Observability für Agentic Systems
Stell der vor, es Finanzteam het grad en Agent iigsetzt, wo bi de monatleche Abschlüss hälfe söll. Dä Agent cha Date us em ERP hole, Spreadsheets läse, wo per Email cho sind, und für jedes Konto en Kommentar-Entwurf mache. Uf de Oberflächi gseht alles guet us. Kei Fehler, kei Crash, kei API wo uslötet. Aber nach es paar Zykle fingt de Controller a, Anomalie z'entdecke: es paar Kontene händ Kommentar, wo Zahle us ere veraltete Dateversion bruuched. De Agent het nöd falsch uf es Tool zuegriffe, er isch nöd technisch gschiteret, aber sini Entscheidig isch operativ falsch gsi.
Situatione wie die sind es richtigs Problem. Sobald de Agent i de Production isch, sind d'Frage nümme "Lauft s'Sischteem?", sondern "Was het de Agent genau gmacht, wieso het er das gmacht, isch s'Ergebnis guet, und wänn sött mer ihn abstelle?" Ohni d'Fähigkeit, die Frage z'beantworte, het d'Firma kei Verantwortlichkeit. Und ohni Verantwortlichkeit wird d'Otonomy, wo eigentli begränzt isch, schnell zu eme Risiko, wo nümm kontrollierbar isch.
I traditionelle Enterprise-Aawendige konzentriert sich Observability normalerwiis uf di technischi Gsundheit: isch de Service am Laufen, stigt d'Latenz oder fallt si, gönd d'Fehlerrate ufe, isch d'Datebank langsam, oder versagt d'API. Bi Agentic Systems isch das nume en chline Teil vom Problem. De Agent füert nöd nume deterministische Code us. Er überleit, wählt es Tool us, holt Kontext, rüeft Sischteem a, speicheret oder brucht Memory, und produziert denn en Output, wo probabilistisch isch. Zwei Uusfüerige mit ähnlichem Input chönd zu verschidene Entscheidigspfad füehre. Drum muess d'Observability für Agentic Systems drei Schichte gliichzitig abdecke: was technisch passiert, was de Agent entschidet, und was d'Uswirkig uf s'Business-Outcome und d'Policy-Compliance isch.
Wieso Observability für Agentic Systems vil schwieriger isch
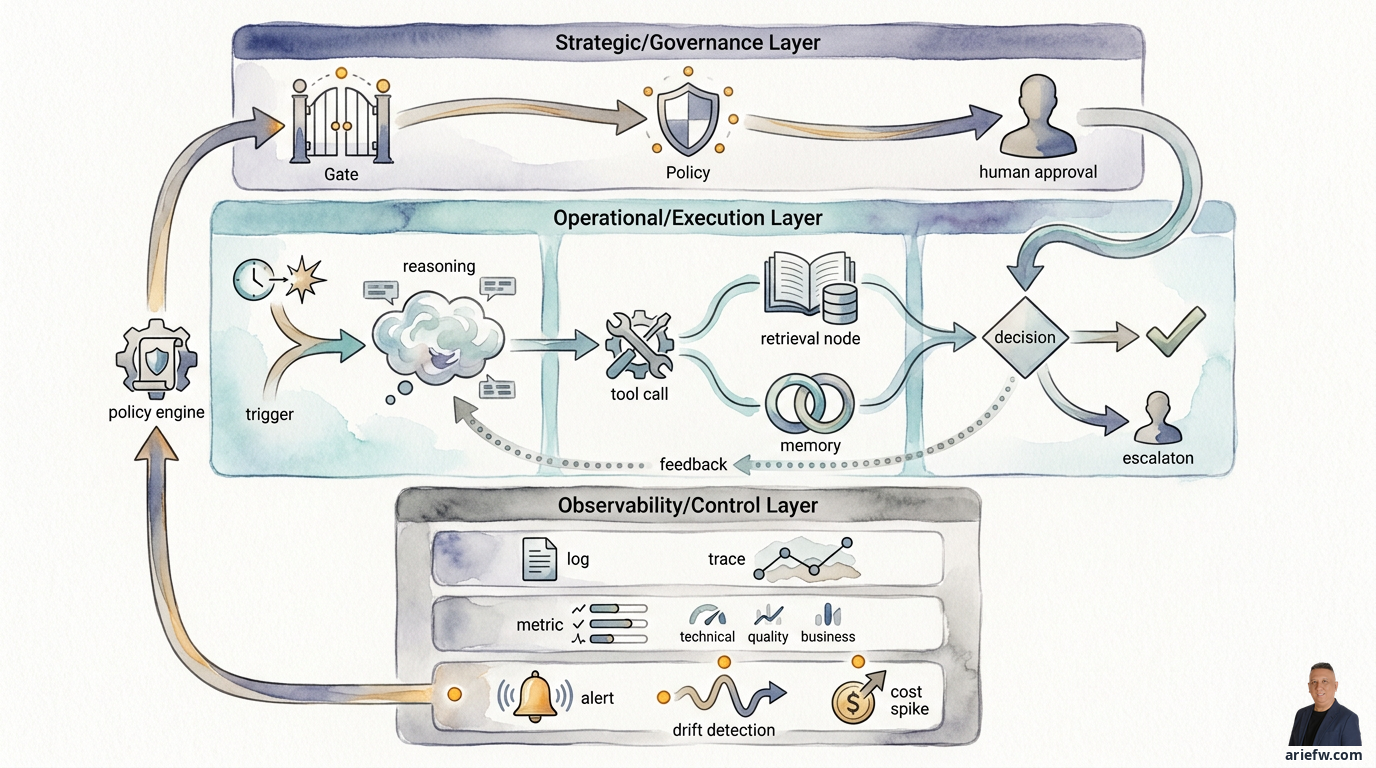
