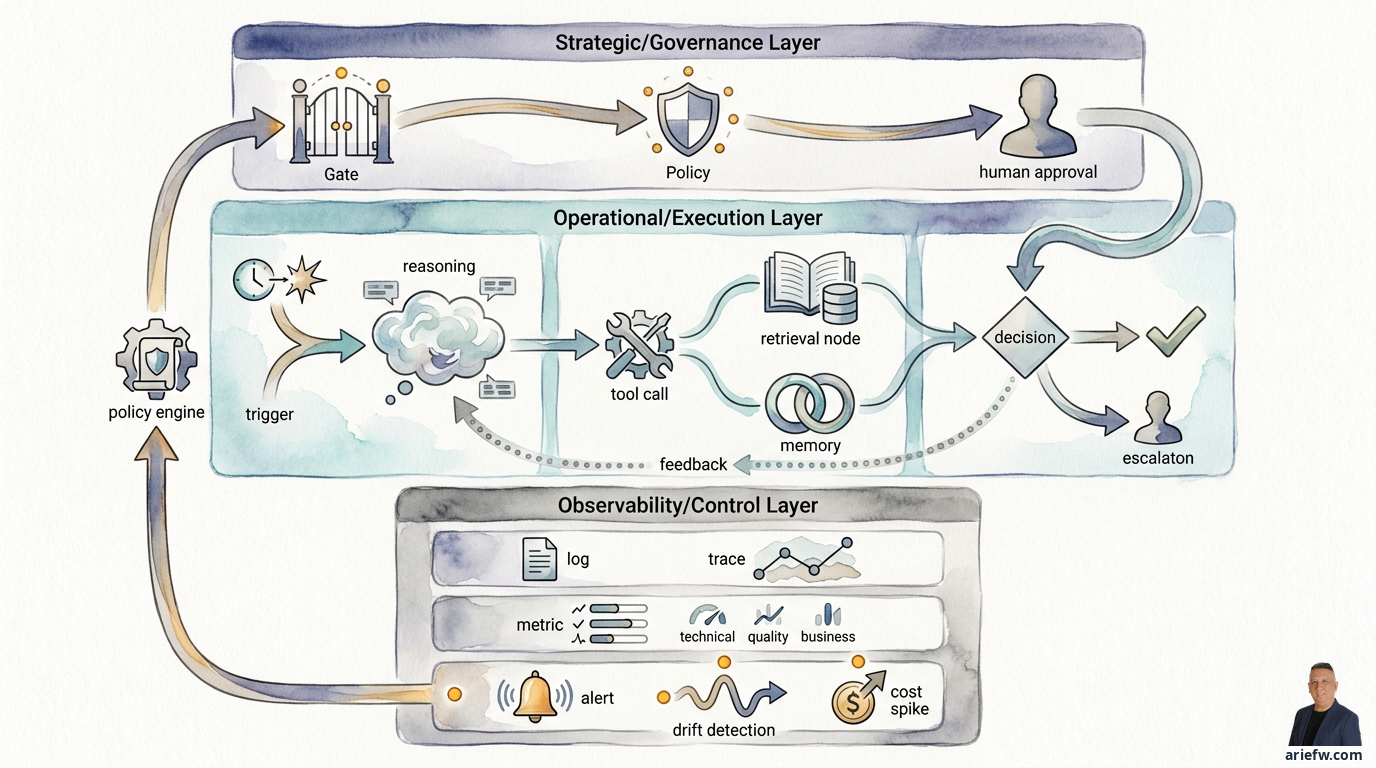
Kesulitan utama observability pada agentic systems bukan karena teknologinya lebih baru, melainkan karena objek yang diamati lebih kompleks. Pada aplikasi biasa, alur eksekusi relatif jelas. Request masuk, service memproses, database dibaca, response keluar. Jika ada masalah, tim bisa menelusuri log, metric, dan trace untuk menemukan bottleneck atau error. Pada agentic systems, alurnya bisa jauh lebih berlapis: trigger datang dari user, event, atau workflow; orchestrator memecah tugas; agent mengambil konteks dari RAG atau memory; model menghasilkan reasoning atau rencana; tool dipanggil satu per satu; policy engine mengevaluasi tindakan; manusia mungkin diminta approval; lalu agent mengeksekusi aksi atau mengeskalasi.
