エージェンティックシステムにおけるオブザーバビリティ
ある金融チームが、月次決算プロセスを支援するエージェントを導入したと想像してみてください。このエージェントは、ERPからデータを取得し、メールで送信されたスプレッドシートを読み取り、各勘定科目のドラフトコメントを作成できます。表面的には、すべてが順調に見えます。エラーもなければ、クラッシュもなく、APIのタイムアウトも発生しません。しかし、数サイクルが経過した後、コントローラーは異常を発見し始めます。いくつかの勘定科目のコメントが、すでに期限切れとなったデータバージョンの数値を使用していたのです。エージェントはツールの呼び出しを誤ったわけでも、技術的に失敗したわけでもありません。しかし、その判断は業務的に誤っていたのです。
このような状況は、現実的な問題です。エージェントが本番環境に導入されると、問われるのは「システムは動作しているか」ではなく、「エージェントは実際に何をしたのか、なぜその行動をとったのか、その結果は良好か、そしていつ停止すべきか」です。これらの問いに答えられなければ、企業には説明責任が生じません。そして、説明責任がなければ、制限された自律性はすぐに制御不能なリスクへと変貌します。
従来のエンタープライズアプリケーションでは、オブザーバビリティは通常、技術的な健全性、つまりサービスが稼働しているか、レイテンシが上昇または下降しているか、エラーが増加しているか、データベースが遅延しているか、APIが失敗しているか、といった点に焦点を当てていました。エージェンティックシステムでは、これは問題のごく一部に過ぎません。エージェントは決定論的なコードを実行するだけではありません。推論し、ツールを選択し、コンテキストを取得し、システムを呼び出し、メモリを保存または使用し、そして確率的な出力を生成します。類似した入力であっても、2回の実行で異なる判断経路が生じる可能性があります。したがって、エージェンティックシステムのためのオブザーバビリティは、技術的に何が起こったか、エージェントが何を決定したか、そしてそれがビジネス成果やポリシー準拠にどのような影響を与えたか、という3つの層に同時に対応する必要があります。
エージェンティックシステムにおけるオブザーバビリティがはるかに困難な理由
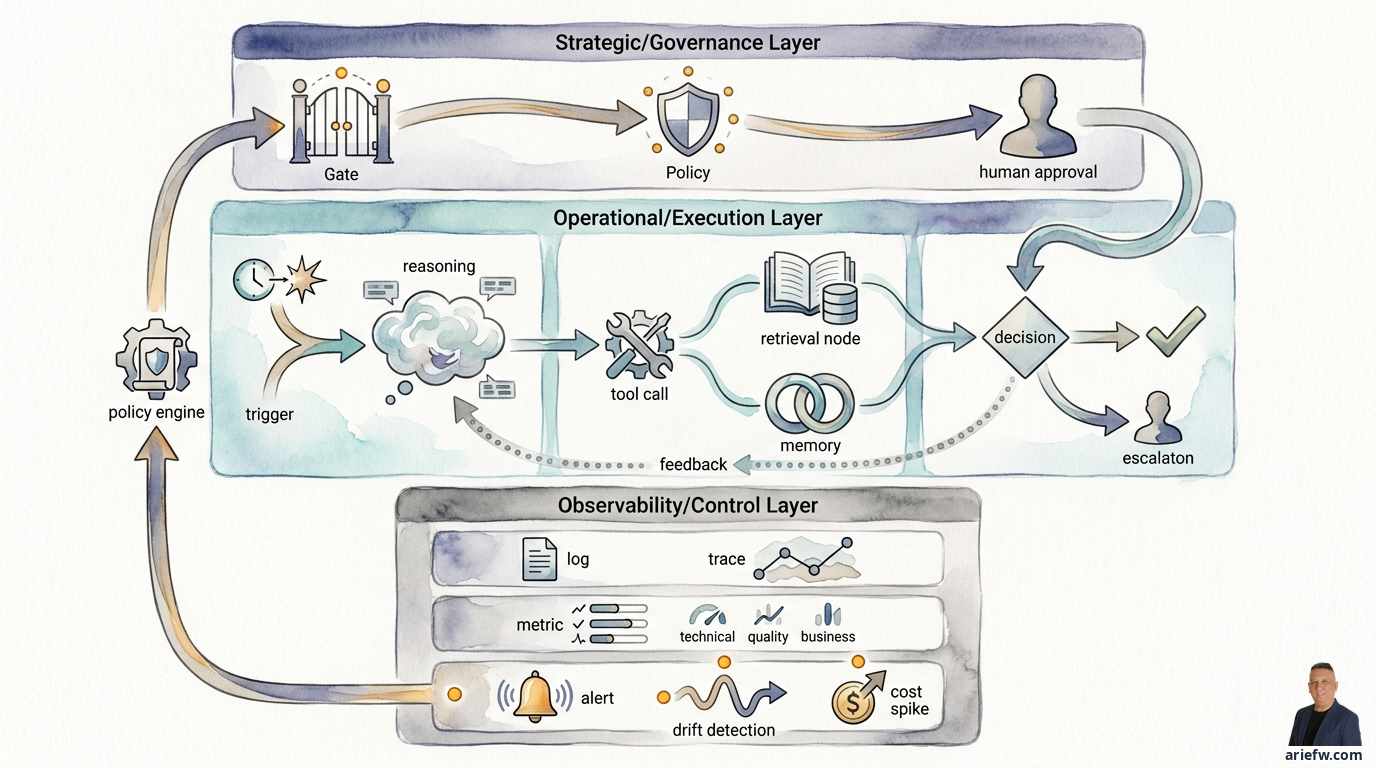
エージェンティックシステムにおけるオブザーバビリティの主な困難は、技術が新しいからではなく、観測対象がより複雑だからです。通常のアプリケーションでは、実行フローは比較的明確です。リクエストが入り、サービスが処理し、データベースが読み取られ、レスポンスが出ます。問題があれば、チームはログ、メトリクス、トレースを調査して、ボトルネックやエラーを特定できます。エージェンティックシステムでは、フローははるかに多層的になる可能性があります。トリガーはユーザー、イベント、またはワークフローから発生します。オーケストレーターがタスクを分解します。エージェントはRAGやメモリからコンテキストを取得します。モデルが推論や計画を生成します。ツールが一つずつ呼び出されます。ポリシーエンジンがアクションを評価します。人間による承認が必要になる場合もあります。そして、エージェントがアクションを実行するか、エスカレーションします。
問題は、障害が常に技術的なエラーとして現れるとは限らないことです。エージェントはすべてのAPIの呼び出しに成功しても、誤ったアクションを選択する可能性があります。クラッシュはしなくても、期限切れのコンテキストを使用する可能性があります。技術的には問題がなくても、ポリシーに違反する可能性があります。タスクは完了しても、判断の質が低い可能性があります。あるいは、もっともらしく聞こえるが業務的に誤った出力を生成する可能性があります。言い換えれば、エージェンティックなオブザーバビリティは、「システムは動作しているか」という問いに答えるだけでは不十分です。「エージェントは正しく行動しているか」という問いにも答えなければなりません。