Di grössti Schwierigkeit bi de Observability vo Agentic Systems isch nöd, dass d'Technik nöier isch, sondern dass s'Objekt, wo beobachtet wird, komplexer isch. Bi normale Aawendige isch de Uusfüerigsfluss relativ klar. En Request chunt ine, en Service verarbeitet, d'Datebank wird gläse, en Response gaht use. Wenn es Problem git, chönd d'Teams Logs, Metrike und Traces duregoo, zum de Bottleneck oder de Fehler finde. Bi Agentic Systems cha de Fluss vil schichtiger si: en Trigger chunt vomene Benutzer, Ereignis oder Workflow; en Orchestrator teilt d'Ufgab uuf; de Agent holt Kontext us RAG oder Memory; es Modell produziert Reasoning oder en Plan; Tools wärde einzeln ufgrüeft; en Policy Engine bewertet d'Aktion; en Mensch wird vilicht um en Approval bittet; und denn füert de Agent d'Aktion us oder eskalieret.
S'Problem isch, dass en Fehler nöd immer als technische Fehler uuftaucht. De Agent cha alli API's erfolgriich ufrüefe, aber di falschi Aktion uswähle. Er cha nöd crashe, aber en veraltete Kontext bruche. Er cha technisch durechoo, aber e Policy verletze. Er cha d'Task abschlüüsse, aber d'Qualität vo sinere Entscheidig isch schlecht. Oder er cha en Output produziere, wo überzügend tönt, aber operativ falsch isch. Mit andere Wort: d'Observability vom Agent isch nöd gnue, wenn si nume antwortet "Lauft s'Sischteem?" Si muess au antworte "Handlet de Agent richtig?"
De probabilistisch Charakter vo Agentic Systems veränderet, wie mer überwacht. Sogar wänn Prompt, Tool und Date gliich usgsehn, cha de Output chli abwiiche. Das bedütet, dass d'Firma nöd uf es Monitoring uf Basis vo Fehlercode allei cha verloo. Si müend Muster im Verhalte überwache. Es Bispiel us em Customer Operations: en Agent für Rückzahlige cha technisch nie versage, aber i de letschte Wuche fangt er a, Fäll öfter z'eskaliere, wo vorher automatisch chönd glöst wärde. Infrastrukturell isch alles grüen. Operativ gseht me e Drift im Verhalte, wo d'Produktivität senkt. Es anders Bispiel im Procurement: en Agent für Intake-to-PO cha immer no erfolgriich Request mache, aber er fangt a, de konservativere Approval-Pfad öfter z'wähle, wil d'Retrieval-Policy sich gänderet het. Es git kei technische Incident, aber d'Zykluszit wird schlächter.