Masalahnya, kegagalan tidak selalu muncul sebagai error teknis. Agent bisa berhasil memanggil semua API, tetapi salah memilih tindakan. Ia bisa tidak crash, tetapi memakai konteks yang kadaluarsa. Ia bisa lolos secara teknis, tetapi melanggar policy. Ia bisa menyelesaikan task, tetapi kualitas keputusannya buruk. Atau ia bisa menghasilkan output yang terdengar meyakinkan, namun salah secara operasional. Dengan kata lain, observability agentic tidak cukup jika hanya menjawab "apakah sistem berjalan?" Ia juga harus menjawab "apakah agent bertindak dengan benar?"
Sifat probabilistik dari agentic systems mengubah cara kita memonitor. Bahkan ketika prompt, tool, dan data tampak sama, output bisa sedikit berbeda. Ini berarti perusahaan tidak bisa mengandalkan monitoring berbasis error code saja. Mereka perlu memonitor pola perilaku. Contohnya di customer operations: sebuah agent refund mungkin tidak pernah gagal secara teknis, tetapi dalam seminggu terakhir mulai lebih sering mengeskalasi kasus yang sebelumnya bisa diselesaikan otomatis. Secara infrastruktur, semua hijau. Secara operasi, ada drift perilaku yang menurunkan produktivitas. Contoh lain di procurement: agent intake-to-PO mungkin tetap berhasil membuat request, tetapi mulai lebih sering memilih jalur approval yang lebih konservatif karena retrieval policy berubah. Tidak ada incident teknis, tetapi cycle time memburuk.
Dalam konteks enterprise, observability bukan hanya alat operasi TI. Ia adalah mekanisme governance. Risk, audit, compliance, dan pemilik proses perlu bisa menjawab: konteks apa yang dipakai agent, tool apa yang dipanggil, policy apa yang diterapkan, kapan agent berhenti dan meminta approval, siapa yang mengoreksi output, dan bagaimana keputusan itu memengaruhi transaksi atau kasus bisnis. Jika perusahaan tidak bisa merekonstruksi rantai ini, maka tidak ada dasar yang kuat untuk investigasi insiden, audit, evaluasi kualitas, perbaikan model, atau peningkatan tingkat otonomi. Itulah sebabnya observability harus diperlakukan sebagai bagian dari control plane, bukan sekadar dashboard operasional.
Apa yang Harus Dilog: Dari Prompt sampai Outcome
Kesalahan paling umum adalah menganggap log agent cukup jika sudah menyimpan prompt dan response. Untuk enterprise, itu terlalu dangkal. Log yang layak untuk agentic systems harus menangkap jejak keputusan end-to-end. Bukan hanya apa yang dikatakan model, tetapi juga konteks, tindakan, dan kontrol yang mengelilinginya.
Ada enam komponen log minimum yang perlu diperhatikan. Pertama, trigger dan konteks awal. Perusahaan harus tahu bagaimana workflow dimulai: apakah dipicu user, event sistem, jadwal teratur, atau handoff dari agent lain. Log ini harus mencatat identitas principal asal, waktu, channel, dan objek bisnis yang relevan, misalnya nomor invoice, ticket ID, order ID, atau incident ID.
Kedua, prompt dan instruksi runtime. Bukan untuk menyimpan semua detail secara sembarangan, tetapi untuk memastikan perusahaan bisa memahami instruksi sistem apa yang aktif, parameter apa yang dipakai, versi prompt atau workflow mana yang berjalan, dan konfigurasi model apa yang digunakan. Ini penting saat perusahaan ingin membandingkan performa antar-versi agent atau menyelidiki perubahan perilaku.