エージェンティックシステムの確率的な性質は、監視の方法を変えます。プロンプト、ツール、データが同じに見えても、出力はわずかに異なる可能性があります。これは、企業がエラーコードベースの監視だけに依存できないことを意味します。行動パターンを監視する必要があります。カスタマーオペレーションの例を挙げましょう。返金エージェントは技術的に失敗することはないかもしれませんが、ここ1週間で、以前は自動で解決できていたケースをより頻繁にエスカレーションするようになったとします。インフラストラクチャ的には、すべてが正常です。しかし、運用面では、生産性を低下させる行動のドリフトが発生しています。調達の別の例では、インテークから発注までのエージェントは引き続きリクエストの作成に成功するかもしれませんが、検索ポリシーの変更により、より保守的な承認経路を選択する頻度が増え始めます。技術的なインシデントはありませんが、サイクルタイムは悪化しています。
エンタープライズの文脈では、オブザーバビリティは単なるIT運用ツールではありません。それはガバナンスのメカニズムです。リスク、監査、コンプライアンス、プロセスオーナーは、エージェントがどのコンテキストを使用したか、どのツールを呼び出したか、どのポリシーが適用されたか、いつエージェントが停止して承認を求めたか、誰が出力を修正したか、そしてその判断がビジネストランザクションやケースにどのように影響したか、といった問いに答えられる必要があります。企業がこの連鎖を再構築できなければ、インシデント調査、監査、品質評価、モデル改善、自律性レベルの向上のための強固な基盤はありません。だからこそ、オブザーバビリティは単なる運用ダッシュボードではなく、コントロールプレーンの一部として扱われなければなりません。
何をログに記録すべきか:プロンプトから成果まで
最も一般的な誤りは、プロンプトとレスポンスを保存しておけばエージェントのログとして十分だと考えることです。エンタープライズにとって、これはあまりにも浅はかです。エージェンティックシステムにふさわしいログは、エンドツーエンドの判断の軌跡を捉える必要があります。モデルが何を言ったかだけでなく、それを取り巻くコンテキスト、アクション、制御も含まれます。
最低限考慮すべき6つのログコンポーネントがあります。第一に、トリガーと初期コンテキストです。企業はワークフローがどのように開始されたかを把握する必要があります。ユーザー、システムイベント、定期的なスケジュール、または別のエージェントからのハンドオフのいずれがトリガーとなったのか。このログには、元のプリンシパルのID、時刻、チャネル、および関連するビジネスオブジェクト(例:請求書番号、チケットID、注文ID、インシデントID)を記録する必要があります。
第二に、プロンプトとランタイム命令です。すべての詳細を無差別に保存するためではなく、どのシステム命令がアクティブだったか、どのパラメータが使用されたか、どのバージョンのプロンプトやワークフローが実行されていたか、どのモデル設定が使用されたかを企業が理解できるようにするためです。これは、エージェントのバージョン間でパフォーマンスを比較したり、動作の変化を調査したりする際に重要です。
第三に、取得されたコンテキストです。エージェントがRAG、ナレッジグラフ、またはメモリを使用する場合、ログには、どのドキュメントやコンテキストの断片が取得されたか、どのソースからか、そのバージョンやタイムスタンプ、そしてアクセスがパーミッションチェックを通過したかどうかを示す必要があります。これがなければ、エージェントが特定の判断を下した理由を説明するのは困難です。
第四に、モデルのレスポンスと推論アーティファクトです。企業は常に生の思考連鎖全体を保存する必要はありません。しかし、監査とデバッグに十分なアーティファクト、例えば、アクション計画の要約、インテントの分類、利用可能な場合は信頼度シグナル、または次のステップで使用される構造化された判断出力などを保存する必要があります。原則は、説明責任のために十分な量を保存するが、ログを機密データやモデルの知的財産が漏洩する場所にしないことです。