Im Enterprise-Kontext isch Observability nöd nume es Tool für d'IT-Operation. Si isch en Governance-Mechanismus. Risk, Audit, Compliance und d'Prozessbesitzer müend chönne beantworte: welen Kontext het de Agent bruucht, weles Tool het er ufgrüeft, welli Policy isch aagwändet worde, wänn het de Agent uufghört und um en Approval bittet, wer het de Output korrigiert, und wie het die Entscheidig d'Transaktion oder de Business-Fall beiiflusst? Wenn d'Firma die Chetti nöd cha rekonstruiere, denn het si kei solide Grundlage für d'Incident-Untersuechig, s'Audit, d'Qualitätsbewertig, d'Modellverbesserig oder d'Erhöhig vom Otonomy-Level. Drum muess d'Observability als Teil vom Control Plane behandlet wärde, nöd nume als es operativs Dashboard.
Was sött g'loggt wärde: Vom Prompt bis zum Outcome
De hüfigscht Fehler isch z'dänke, es Log vom Agent sig gnue, wänn me de Prompt und d'Response speicheret. Für es Enterprise isch das vil z'oberflächlich. Es Log, wo für Agentic Systems taugt, muess de Entscheidigspfad End-to-End erfasse. Nöd nume, was s'Modell gseit het, sondern au de Kontext, d'Aktion und d'Kontrollene, wo drum ume sind.
Es git sächs Komponente, wo me bi de Logs mindestens sött beachte. Erschtens: de Trigger und de aafänglich Kontext. D'Firma muess wüsse, wie de Workflow aagfange het: isch er vomene Benutzer, eme Sischteem-Ereignis, eme regelmässige Plan oder vomene Handoff vo eme andere Agent usglöst worde? Das Log sött d'Identität vom ursprüngliche Principal, d'Zyt, de Kanal und s'relevant Business-Objekt erfasse, zum Bispiel d'Rächnigsnummer, Ticket-ID, Order-ID oder Incident-ID.
Zweitens: de Prompt und d'Runtime-Instruktion. Nöd zum alli Detail willkürlich z'speichere, sondern zum sicherzstelle, dass d'Firma cha verstah, welli Sischteem-Instruktion aktiv gsi isch, welli Parameter bruucht worde sind, welli Version vom Prompt oder Workflow gloffe isch, und welli Modell-Konfiguration aagwändet worde isch. Das isch wichtig, wänn d'Firma d'Performance vo verschidene Agent-Versione wott vergliche oder e Veränderig im Verhalte wott untersueche.
Drittens: de retrieved Kontext. Wänn de Agent RAG, en Knowledge Graph oder Memory brucht, sött s'Log zeige, welli Dokumänt oder Kontext-Stück usegno worde sind, vo wellere Quelle, mit wellere Version oder Timestamp, und ob de Zuegriff d'Permission-Check bestande het. Ohni das isch's schwirig z'erkläre, wieso de Agent e bestimmti Entscheidig troffe het.
Viertens: d'Modell-Response und s'Reasoning-Artifact. D'Firma muess nöd immer de ganz roh Chain-of-Thought speichere. Aber si müend gnueg Artifact für s'Audit und s'Debugging speichere, zum Bispiel e Zämmefassig vom Aktionsplan, d'Klassifizierig vo de Intent, en Confidence-Signal, wänn's verfügbar isch, oder en strukturierte Decision Output, wo für de nöchscht Schritt bruucht wird. De Grundsatz isch: speicher gnueg für d'Verantwortlichkeit, aber mach s'Log nöd zu eme Ort, wo sensibli Date oder Intellectual Property vom Modell uselauft.
Fünftens: de Tool Call und s'Ergebnis. Jede Tool Call sött ufzeichnet wärde: weles Tool isch ufgrüeft worde, welli wichtige Parameter händ gha, isch s'Ergebnis erfolgriich oder nöd, wie lang isch d'Latenz gsi, hets en Retry gäh, und welli State-Änderig isch im Ziel-Sischteem passiert. Für Workflow wie Finance Close, IT Operations oder Procurement isch das de wichtigscht Teil, wil do fangt de Agent a, di operativ Realität z'beiiflusse.