Ketiga, retrieved context. Jika agent memakai RAG, knowledge graph, atau memory, log harus menunjukkan dokumen atau potongan konteks apa yang diambil, dari sumber mana, versi atau timestamp-nya, dan apakah aksesnya lolos permission check. Tanpa ini, sulit menjelaskan mengapa agent mengambil keputusan tertentu.
Keempat, model response dan reasoning artifact. Perusahaan tidak selalu perlu menyimpan seluruh chain-of-thought mentah. Tetapi mereka perlu menyimpan artifact yang cukup untuk audit dan debugging, misalnya ringkasan rencana tindakan, klasifikasi intent, confidence signal jika tersedia, atau structured decision output yang dipakai untuk langkah berikutnya. Prinsipnya: simpan cukup banyak untuk akuntabilitas, tetapi jangan menjadikan log sebagai tempat bocornya data sensitif atau intellectual property model.
Kelima, tool call dan hasilnya. Setiap tool call harus tercatat: tool apa yang dipanggil, parameter pentingnya, hasilnya sukses atau gagal, berapa lama latency-nya, apakah ada retry, dan perubahan state apa yang terjadi di sistem target. Untuk workflow seperti finance close, IT operations, atau procurement, inilah bagian yang paling penting karena di sinilah agent mulai memengaruhi realitas operasional.
Keenam, policy decision, human approval, dan final action. Jika ada policy engine, approval workflow, atau guardrail, semuanya harus masuk ke log: policy mana yang dievaluasi, hasilnya allow, deny, escalate, atau require approval, siapa approver manusia, apa keputusan akhirnya, dan tindakan final apa yang benar-benar dieksekusi. Tanpa lapisan ini, perusahaan hanya punya log teknis, bukan log governance.
Log yang baik belum tentu menghasilkan trace yang baik. Banyak organisasi punya log di banyak tempat, tetapi tidak bisa menyatukan alur dari awal sampai akhir. Untuk agentic systems, trace harus bisa menunjukkan perjalanan lengkap: trigger masuk, agent atau orchestrator yang aktif, konteks yang diambil, reasoning atau planning step, tool call yang dilakukan, policy check, approval manusia jika ada, final action, dan outcome bisnis. Contoh di AP exception handling: invoice mismatch masuk, agent mengambil data PO, goods receipt, dan histori vendor, agent mengklasifikasikan penyebab mismatch, agent memanggil tool untuk membuka case, policy engine memeriksa apakah kasus boleh di-auto-route, supervisor memberi approval untuk kasus tertentu, agent mengirim follow-up ke buyer, kasus ditutup atau tetap terbuka. Jika trace ini tidak utuh, tim operasi hanya melihat potongan-potongan kejadian tanpa bisa memahami sebab-akibat.
Semakin lengkap log, semakin besar pula risiko data exposure. Ini trade-off yang harus dikelola dengan disiplin. Agentic systems sering menyentuh data pelanggan, informasi payroll, detail vendor, kontrak, data keuangan, atau catatan insiden internal. Karena itu, logging harus dirancang dengan prinsip redaction untuk data sensitif yang tidak perlu disimpan mentah, tokenization atau masking untuk identifier tertentu, secure storage dengan kontrol akses ketat, retention policy yang jelas, dan segregation of duties agar tidak semua orang yang mengelola observability bisa melihat isi sensitif. Contoh di HR operations: log boleh mencatat bahwa agent mengambil policy cuti dan status onboarding, tetapi tidak semua detail personal harus tersimpan mentah di dashboard umum. Contoh di customer service: transcript mungkin perlu disimpan untuk audit terbatas, tetapi PII harus dimasking untuk penggunaan operasional sehari-hari. Prinsip pentingnya: auditability harus meningkat tanpa memperbesar blast radius data.