第五に、ツール呼び出しとその結果です。すべてのツール呼び出しは記録される必要があります。どのツールが呼び出されたか、重要なパラメータ、結果が成功か失敗か、レイテンシ、リトライの有無、ターゲットシステムでどのような状態変化が発生したか。財務諸表のクローズ、IT運用、調達などのワークフローでは、エージェントが業務上の現実に影響を与え始めるのはこの部分であるため、最も重要です。
第六に、ポリシー判断、人間による承認、および最終アクションです。ポリシーエンジン、承認ワークフロー、またはガードレールが存在する場合、それらはすべてログに記録される必要があります。どのポリシーが評価されたか、結果(許可、拒否、エスカレーション、承認要求)、承認した人間、最終的な判断、そして実際に実行された最終アクション。この層がなければ、企業は技術的なログしか持たず、ガバナンスのログは持ちません。
良いログがあっても、必ずしも良いトレースが得られるとは限りません。多くの組織は多くの場所にログを持っていますが、開始から終了までのフローを統合できません。エージェンティックシステムの場合、トレースは完全な経路を示す必要があります。トリガーの入力、アクティブになったエージェントまたはオーケストレーター、取得されたコンテキスト、推論または計画ステップ、実行されたツール呼び出し、ポリシーチェック、該当する場合は人間による承認、最終アクション、そしてビジネス成果。AP(買掛金)例外処理の例では、請求書の不一致が発生し、エージェントがPOデータ、入庫データ、ベンダー履歴を取得し、不一致の原因を分類し、ケースを開くためのツールを呼び出し、ポリシーエンジンがケースの自動ルーティングが可能かどうかをチェックし、特定のケースについてスーパーバイザーが承認し、エージェントが購買担当者にフォローアップを送信し、ケースがクローズされるか、または未解決のまま残ります。このトレースが完全でなければ、運用チームはイベントの断片しか見ることができず、因果関係を理解できません。
ログが完全であればあるほど、データ露出のリスクも大きくなります。これは規律をもって管理しなければならないトレードオフです。エージェンティックシステムは、顧客データ、給与情報、ベンダー詳細、契約、財務データ、内部インシデント記録などに触れることがよくあります。したがって、ロギングは、生のまま保存する必要のない機密データのための編集、特定の識別子のためのトークン化またはマスキング、厳格なアクセス制御による安全なストレージ、明確な保持ポリシー、およびオブザーバビリティを管理するすべての人が機密内容を閲覧できるわけではないようにするための職務分離の原則に基づいて設計されなければなりません。人事業務の例では、ログはエージェントが休暇ポリシーやオンボーディングステータスを取得したことを記録しても構いませんが、すべての個人の詳細が一般的なダッシュボードに生のまま保存されるべきではありません。カスタマーサービスの例では、限定的な監査のためにトランスクリプトを保存する必要があるかもしれませんが、日常的な運用使用のためにPIIはマスキングされるべきです。重要な原則は、データの爆発半径を拡大することなく、監査可能性を高めることです。
ランタイムメトリクス:技術的なものだけでなく、品質とビジネスも
ロギングとトレーシングが利用可能になったら、次のステップはメトリクスを定義することです。ここで、多くのエージェンティック実装は依然として視野が狭すぎます。レイテンシとエラーレートだけを監視し、システムはすでに「観測可能」であると感じています。しかし、エージェンティックシステムには3つの異なるメトリクスグループが必要です。