Sächstens: d'Policy-Entscheidig, de Human Approval und di final Aktion. Wänn's en Policy Engine, en Approval-Workflow oder Guardrails git, müend alli is Log: welli Policy isch bewertet worde, isch s'Ergebnis Allow, Deny, Escalate oder Require Approval gsi, wer isch de menschlich Approver gsi, was isch d'Endentscheidig gsi, und welli final Aktion isch würkli usgfüert worde. Ohni die Schicht het d'Firma nume technischi Logs, aber kei Governance-Logs.
Es guets Log isch no nöd garantiert, dass es en guete Trace git. Vili Organisatione händ Logs a vilne Ort, aber chönd de Fluss vom Aafang bis zum End nöd zämmebringe. Für Agentic Systems muess de Trace de ganz Wäg zeige: de Trigger chunt ine, de Agent oder Orchestrator, wo aktiv isch, de Kontext wo usegno wird, de Reasoning- oder Planning-Step, de Tool Call, de Policy-Check, de menschlich Approval, wänn's eine git, di final Aktion und s'Business-Outcome. Es Bispiel bi de AP Exception Handling: en Rächnigs-Ungliichheit chunt ine, de Agent holt d'PO-Date, de Goods Receipt und d'Vendor-Historie, de Agent klassifiziert d'Ursach vo de Ungliichheit, de Agent rüeft es Tool uf zum en Fall z'eröffne, d'Policy Engine prüeft, ob de Fall automatisch wiitergleitet wärde cha, de Supervisor git für bestimmti Fäll en Approval, de Agent schickt es Follow-up zum Buyer, de Fall wird gschlosse oder blibt offe. Wänn de Trace nöd ganz isch, gseht s'Operationsteam nume Stück vom Ereignis, ohni d'Ursach und d'Wirkig z'verstah.
Je vollständiger d'Logs sind, desto grösser isch au s'Risiko vo Date-Exposure. Das isch en Trade-off, wo me mit Disziplin muess handle. Agentic Systems händ oft mit Kundedate, Payroll-Informatione, Vendor-Details, Verträg, Finanzdate oder interne Incident-Notize z'tue. Drum muess s'Logging mit eme Prinzip vo Redaktion für sensibli Date, wo nöd roh gspicheret wärde müend, Tokenization oder Masking für bestimmti Identifier, sicherem Storage mit strenge Zuegriffskontrollene, ere klare Retention-Policy und ere Trennig vo Ufgabe (Segregation of Duties) designet wärde, damit nöd alli, wo d'Observability verwalte, de sensibli Inhalt gsehn. Es Bispiel us de HR Operations: es Log darf ufzeichne, dass de Agent d'Policy für Ferie und de Status vom Onboarding usegno het, aber nöd alli persönliche Detail müend imene allgemeine Dashboard roh gspicheret si. Es Bispiel us em Customer Service: es Transkript muess vilicht für es beschränkts Audit gspicheret wärde, aber d'PII sött für de täglich operativ Gebruuch gmasked si. De wichtig Grundsatz isch: d'Auditability sött stige, ohni de Blast Radius vo de Date z'vergrössere.
Metrike zur Laufzyt: Nöd nume technisch, sondern au Qualität und Business
Wänn s'Logging und Tracing verfüegbar sind, isch de nöchscht Schritt, d'Metrike z'definiere. Do sind vili Implementierige vo Agentic Systems no vil z'eng. Si überwache nume d'Latenz und d'Fehlerrate und denked, s'Sischteem sig "observable". Aber Agentic Systems bruched drei verschideni Gruppe vo Metrike.
Di erschti Gruppe sind technischi Metrike für d'Gsundheit vo de Runtime. Technischi Metrike sind immer no wichtig, wil Agentic Systems uf Modell, API, Retrieval und Tool-Integratione aagwise sind, wo alli chönd versage. Es paar grundlegendi Metrike, wo me sött überwache: d'Latenz pro Schritt und End-to-End, d'Token- oder Compute-Coste pro Transaktion, d'Tool-Error-Rate, d'Retry-Rate, d'Timeout-Rate, d'Fallback-Usage, d'Failure-Mode-Distribution und d'Verfüegbarkeit vo wichtige Komponente wie em Model Gateway, em Vector Store, de Policy Engine oder em Tool Registry. Es Bispiel us de IT Operations: wänn d'Latenz vomene Agent für Incident Triage aastigt, cha d'SLA für d'Incident-Behandlig gstört wärde. Es Bispiel us em Customer Operations: wänn d'Retry-Rate zur CRM API aastigt, cha de Agent aafange, de Kundenkontext nöd richtig z'erstelle. Technischi Metrike hälfed em Platform-Team, d'Stabilität z'halte, aber si sind nöd gnueg zum beurteile, ob de Agent no vertrauenswürdig isch.