Metric Runtime: Bukan Hanya Teknis, tetapi Juga Kualitas dan Bisnis
Setelah logging dan tracing tersedia, langkah berikutnya adalah menentukan metric. Di sinilah banyak implementasi agentic masih terlalu sempit. Mereka hanya memonitor latency dan error rate, lalu merasa sistem sudah "observable". Padahal agentic systems perlu tiga kelompok metric yang berbeda.
Kelompok pertama adalah metric teknis untuk menjaga kesehatan runtime. Metric teknis tetap penting karena agentic systems bergantung pada model, API, retrieval, dan tool integration yang semuanya bisa gagal. Beberapa metric dasar yang perlu dipantau: latency per langkah dan end-to-end, token atau compute cost per transaksi, tool error rate, retry rate, timeout rate, fallback usage, failure mode distribution, dan availability komponen penting seperti model gateway, vector store, policy engine, atau tool registry. Contoh di IT operations: jika latency agent incident triage melonjak, SLA penanganan insiden bisa terganggu. Contoh di customer operations: jika retry rate ke CRM API naik, agent mungkin mulai gagal menyusun konteks pelanggan dengan benar. Metric teknis membantu tim platform menjaga stabilitas, tetapi mereka tidak cukup untuk menilai apakah agent masih layak dipercaya.
Kelompok kedua adalah metric kualitas untuk menilai apakah agent membuat keputusan yang baik. Inilah lapisan yang membedakan observability agentic dari observability aplikasi biasa. Metric kualitas bisa mencakup accuracy terhadap label atau outcome yang diharapkan, hallucination rate atau unsupported answer rate, escalation rate, policy violation rate, human correction rate, rework rate setelah tindakan agent, tool selection accuracy, dan grounding quality terhadap konteks yang diambil. Contoh di finance close: berapa banyak draft commentary agent yang harus dikoreksi controller, berapa banyak exception yang salah diklasifikasikan, dan berapa sering agent mengambil accounting guidance yang tidak relevan. Contoh di procurement: berapa banyak request yang dirutekan ke jalur approval yang salah, berapa banyak rekomendasi vendor yang ditolak buyer, dan berapa sering policy breach dicegah atau justru lolos. Contoh di customer operations: berapa banyak refund recommendation yang dibatalkan supervisor, berapa banyak jawaban agent yang tidak didukung entitlement pelanggan, dan berapa banyak kasus yang harus dibuka ulang. Trade-off penting di sini: beberapa metric kualitas tidak bisa diukur otomatis penuh. Perusahaan sering perlu kombinasi antara evaluasi otomatis, sampling manual, feedback pengguna, dan review domain expert.
Kelompok ketiga adalah metric bisnis untuk menilai apakah agent benar-benar memperbaiki operasi. Pada akhirnya, agentic systems dibangun bukan untuk menghasilkan trace yang indah, tetapi untuk memperbaiki outcome bisnis. Karena itu, observability harus terhubung ke metric seperti cycle time, cost per transaction, resolution rate, touchless rate, backlog reduction, revenue impact jika relevan, working capital impact untuk use case tertentu, dan customer atau employee satisfaction. Contoh di shared services: agent case management mungkin terlihat sehat secara teknis, tetapi jika cost per case tidak turun dan backlog tidak membaik, maka desainnya perlu ditinjau ulang. Contoh di GCC finance operations: agent AP exception mungkin punya accuracy tinggi, tetapi jika cycle time tidak membaik karena approval bottleneck tetap sama, maka masalahnya ada pada operating model, bukan model AI semata.
Salah satu disiplin penting adalah memisahkan metric teknis, kualitas, dan bisnis. Jika semuanya dicampur, organisasi akan sulit membaca akar masalah. Misalnya: latency naik adalah isu teknis, human correction rate naik adalah isu kualitas, cycle time tidak turun adalah isu bisnis atau desain proses. Ketiganya saling terkait, tetapi tidak boleh diperlakukan sebagai satu hal yang sama.