最初のグループは、ランタイムの健全性を維持するための技術的メトリクスです。エージェンティックシステムは、モデル、API、検索、ツール統合に依存しており、これらはすべて失敗する可能性があるため、技術的メトリクスは依然として重要です。監視すべき基本的なメトリクスには、ステップごとおよびエンドツーエンドのレイテンシ、トランザクションあたりのトークンまたはコンピューティングコスト、ツールエラーレート、リトライレート、タイムアウトレート、フォールバック使用率、障害モードの分布、モデルゲートウェイ、ベクターストア、ポリシーエンジン、ツールレジストリなどの重要なコンポーネントの可用性が含まれます。IT運用の例では、インシデントトリアージエージェントのレイテンシが急増すると、インシデント対応のSLAが損なわれる可能性があります。カスタマーオペレーションの例では、CRM APIへのリトライレートが上昇すると、エージェントが顧客コンテキストを正しく構成できなくなる可能性があります。技術的メトリクスはプラットフォームチームが安定性を維持するのに役立ちますが、エージェントが依然として信頼できるかどうかを評価するには十分ではありません。
2番目のグループは、エージェントが適切な判断を下しているかどうかを評価するための品質メトリクスです。これこそが、エージェンティックなオブザーバビリティを通常のアプリケーションのオブザーバビリティから区別する層です。品質メトリクスには、期待されるラベルや成果に対する正確性、幻覚率または未サポート回答率、エスカレーション率、ポリシー違反率、人間による修正率、エージェントのアクション後の手戻り率、ツール選択の正確性、取得されたコンテキストに対するグラウンディング品質などが含まれます。財務諸表クローズの例では、コントローラーが修正しなければならなかったエージェントのドラフトコメントの数、誤って分類された例外の数、エージェントが無関係な会計ガイダンスを取得した頻度などです。調達の例では、誤った承認経路にルーティングされたリクエストの数、購買担当者に拒否されたベンダー推奨の数、ポリシー違反が防止された、またはすり抜けてしまった頻度などです。カスタマーオペレーションの例では、スーパーバイザーによって取り消された返金推奨の数、顧客の権利によってサポートされていないエージェントの回答の数、再オープンしなければならなかったケースの数などです。ここでの重要なトレードオフは、一部の品質メトリクスは完全に自動化して測定できないことです。企業はしばしば、自動評価、手動サンプリング、ユーザーフィードバック、ドメインエキスパートによるレビューの組み合わせを必要とします。
3番目のグループは、エージェントが実際に業務を改善しているかどうかを評価するためのビジネスメトリクスです。結局のところ、エージェンティックシステムは美しいトレースを生成するためではなく、ビジネス成果を改善するために構築されます。したがって、オブザーバビリティは、サイクルタイム、トランザクションあたりのコスト、解決率、タッチレス率、バックログ削減、該当する場合は収益への影響、特定のユースケースにおける運転資本への影響、顧客または従業員満足度などのメトリクスに接続される必要があります。シェアードサービスの例では、エージェントケース管理は技術的に健全に見えるかもしれませんが、ケースあたりのコストが下がらず、バックログが改善されなければ、その設計を見直す必要があります。GCC(グローバルキャプティブセンター)の財務運用の例では、AP例外エージェントは高い精度を持つかもしれませんが、承認のボトルネックが変わらないためにサイクルタイムが改善されなければ、問題はAIモデル自体ではなく、オペレーティングモデルにあります。
重要な規律の一つは、技術的メトリクス、品質メトリクス、ビジネスメトリクスを分離することです。これらがすべて混在していると、組織は問題の根本原因を読み解くのが難しくなります。例えば、レイテンシの上昇は技術的な問題、人間による修正率の上昇は品質の問題、サイクルタイムの非改善はビジネスまたはプロセス設計の問題です。これらは相互に関連していますが、同じものとして扱われるべきではありません。
モニタリングとアラート:インシデントになる前にドリフトを検出する