Di zweiti Gruppe sind Qualitätsmetrike zum beurteile, ob de Agent gueti Entscheidige trifft. Das isch d'Schicht, wo d'Observability vo Agentic Systems vo de Observability vo normale Aawendige unterscheidet. Qualitätsmetrike chönd d'Accuracy gegenüber eme erwartete Label oder Outcome, d'Hallucination-Rate oder Unsupported-Answer-Rate, d'Escalation-Rate, d'Policy-Violation-Rate, d'Human-Correction-Rate, d'Rework-Rate nach ere Aktion vom Agent, d'Tool-Selection-Accuracy und d'Grounding-Qualität gegenüber em usegno Kontext umfasse. Es Bispiel bim Finance Close: wie vili Entwürf vom Agent müend vom Controller korrigiert wärde, wie vili Exceptione sind falsch klassifiziert worde, und wie oft het de Agent en Accounting-Guideline usegno, wo nöd relevant gsi isch. Es Bispiel im Procurement: wie vili Request sind zum falsche Approval-Pfad gleitet worde, wie vili Vendor-Empfehlige sind vom Buyer abglehnt worde, und wie oft isch en Policy-Breach verhinderet worde oder isch duregschlüpft. Es Bispiel us em Customer Operations: wie vili Refund-Empfehlige sind vom Supervisor abglehnt worde, wie vili Antworte vom Agent sind nöd vo de Kundeberächtigung gstützt gsi, und wie vili Fäll händ müend wider ufgmacht wärde. En wichtige Trade-off do: es paar Qualitätsmetrike chönd nöd vollautomatisch gmesse wärde. D'Firma brucht oft e Kombination us automatischer Evaluierig, manueller Stichprob, Feedback vo Benutzer und Review vo Fachexperte.
Di dritti Gruppe sind Business-Metrike zum beurteile, ob de Agent d'Operation würkli verbesseret. Am End sind Agentic Systems nöd bout worde, zum schöni Trace z'produziere, sondern zum Business-Outcome z'verbessere. Drum muess d'Observability mit Metrike wie d'Zykluszit, d'Coste pro Transaktion, d'Resolution-Rate, d'Touchless-Rate, d'Reduktion vom Backlog, de Revenue-Impact, wänn relevant, de Working-Capital-Impact für bestimmti Use Cases, und d'Zfrideheit vo Kunde oder Mitarbeiter verbunde si. Es Bispiel us de Shared Services: en Agent für Case Management cha technisch gsund usgseh, aber wänn d'Coste pro Fall nöd sinket und de Backlog sich nöd verbesseret, denn muess me s'Design überprüefe. Es Bispiel us de GCC Finance Operations: en Agent für AP Exception cha e höchi Accuracy ha, aber wänn d'Zykluszit nöd besser wird, wil de Approval-Bottleneck gliich blibt, denn isch s'Problem bim Operating Model, nöd bim AI-Modell allei.
Ein wichtigi Disziplin isch, d'technische, d'Qualitäts- und d'Business-Metrike z'trenne. Wänn alli vermischt sind, wird's für d'Organisation schwirig, d'Ursach vomene Problem z'finde. Zum Bispiel: d'Latenz stigt isch es technischs Problem, d'Human-Correction-Rate stigt isch es Qualitätsproblem, d'Zykluszit sinkt nöd isch es Business- oder Prozessdesign-Problem. Die drei sind verwandt, aber me sött si nöd gliich behandlet.
Monitoring und Alerting: Drift erkenne, bevor's en Incident wird
Wänn d'Metrike definiert sind, muess d'Firma entscheide, was si kontinuierlich überwacht und wänn en Alert uuftauche söll. Das isch bi Agentic Systems schwiriger, wil vili Problem als Verschiebig vo Muster uuftauche, nöd als totale Uusfall.