Monitoring dan Alerting: Mendeteksi Drift Sebelum Menjadi Insiden
Setelah metric ditentukan, perusahaan perlu memutuskan apa yang dimonitor terus-menerus dan kapan alert harus muncul. Ini lebih sulit pada agentic systems karena banyak masalah muncul sebagai pergeseran pola, bukan kegagalan total.
Ada beberapa hal yang harus dimonitor secara aktif. Pertama, drift perilaku. Agent bisa berubah perilaku meski tidak ada perubahan besar pada aplikasi. Penyebabnya bisa datang dari perubahan model, perubahan prompt, perubahan corpus retrieval, perubahan data distribusi, atau perubahan tool response. Sinyalnya bisa berupa escalation rate naik, output menjadi lebih panjang atau lebih pendek secara tidak biasa, tool tertentu dipakai jauh lebih sering, atau distribusi klasifikasi berubah tajam.
Kedua, anomali penggunaan tool. Jika agent procurement yang biasanya memanggil kontrak dan vendor API tiba-tiba lebih sering memanggil jalur exception manual, itu sinyal penting. Jika agent IT operations mulai menjalankan runbook tertentu jauh lebih sering dari baseline, itu bisa berarti ada drift, bug, atau perubahan lingkungan.
Ketiga, perubahan distribusi output. Monitoring perlu melihat pola output, bukan hanya error. Misalnya: lebih banyak jawaban "tidak tahu", lebih banyak rekomendasi konservatif, lebih banyak tindakan yang dibatalkan manusia, atau lebih banyak kasus yang berakhir tanpa resolusi. Ini sering menjadi tanda awal bahwa kualitas agent menurun.
Tidak semua alert harus diperlakukan sebagai incident teknis. Untuk agentic systems, setidaknya ada empat kategori alert. Pertama, incident teknis, misalnya model gateway down, tool API timeout, vector store gagal, latency melewati ambang batas, atau retry rate melonjak. Owner utamanya biasanya tim platform atau engineering. Kedua, policy breach, misalnya agent mencoba tindakan di luar izin, akses ke data sensitif tidak sesuai konteks, approval wajib terlewati, atau tool call ditolak berulang karena policy mismatch. Owner-nya melibatkan security, risk, dan owner proses. Ketiga, kualitas rendah, misalnya human correction rate naik tajam, unsupported answer meningkat, klasifikasi salah melonjak, atau escalation rate berubah drastis. Ini biasanya membutuhkan review bersama antara tim produk, domain owner, dan AI ops. Keempat, cost spike, misalnya token cost per transaksi naik, tool call berulang terlalu banyak, konteks retrieval terlalu besar, atau fallback ke model mahal meningkat. Ini penting karena agentic systems bisa terlihat "berfungsi", tetapi economics-nya memburuk diam-diam.
Agar lebih konkret, bayangkan dashboard untuk agent procurement intake-to-PO. Dashboard yang berguna tidak hanya menampilkan uptime. Ia sebaiknya memiliki empat panel. Panel pertama, runtime health: volume request per jam/hari, latency end-to-end, tool success/failure rate, retry rate, token cost per request. Panel kedua, decision quality: klasifikasi intake accuracy, policy violation prevented, human correction rate, escalation rate, approval override rate. Panel ketiga, business outcome: cycle time dari intake ke request creation, touchless rate, backlog request, SLA compliance, rework per request. Panel keempat, governance and audit: top denied tool calls, approval queue aging, dokumen policy paling sering dirujuk, anomali penggunaan tool, trace sample untuk investigasi. Dashboard seperti ini membantu tiga kelompok sekaligus: tim engineering melihat kesehatan runtime, pemilik proses melihat kualitas dan outcome, risk dan audit melihat kepatuhan serta jejak kontrol.