メトリクスが定義されたら、企業は何を継続的に監視し、いつアラートを出すべきかを決定する必要があります。これはエージェンティックシステムではより困難です。なぜなら、多くの問題は完全な障害としてではなく、パターンの変化として現れるからです。
積極的に監視すべきいくつかの事項があります。第一に、行動のドリフトです。エージェントは、アプリケーションに大きな変更がなくても、行動を変える可能性があります。原因は、モデルの変更、プロンプトの変更、検索コーパスの変更、データ分布の変更、ツールの応答の変更などから生じる可能性があります。兆候としては、エスカレーション率の上昇、出力が異常に長くなる、または短くなる、特定のツールがはるかに頻繁に使用される、分類の分布が急激に変化するなどがあります。
第二に、ツール使用の異常です。通常は契約やベンダーAPIを呼び出す調達エージェントが、突然手動例外経路をより頻繁に呼び出すようになった場合、それは重要なシグナルです。IT運用エージェントが特定のランブックをベースラインよりもはるかに頻繁に実行し始めた場合、それはドリフト、バグ、または環境の変化を示している可能性があります。
第三に、出力分布の変化です。モニタリングは、エラーだけでなく、出力のパターンも確認する必要があります。例えば、「わからない」という回答の増加、より保守的な推奨の増加、人間によって取り消されるアクションの増加、または未解決のまま終了するケースの増加などです。これらは、エージェントの品質が低下している初期の兆候であることがよくあります。
すべてのアラートが技術的なインシデントとして扱われるべきではありません。エージェンティックシステムの場合、少なくとも4つのカテゴリのアラートがあります。第一に、技術的インシデントです。例えば、モデルゲートウェイのダウン、ツールAPIのタイムアウト、ベクターストアの障害、レイテンシがしきい値を超えた、リトライレートの急増などです。主な所有者は通常、プラットフォームチームまたはエンジニアリングチームです。第二に、ポリシー違反です。例えば、エージェントが許可された範囲外のアクションを試みた、機密データへのアクセスがコンテキストに適合しなかった、必須の承認がスキップされた、ポリシーの不一致によりツール呼び出しが繰り返し拒否されたなどです。所有者には、セキュリティ、リスク、プロセスオーナーが含まれます。第三に、低品質です。例えば、人間による修正率の急激な上昇、未サポート回答の増加、誤分類の急増、エスカレーション率の劇的な変化などです。これは通常、プロダクトチーム、ドメインオーナー、AI運用チームによる共同レビューが必要です。第四に、コストの急増です。例えば、トランザクションあたりのトークンコストの上昇、ツール呼び出しの過剰な繰り返し、コンテキスト検索が大きすぎる、高価なモデルへのフォールバックの増加などです。エージェンティックシステムは「機能している」ように見えても、経済性が静かに悪化している可能性があるため、これは重要です。
より具体的にするために、調達インテークから発注までのエージェントのダッシュボードを想像してみてください。有用なダッシュボードは、稼働時間を表示するだけではありません。4つのパネルがあると理想的です。第1パネル、ランタイムヘルス:時間/日あたりのリクエスト量、エンドツーエンドのレイテンシ、ツールの成功/失敗率、リトライ率、リクエストあたりのトークンコスト。第2パネル、判断品質:インテーク分類の正確性、防止されたポリシー違反、人間による修正率、エスカレーション率、承認オーバーライド率。第3パネル、ビジネス成果:インテークからリクエスト作成までのサイクルタイム、タッチレス率、バックログリクエスト、SLA準拠、リクエストあたりの手戻り。第4パネル、ガバナンスと監査:拒否されたツール呼び出しのトップ、承認キューの経過時間、最も頻繁に参照されるポリシードキュメント、ツール使用の異常、調査用のトレースサンプル。このようなダッシュボードは、エンジニアリングチーム(ランタイムの健全性)、プロセスオーナー(品質と成果)、リスクおよび監査(コンプライアンスと制御の軌跡)の3つのグループすべてに同時に役立ちます。