Es git es paar Sache, wo me aktiv sött überwache. Erschtens: de Drift im Verhalte. En Agent cha sis Verhalte ändere, au wänn's kei grossi Änderig a de Aawendig git. D'Ursach cha vo Modelländerige, Prompt-Änderige, Änderige im Retrieval-Corpus, Änderige i de Dateverteilig oder Änderige i de Tool-Response cho. S'Signal cha si, dass d'Escalation-Rate stigt, de Output ungewöhnlich länger oder chürzer wird, es bestimmts Tool vil öfter bruucht wird, oder d'Klassifizierigsverteilig sich starch veränderet.
Zweitens: d'Anomalie im Tool-Gebruuch. Wänn en Procurement-Agent, wo normalerwiis d'Verträg und d'Vendor-API ufrüeft, uf einisch öfter de manuell Exception-Pfad brucht, isch das es wichtigs Signal. Wänn en IT-Operations-Agent afangt, bestimmti Runbooks vil öfter als de Baseline uszfüere, cha das en Drift, en Bug oder e Veränderig i de Umgebig bedüte.
Drittens: d'Änderig i de Output-Verteilig. S'Monitoring muess d'Muster im Output aluege, nöd nume d'Fehler. Zum Bispiel: meh Antworte "weiss nöd", meh konservativi Empfehlige, meh Aktionene wo vom Mensch abglehnt wärde, oder meh Fäll wo ohni Lösig ändet. Das sind oft früehi Zeiche, dass d'Qualität vom Agent sinkt.
Nöd alli Alert sötted als technischi Incident behandlet wärde. Für Agentic Systems git's mindestens vier Kategorie vo Alert. Erschtens: technischi Incident, zum Bispiel de Model Gateway isch abgstürzt, d'Tool-API het en Timeout, de Vector Store versagt, d'Latenz isch über de Grenzwert, oder d'Retry-Rate schnellt ufe. De Haupt-Besitzer isch normalerwiis s'Platform- oder Engineering-Team. Zweitens: Policy-Breach, zum Bispiel de Agent probiert e Aktion usserhalb vo de Erlaubnis, de Zuegriff uf sensibli Date isch nöd kontextuell passend, en notwendige Approval isch umgange worde, oder en Tool-Call wird widerholt wäge Policy-Mismatch abglehnt. De Besitzer umfasst Security, Risk und de Prozessbesitzer. Drittens: tüüf Qualität, zum Bispiel d'Human-Correction-Rate stigt starch, d'Unsupported-Answer-Rate nimmt zue, d'Klassifizierig isch falsch und d'Escalation-Rate veränderet sich starch. Das brucht normalerwiis en Review zwüschem Produkt-Team, em Domain-Besitzer und de AI-Ops. Viertens: Cost-Spike, zum Bispiel d'Token-Coste pro Transaktion stiged, d'Tool-Calls sind vil z'vil, de Kontext-Retrieval isch z'gross, oder de Fallback uf es tüürers Modell nimmt zue. Das isch wichtig, wil Agentic Systems chönd "funktioniere", aber d'Economics verschlechteret sich still und heimlich.
Zum das konkreter z'mache, stell der es Dashboard für en Procurement-Agent Intake-to-PO vor. Es nützlichs Dashboard zeigt nöd nume d'Uptime. Es sött vier Panel ha. S'erschte Panel: Runtime Health: Volume vo Request pro Stund/Tag, End-to-End-Latenz, Tool-Success/Failure-Rate, Retry-Rate, Token-Coste pro Request. S'zweite Panel: Decision Quality: Intake-Accuracy, Policy-Violation-Prevented, Human-Correction-Rate, Escalation-Rate, Approval-Override-Rate. S'dritte Panel: Business Outcome: Zykluszit vom Intake bis zur Request-Erstellig, Touchless-Rate, Backlog-Request, SLA-Compliance, Rework pro Request. S'vierte Panel: Governance and Audit: di meist abglehnte Tool-Calls, d'Approval-Queue-Aging, d'Dokumänt-Policy wo am hüfigste referenziert wird, d'Anomalie im Tool-Gebruuch, und es Trace-Sample für d'Untersuechig. Es sonigs Dashboard hilft drei Gruppe gliichzitig: em Engineering-Team für d'Runtime-Gsundheit, em Prozessbesitzer für d'Qualität und s'Outcome, und Risk und Audit für d'Compliance und d'Kontrollspur.