Trade-off Implementasi: Jangan Membangun "Surveillance Monster"
Meski observability sangat penting, ada jebakan lain: organisasi bisa berlebihan dan mencoba melog semuanya tanpa prioritas. Hasilnya: biaya storage membengkak, dashboard penuh noise, tim tidak tahu mana sinyal penting, dan risiko privasi meningkat. Karena itu, desain observability harus mengikuti risk tier dan criticality use case. Use case seperti knowledge assistant internal mungkin cukup dengan logging yang lebih ringan. Sebaliknya, use case seperti refund automation, finance exception handling, atau IT remediation membutuhkan trace dan audit yang jauh lebih dalam. Prinsip yang sehat: log secukupnya untuk akuntabilitas, ukur secukupnya untuk pengambilan keputusan, dan alert secukupnya agar tim benar-benar bertindak. Observability yang baik bukan yang paling banyak datanya, tetapi yang paling membantu perusahaan melihat, menjelaskan, dan mengendalikan perilaku agent.
Setelah membaca artikel ini, ada beberapa keputusan yang sebaiknya diambil. Pertama, tentukan standar trace end-to-end untuk setiap agent production. Apakah perusahaan bisa menelusuri alur dari trigger sampai outcome bisnis, termasuk context retrieval, tool call, policy decision, approval, dan final action? Kedua, pisahkan metric ke tiga lapisan: teknis, kualitas, dan bisnis. Siapa owner untuk masing-masing lapisan, dan dashboard apa yang dipakai untuk membaca hubungan di antaranya? Ketiga, tentukan kebijakan logging untuk data sensitif. Apa yang boleh disimpan mentah, apa yang harus di-redact, siapa yang boleh mengakses log, dan berapa lama retensinya? Keempat, definisikan kategori alert. Apakah perusahaan sudah membedakan incident teknis, policy breach, kualitas rendah, dan cost spike dengan jalur respons yang berbeda? Kelima, putuskan model review kualitas di production. Apakah kualitas agent akan dipantau lewat evaluasi otomatis, sampling manual, feedback manusia, atau kombinasi semuanya?
Ada beberapa sinyal bahaya bahwa observability belum siap di-scale. Agent sudah boleh bertindak, tetapi perusahaan hanya menyimpan chat log dasar. Tool call tidak terhubung ke trace yang sama dengan keputusan model. Tidak ada cara menjelaskan konteks apa yang dipakai agent saat mengambil keputusan. Semua alert masuk ke satu kanal tanpa pembedaan prioritas atau jenis insiden. Tim hanya memonitor latency dan uptime, tetapi tidak memonitor correction rate atau policy violation. Dashboard dipakai hanya oleh tim teknis, bukan oleh pemilik proses dan fungsi risk. Log terlalu kaya data sensitif tanpa redaction yang memadai. Tidak ada hubungan yang jelas antara telemetry agent dan KPI proses bisnis.
Pertanyaan reflektif untuk CIO, COO, dan transformation leader: Jika besok agent Anda membuat keputusan yang salah tetapi tidak menimbulkan error teknis, apakah organisasi Anda akan mengetahuinya dengan cepat? Apakah Anda bisa menjelaskan kepada audit atau regulator bagaimana sebuah tindakan agent terjadi dari awal sampai akhir? Siapa yang saat ini memiliki metric kualitas agent di production: engineering, bisnis, atau tidak ada? Apakah dashboard Anda menunjukkan outcome bisnis, atau hanya kesehatan infrastruktur? Dan yang paling penting: apakah perusahaan Anda benar-benar siap memberi otonomi lebih besar kepada agent sebelum mampu mengamati perilakunya dengan disiplin?
Observability bukan aksesori setelah sistem live. Dalam agentic enterprise, observability adalah syarat minimum agar otonomi tetap berada di dalam batas kontrol.