実装上のトレードオフ:「監視モンスター」を構築しない
オブザーバビリティは非常に重要ですが、別の落とし穴があります。組織がやり過ぎて、優先順位なしにすべてをログに記録しようとすることです。結果として、ストレージコストが膨らみ、ダッシュボードがノイズで満たされ、チームはどのシグナルが重要か分からなくなり、プライバシーリスクが高まります。したがって、オブザーバビリティの設計は、リスク階層とユースケースの重要度に従う必要があります。内部ナレッジアシスタントのようなユースケースは、より軽量なロギングで十分かもしれません。逆に、返金自動化、財務例外処理、IT修復などのユースケースは、はるかに深いトレースと監査を必要とします。健全な原則は、説明責任のために十分にログを取り、意思決定のために十分に測定し、チームが実際に行動するように十分にアラートを出すことです。優れたオブザーバビリティとは、データ量が最も多いものではなく、企業がエージェントの行動を観察し、説明し、制御するのに最も役立つものです。
この記事を読んだ後、いくつかの決定を下す必要があります。第一に、本番稼働するすべてのエージェントに対するエンドツーエンドのトレース標準を決定します。企業は、トリガーからビジネス成果までのフローを、コンテキスト検索、ツール呼び出し、ポリシー判断、承認、最終アクションを含めて追跡できますか?第二に、メトリクスを技術、品質、ビジネスの3つの層に分離します。各層の所有者は誰で、それらの間の関係を読み取るためにどのダッシュボードが使用されていますか?第三に、機密データのロギングに関するポリシーを決定します。何を生のまま保存してもよく、何を編集すべきか、誰がログにアクセスできるか、保持期間はどのくらいか?第四に、アラートのカテゴリを定義します。企業はすでに、技術的インシデント、ポリシー違反、低品質、コスト急増を、異なる対応経路で区別していますか?第五に、本番環境での品質レビューのモデルを決定します。エージェントの品質は、自動評価、手動サンプリング、人間によるフィードバック、またはそれらの組み合わせのいずれによって監視されますか?
オブザーバビリティがスケールする準備ができていないことを示すいくつかの危険信号があります。エージェントはすでに行動を許可されているが、企業は基本的なチャットログしか保存していない。ツール呼び出しが、モデルの判断と同じトレースに接続されていない。エージェントが判断を下す際にどのコンテキストを使用したかを説明する方法がない。すべてのアラートが、優先順位やインシデントの種類の区別なく、1つのチャネルに送られる。チームはレイテンシと稼働時間のみを監視し、修正率やポリシー違反は監視していない。ダッシュボードは技術チームのみが使用し、プロセスオーナーやリスク機能は使用していない。ログには、適切な編集なしに機密データが豊富に含まれている。エージェントのテレメトリーとビジネスプロセスのKPIとの間に明確な関係がない。
CIO、COO、トランスフォーメーションリーダーへの内省的な問いかけです。もし明日、あなたのエージェントが誤った判断を下したが、技術的なエラーは発生しなかった場合、あなたの組織はそれを迅速に把握できますか?監査人や規制当局に対して、エージェントのアクションが最初から最後までどのように発生したかを説明できますか?現在、本番環境でのエージェントの品質メトリクスを所有しているのは誰ですか?エンジニアリング、ビジネス、それとも誰もいませんか?あなたのダッシュボードはビジネス成果を示していますか、それともインフラストラクチャの健全性だけですか?そして最も重要なことですが、あなたの企業は、エージェントの行動を規律をもって観察できるようになる前に、エージェントにより大きな自律性を与える準備が本当にできていますか?
オブザーバビリティは、システムが稼働した後の付属品ではありません。エージェンティックエンタープライズにおいて、オブザーバビリティは、自律性が制御範囲内に留まるための最低条件です。