Trade-offs bi de Implementierig: Kei "Surveillance Monster" baue
Au wänn d'Observability sehr wichtig isch, git's en andere Fallstrick: d'Organisation cha über's Ziel schiesse und probiere, alles ohni Priorität z'logge. D'Folge: d'Storage-Coste schwelle a, s'Dashboard isch voll mit Noise, d'Team wüssed nöd, weles Signal wichtig isch, und s'Risiko für d'Privacy stigt. Drum sött s'Design vo de Observability em Risk-Tier und de Criticality vom Use Case folge. En Use Case wie en interne Knowledge Assistant cha mit chlinere Logs uschoo. Umgekehrt bruuche Use Cases wie Refund Automation, Finance Exception Handling oder IT Remediation vil tüüferi Trace und Audit. En gsunde Grundsatz: log gnueg für d'Verantwortlichkeit, mess gnueg für d'Entscheidigsfindig, und alert gnueg, dass d'Team würkli handle. Gueti Observability isch nöd die mit de meischte Date, sondern die, wo de Firma am beste hilft, s'Verhalte vom Agent z'gseh, z'erkläre und z'kontrolliere.
Nach em Läse vo däm Artikel sött me es paar Entscheidige träffe. Erschtens: leg en Standard für End-to-End-Trace für jede Agent i de Production fest. Cha d'Firma de Fluss vom Trigger bis zum Business-Outcome verfolge, inklusive Context-Retrieval, Tool-Call, Policy-Entscheidig, Approval und finaler Aktion? Zweitens: trenn d'Metrike i drei Schichte: technisch, Qualität und Business. Wer isch de Besitzer für jedi Schicht, und welli Dashboard wärde bruucht, zum d'Beziehige zwüschedene z'läse? Drittens: leg e Logging-Policy für sensibli Date fest. Was darf roh gspicheret wärde, was muess redigiert wärde, wer darf d'Logs aluege, und wie lang isch d'Retention? Viertens: definier d'Kategorie vo Alert. Unterscheidet d'Firma scho zwüsched technischem Incident, Policy-Breach, tüüfer Qualität und Cost-Spike mit verschidene Reaktionspfad? Fünftens: entscheid über s'Modell für d'Qualitätsprüefig i de Production. Wird d'Qualität vom Agent über en automatischi Evaluierig, manuelli Stichprob, menschlichs Feedback oder e Kombination devo überwacht?
Es git es paar Alarmzeiche, dass d'Observability no nöd bereit für d'Skalierig isch. De Agent darf scho handle, aber d'Firma speicheret nume grundlegendi Chat-Logs. Tool-Calls sind nöd mit em gliiche Trace verbunde wie d'Modellentscheidig. Es git kei Möglichkeit z'erkläre, welen Kontext de Agent bi sinere Entscheidig bruucht het. Alli Alert gönd in eine Kanal ohni Unterscheidig vo Priorität oder Incident-Typ. S'Team überwacht nume d'Latenz und d'Uptime, aber nöd d'Correction-Rate oder d'Policy-Violation. S'Dashboard wird nume vom technische Team bruucht, nöd vom Prozessbesitzer und de Risk-Funktion. D'Logs sind z'riich an sensible Date ohni adäquati Redaktion. Es git kei klar Verbindig zwüsched de Telemetry vom Agent und de KPI vom Business-Prozess.
Reflektivi Frage für CIO, COO und Transformation Leader: Wänn öie Agent morn e falschi Entscheidig trifft, aber kein technische Fehler produziert, wird öii Organisazion das schnell gseh? Chönd er emene Audit oder Regulator erkläre, wie e Aktion vom Agent vom Aafang bis zum End passiert isch? Wer het aktuell d'Qualitätsmetrike vom Agent i de Production: Engineering, Business, oder niemert? Zeiget öii Dashboard s'Business-Outcome, oder nume d'Infrastruktur-Gsundheit? Und am wichtigschte: isch öii Firma würkli bereit, em Agent meh Otonomy z'gäh, bevor si sis Verhalte mit Disziplin cha beobachte?
Observability isch kei Accessoire, wo me nach em Live-Gang aabringt. Imene Agentic Enterprise isch Observability di minimali Bedingig, dass d'Otonomy innerhalb vo de Kontrollgränze blibt.